一、上次回顾
- https://blog.csdn.net/SparkOnYarn/article/details/105388526
- 简单回顾:基础资料、商品类别(SKU)、供应商、商家+用户、采购流程、销售 仓库 零售;库存的阈值在企业中一般是人为的设定一个值(通过数据挖掘来做的);在仓库中最重要的一点是仓库盘点,仓库的实物与系统不一定会一致(可能被偷、人为的错发),一般抽取哪个商品的进货和发货。商品单价比较高的商品也需要盘点。
二、数仓的各项理论知识
2.1、什么是数据仓库
- 数据仓库,英文名称为Data Warehouse,可简写为DW或DWH.
- 数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。
- 它是单个数据存储,出于分析性报告和决策支持目的而创建。
- 为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量及控制。
通俗的来讲:
1、一堆数据集合 数据分为两种类型:log类型(只涉及insert语句)和DB关系型(设计update、insert、delete)
2、挖掘有效价值 report报表(静态报表:web界面固定化是写死的,动态报表:数据是一份基础数据,运营人员要去看仓库每小时的订单量,又要去看仓库每天的订单量,去看仓库各个供应商每小时的供应量)、实时大屏、对其它业务系统提供指标计算(智能分单、包装方案智能推荐)、钉钉应用(如果app的话安卓、IOS的话人员开销会太大;钉钉中嵌套了h5,直接使用即可;IDS智慧决策系统)
3、提供企业决策
如果数据只有log类型的话,你应该很开心,一旦是db类型的话,复杂度要比log类型来的高;一般来说挖掘数据有效价值其实就是做报表;
如下四个指标:
a.各仓库每小时的订单量
b.各仓库每天订单量(每小时汇总)
c.各仓库各个供应商每小时的订单量
d.各仓库各个供应商每天订单量
根据a就能求得b,d又能直接根据c进行求得,底层数据只需要各个供应商每小时的订单量;
| 仓库 | 供应商 | 时间 | 时辰 | 件数 |
|---|---|---|---|---|
| B01 | 供应商1 | 2020-04-08 | 00 | 1000 |
| B01 | 供应商1 | 2020-04-08 | 01 | 1500 |
| B01 | 供应商1 | 2020-04-08 | 02 | 2000 |
| B01 | 供应商1 | 2020-04-08 | 03 | 3000 |
一般只存储最小粒度的多维汇总数据。动态报表的说法是上钻下钻,比如计算仓库每天的订单量,仓库每月的订单量,仓库各个供应商的每月的订单量;会自动拼接 sql --》 group by做汇总。
根据时间维度可以进行的计算:年、月、日、季度、上旬、中旬、下旬;
静态报表&&动态报表:
- 静态报表就是存4张表,写死;动态报表要求一份维度最多,粒度最小的报表,然后再去做group by语句;J哥生产数据存储到ES中;根据业务需求后期动态报表可以转静态报表;静态报表只需要select,动态报表需要做group by语句。
以挖掘有效价值中的智能分单为例:
- 比如收获地址是上海,会根据用户地址进行解析,把这一单分给最近的仓库的同时判断仓库有无货物,人工进行拣货再复核进行打包,打包后扫描,放到呆出库区;
- 包装方案智能推荐是会根据货物体积大小来制定打包盒的,比如买个老母鸡,根据历史数据计算模型,再根据当前数据计算模型,发一个多大的箱子,要计算放多少干冰。
