目录
- Hystrix本系列博文
- 如何配置以及调整断路器
- 预料中的抖动和失败
- 潜在风险
- 声明
Hystrix本系列博文
以下为博主写Hystrix系列的文章列表如下:
点击查看 Hystrix入门
点击查看 Hystrix命令执行
点击查看 Hystrix处理异常机制(降级方法)
点击查看 Hystrix命令名称、分组、线程池
点击查看 Hystrix命令名称、Hystrix请求处理
点击查看 Hystrix请求处理
点击查看 Hystrix常用场景--失败
点击查看 Hystrix常用场景--降级(回退)
配置以及调整断路器
配置一个新电路的典型方法是使用自由配置(超时/线程数/信号量)发布到生产中,然后观察系统一个周期的峰值后,调整到一个更精准的配置。
在实践中典型的做法如下:
- 默认的超时时间为 1000ms ,如果确认系统超时时间高于这个值,则可以根据实际情况调整它。
- 默认的线程数为10,如果确认系统线程数高于这个值,则可以根据实际情况调整它
- 部署一个 canary ,一切顺利的话, 在整个系统运行24小时
- 通过标准的报警和监控捕获任何问题
- 24小时后,使用延迟百分比和流量来计算最低配置值,对断路器来说是有意义的。
- 在生产过程中动态更改值,并使用实时指示板监视它们,直到确信为止。
- 如果断路器的行为或性能特征发生变化,并且通过警报和(或)仪表盘监控引起警惕时,才会再次查看该断路器的配置。
下面的图代表了一个典型的思考过程,它展示了如何选择线程池、队列和执行超时(或信号量大小)的大小
 (来自官网)
(来自官网)
对于大多数断路器,应该尽量将它们的超时世间设置为接近正常健康系统的99.5% ,这样将隔离不好的请求,不让他们占用系统资源或影响用户体验。
必须对线程池和队列进行大小调整,让它们是整个应用程序资源的一小部分,否则它们将无法防止依赖于饱和的可用资源。
配置和调优断路器重要的事情如下:
- 应该在生产中基于实际的流量模式进行调优。
- 可以轻松地实时调整设置,同时监视不同设置对系统的影响。
预料中的抖动和失败
hystrix使用的是毫秒粒度的策略和报表度量, “抖动”——被视为一阵阵的超时、线程池拒绝、系统缓慢等其他类似的事情。在一个大集群系统中对于一个高容量断路器,通常这些情况发生在任何特殊时刻。 这些被Hystrix捕获的度量粒度是许多软件系统没有的,因此这些报表可能会引起不必要的担忧。
在这个生产中监视Hystrix命令的Netflix API仪表板的屏幕截图中,可以看到在243个服务器统计窗口中显示了中10秒内超时和线程池拒绝的橙色和紫色数字。
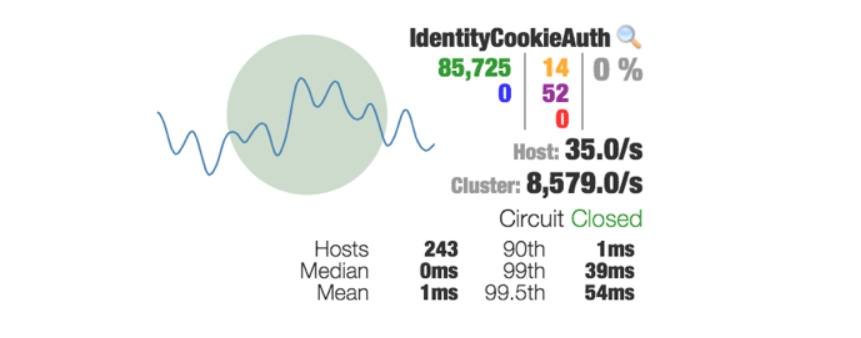