数据集市(是数仓的一个子集),也可以理解为数仓是由多个数据集市组装而成;
数据集市(Data Mart) ,也叫数据市场,数据集市就是满足特定的部门或者用户的需求,按照多维的方式进行存储,包括定义维度、需要计算的指标、维度的层次等,生成面向决策分析需求的数据立方体。
从范围上来说,数据是从企业范围的数据库、数据仓库,或者是更加专业的数据仓库中抽取出来的。数据中心的重点就在于它迎合了专业用户群体的特殊需求,在分析、内容、表现,以及易用方面。数据中心的用户希望数据是由他们熟悉的术语表现的。
数仓指的是所有的数据都需要挖掘分析,数据集市比如说我们只分析采购部门的。
| 数据仓库 | 数据集市 |
|---|---|
| 企业级别 | 部门级别 |
| 大量的全的数据 | 仅涉及自己部分的数据 |
没有数仓,谈何数据中台,把数据仓库做好就可以了;
2.2、数仓分层
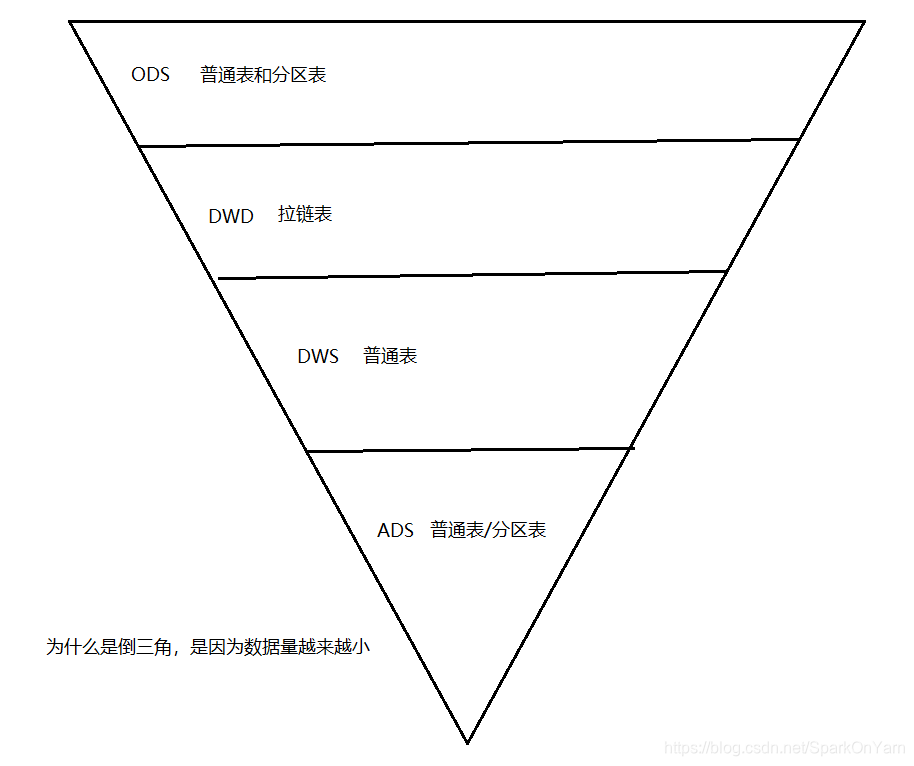
1、ODS(operation data store)原始数据层 存放原始数据,不做任何的处理;拉链表
2、DWD/DWI(data warehouse detail)结构和粒度与ODS层是一致的,只做对ODS层数据进行清洗(脏数据、空值进行清洗)
3、DWS(data warehouse service)以DWD层为基础,进行轻度汇总,一般是做一个宽表,在这一层只做一个join,DWS的结果是DWD层的数据多张表进行join的结果,有少量可以使用group by;
4、ADS/APP/domain(application data store)这一层指的是按主题提供统计数据,一般的都是基于DWS层的宽表进行group by计算,有少量可能做join计算(取决于宽表没有你想要的字段)
- 比如要求各个宽表第一品类的数据,就需要join这张表:
- 在生产上,ADS层的分区表建议使用外部表,这样万一删除了表,数据还是在的
DWD层是否要清洗主要取决于上游系统,一般ODS的数据流转到DWD层,这两份数据是一样的;这是一个比较标准的数据划分层次。
ODS层还涉及到拉链表,通过startday和endday来控制。DWS层的宽表需要围绕一个主题比如说是订单(那就需要订单有关信息来进行操作);
2.3、使用Dbeaver连接HiveServer2
- 等待补充
2.4、数据质量如何保证(上游–>下游)
行转列、列转行、window里面求topN,MySQL中的业务场景基本就这几个;
- 从零开始的数仓项目成长是最多,你进入的公司分层做好了,各种业务分析的指标都已经建立好了,那你进去就是写SQL,就能认为是数仓工程师;数据建模建模,说白了就是建表,根据指标写SQL;
上游到下游的数据质量如何保证,MySQL --> Hive抽取过程中是否会有数据丢失呢,SQOOP、DataX,比如Sqoop抽取oracle数据到Hive,但是Sqoop并没有进行error抛错,
2.5、命名规范(类比MySQL的命名规范)
表的前缀:ods、dwd、dws、ads,在dwd层的时候,表的前缀可能会出现fact(事实表)、dim(维表);
对于同一个含义的字段名称,在dws层的个表设计需要进行统一,以订单号为例:在a表中叫orderno、b表中叫orederid、c表中叫id,统一为orderno;又以创建时间为例:ctime、cre_time、createtime、create_time;统一为create_time;
2.6、为什么要做数仓分层
为什么不能直接使用ODS层和ADS层呢,去除DWD层和DWS层?
注意:每一家公司的命名和叫法可以不一样,只要功能使用上一样就行了
1、复杂问题简单化:将一个超级复杂的任务进行分解成多个步骤来完成,每一层只处理单一的步骤,比较简单(比如第二层做数据清洗,第三层数据join,第四层数据group by);
2、减少重复开发,通过中间层的数据,能够减少重复计算,能够增加一次计算的复用性;
3、能够隔离原始数据,在做业务开发的时候,每一层表都是有权限的,比如在从ODS层数据到DWD层数据的时候,手机号码、银行卡号、家庭地址那栏需要做脱敏处理;DWD层的表是有权限控制的,我们新进入一家公司,我们只能够访问到DWS层的数据,比如手机号查看到的就是138XXXXXXXX;
ODS层的数据是从MySQL原封不动的流转过来的,J哥公司脱敏已经在MySQL层做好了;数据直接接收即可。
隔离原始数据:数据的敏感,使得真实的数据和统计的数据相分离。
数据仓库的分层也不是越多越好的,合理的层次设计,以及计算成本和人力成本的平衡,是一个好的数仓架构的表现。
有些公司数仓分层5层 6层 7层也不要觉得惊讶,4层是一个很经典的架构,存在即合理,当时的分层处理符合当时的业务需求。
三、ERP订单主表&&明细表设计案例
- 数据如下所示:
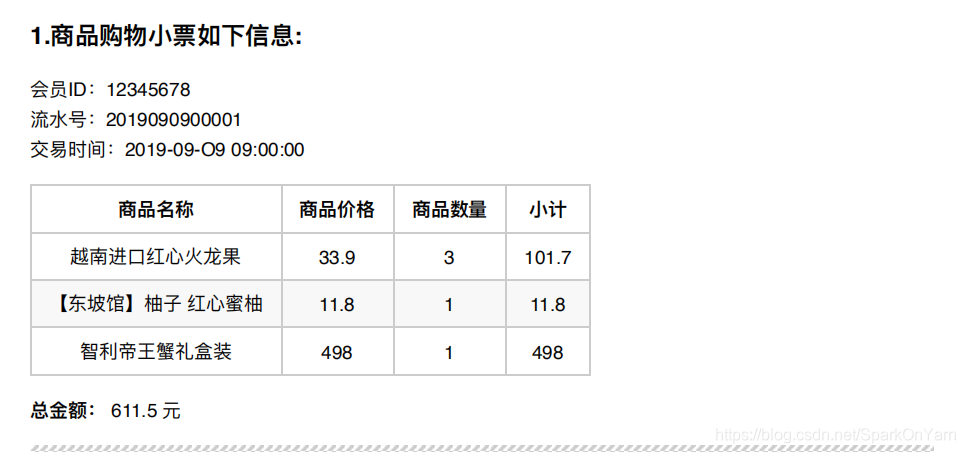
初级程序员的设计:order订单表
| 订单号 | 会员ID | 交易时间 | 商品名称 | 商品价格 | 商品数量 | 小计 | 总金额 |
|---|---|---|---|---|---|---|---|
| 2019090900001 | 12345678 | 2019-09-O9 09:00:00 | 越南进⼝红⼼⽕⻰果 | 33.9 | 3 | 101.7 | 611.5 |
| 2019090900001 | 12345678 | 2019-09-O9 09:00:00 | 【东坡馆】柚⼦ 红⼼蜜柚 | 11.8 | 1 | 11.8 | 611.5 |