大多数系统是基于相当高的水平标准测量的——即使是每分钟完成的百分比。而且,通常是为整个应用程序请求回路所做的,并不是与之交互的单个依赖项。在Hystrix中,可以看到一个关于正在发生的事情的更精确的视图。一旦有了可以查看每个依赖项正在发生什么的放大镜,就不需要惊讶以前可能看不到的抖动。
一些案例如下:
- 客户端机器垃圾收集(机器在请求的中间进行垃圾收集)
- 服务机器垃圾收集(远程服务器在请求的中间执行垃圾收集)
- 网络问题(抖动)
- 不同请求参数的不同负载大小
- 缓存未命中
- 突发性调用情况
- 新机器启动(部署,自动伸缩事件)和“热身”
潜在风险
如果注意到超时,不要以重新配置去解决这个问题。如果一个Hystrix命令正在脱离负载,那么它就会做应该做的事情(假设在健康的时候正确地配置(请参阅上面的内容)了它)。
在早期在Netflix 采用Hystrix,一个断路器成为潜在的动态更改增加线程池,队列、超时等等属性,试着“给它一些喘息的空间“并让它再次工作。但这与应该做的恰恰相反。如果正确地为一个健康的系统配置了命令,现在出现拒绝、超时和/或短路,应该集中精力修复潜在的根本原因。
不要犯通过给命令提供更多可用的资源的错误。(在极端情况下,如果这样做的话,可以通过增加线程池、队列、超时、信号量等来对自己进行DDOS攻击)。
例如,假设有一个100台服务器集群,每个服务器有10个并发连接到一个服务,那就是:可能有1000个并发连接。健康的时候通常在任何时候使用200-300个。如果发生延迟并将它们全部备份,那么现在使用的是1000个连接。每个服务器10个对于客户端不算多,所以我们试着增加到20?最有可能的是,如果10个饱和,20个也会饱和。现在有2000个连接在后端,让事情变得更糟。
这就是断路器存在的原因之一——在底层系统上“释放压力”让它们恢复,而不是重试循环、挂起连接等方面对服务器进行更多的请求。
例如,这里有一个例子,一个依赖项经历延迟导致超时,超时时长高到断路器在大约三分之一的集群上发生故障。它是系统中唯一存在健康问题的,Hystrix则阻止它在有延迟问题的情况下获取其他资源。
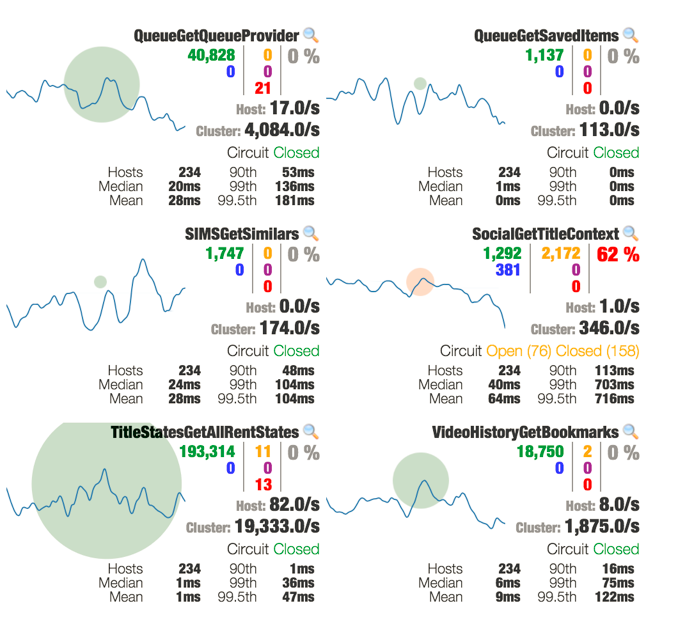
简而言之,让系统摆脱负载、短路、超时和拒绝,直到底层系统恢复健康,hystrix层将自行恢复到健康状态。Hystrix正好是为这个场景设计的,关键是要减少潜在系统的资源利用率,这样可以通过将大部分资源隔离起来以及远离那些挂在潜在连接上的资源,从而快速地恢复。
声明
转帖请注明原贴地址: https://my.oschina.net/u/2342969/blog/1820133