| 2019090900001 | 12345678 | 2019-09-O9 09:00:00 | 智利帝王蟹礼盒装 | 498 | 1 | 498 | 611.5 |
维护的数据过于冗余
中级程序员设计:order订单主表、订单明细表orderitems
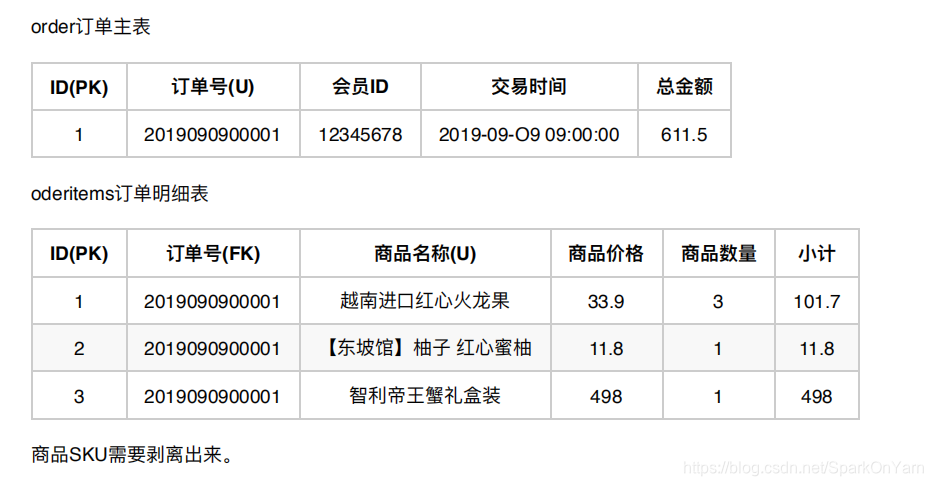
高级程序员设计成3张表:order订单主表、orderitems订单明细表、sku商品表:
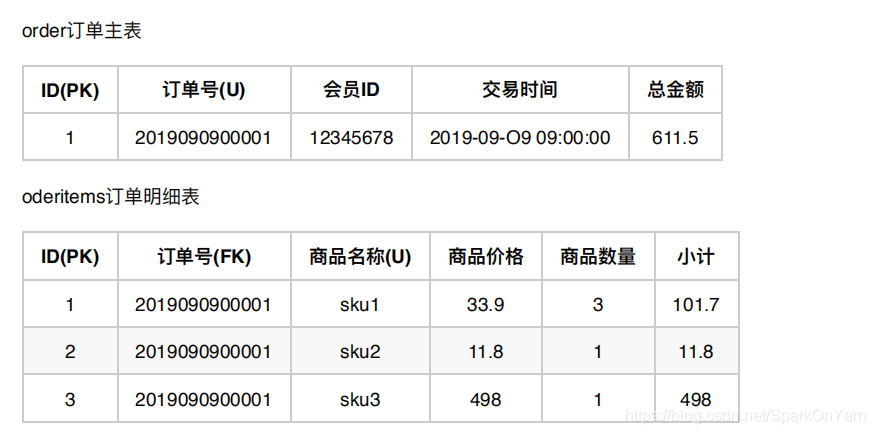

关于SKU这张表可以做很多维度的计算统计,一级类别、二级类别;每份商品的差价;
扩展:
1、假如是电商平台,⽐如京东⽣鲜购买。那么order订单主表,额外增加字段: 收货⼈ID,订单的状态(1未付款,2已付款未发货,3已发货没收货,4签收)即可。
2、额外增加⼀张收货⼈receiver表:收货⼈ID、收货⼈姓名、⼿机、省、市、区、县、详细地址的字段
3、额外增加⼀张物流表,记录订单流转到哪⾥及当前状态,那么请问如何设计呢?
- 这张物流表是只有insert的,每一个状态都是直接进行插入的
4、为什么有些表需要增加额外的⾃增⻓主键ID ?
总结:
商品全表
–>
订单主表、订单明细表
–>
订单主表、订单明细表、商品表 第三种肯定是应用在生产上的,上游MySQL的设计就是这样(还能更细化,商品一级类别、二级类别)
在MySQL中(orderinfo、orderitems) --> hive ods层+dwd层 (orderinfo、orderitems) --> hive dws层(在dws层需要join成一张大宽表)
so有一句话:天下分分合合、合合分分;无论是上游mysql(分)还是下游hive(dws层就是合),就是分分合合的一种状态
