文章目录
0.前言
之前我们简要介绍了Keras与Tensorflow的一些基本用法,主要是了解整个深度学习框架的执行,这样我们就可以复现出别人的模型,拿到别人的模型就可以跑了,甚至做一些简单的改动。但是,如果想有一些创新,不会自定义层可谓是巧妇难为无米之炊,没有趁手的武器,再高的武功也不行。
1. 层
我们都知道,深度学习曾经是计算图模型,讲究的是计算节点(Node)以及计算流的结合体。后来随着Keras的进一步封装,计算图模型则是以层和层之间的链接构成,可以说,层是模型下面一个级别,模型可以包含多个模型组成,也可以由多个层组成。以现在来看,层是我们可以操作的最小逻辑单位(底层的数学变换),我们这里以激活函数为例,激活函数基本上是一个无需参数的函数变换,从下文中也可以看到。
class Activation(Layer):
"""Applies an activation function to an output.
# Arguments
activation: 激活函数名(Relu,Softmax等)
# Input shape
Arbitrary. Use the keyword argument `input_shape`
(tuple of integers, does not include the samples axis)
when using this layer as the first layer in a model.
# Output shape
Same shape as input.
"""
#初始化函数
def __init__(self, activation, **kwargs):
super(Activation, self).__init__(**kwargs)#一定要写
self.supports_masking = True
self.activation = activations.get(activation)
#本质就是Output=Function(Input)
def call(self, inputs):
return self.activation(inputs)
def get_config(self):
config = {'activation': activations.serialize(self.activation)}
base_config = super(Activation, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
#计算输出维度,如果输入输出一致,就这么写即可
def compute_output_shape(self, input_shape):
return input_shape
从这个简单的激活层函数中,我们可以管中窥豹,看到这个层“麻雀虽小五脏俱全”,为我们展示了一个层的基本特征:
- 继承Layer
__init__初始化函数call具体运算get_config获取该层的参数compute_output_shape自动计算维度
我们常见的全连接层(Dense),卷积层(CNN),长短时记忆网络层(LSTM)等都是Keras集成好的层,和上述的激活函数一样,只不过更加复杂,通过他们的代码我们可以学习到一个层该如何编写,然后在下面一节,我们将讲述如何编写自定义层。
1.1 python语法背景知识
这里首先介绍一些接下来将要使用的python装饰器和魔法函数及其作用,方便下面的讲解。
装饰器:
@property让类函数能像类变量一样操作@interfaces.legacy_xxx_support让函数支持keras 1.x的 API@classmothod类函数,属于整个类,类似于C++/JAVA中的静态函数。类方法有类变量cls传入,从而可以用cls做一些相关的处理。子类继承时,调用该类方法时,传入的类变量cls是子类,而非父类。既可以在类内部使用self访问,也可以通过实例、类名访问。@staticmethod将外部函数集成到类体中,既可以在类内部使用self访问,也可以通过实例、类名访问。基本上等同于一个全局函数。
魔法函数:
__call__让类的实例可以像函数一样调用,正是python的这种特性让我们可以像这样进行层之间的连接:
inputs = Input(shape=(784,))
# 前面的Dense(64, activation='relu')生成了类Dense的一个实例
# 后面的(input)将调用类Dense的__call__函数
x = Dense(64, activation='relu')(inputs)
InputSpec: 确定层的ndim,dtype,shape,每一层都应有一个input_spec属性,保存InputSpec的实例的list(每一个输入tensor都对应一个)
1.2 全连接层(Dense)
class Dense(Layer):
"""
### 层的定义描述
# Example
### 例子使用
# Arguments
### 参数说明
# Input shape
nD tensor with shape: `(batch_size, ..., input_dim)`.
The most common situation would be
a 2D input with shape `(batch_size, input_dim)`.
# Output shape
nD tensor with shape: `(batch_size, ..., units)`.
For instance, for a 2D input with shape `(batch_size, input_dim)`,
the output would have shape `(batch_size, units)`.
"""
@interfaces.legacy_dense_support # 让函数支持keras 1.x的 API
def __init__(self, units,
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs):
if 'input_shape' not in kwargs and 'input_dim' in kwargs:
kwargs['input_shape'] = (kwargs.pop('input_dim'),)
super(Dense, self).__init__(**kwargs)#这一行要有,会省去一些麻烦
#全是各种参数配置
self.units = units
self.activation = activations.get(activation)
### 全是其他参数配置
self.input_spec = InputSpec(min_ndim=2)
self.supports_masking = True
#注意点1:创建可训练的参数
def build(self, input_shape):
assert len(input_shape) >= 2
input_dim = input_shape[-1]
#注意点2:可训练的参数
self.kernel = self.add_weight(shape=(input_dim, self.units),
initializer=self.kernel_initializer,
name='kernel',
regularizer=self.kernel_regularizer,
constraint=self.kernel_constraint)
if self.use_bias:
self.bias = self.add_weight(shape=(self.units,),
initializer=self.bias_initializer,
name='bias',
regularizer=self.bias_regularizer,
constraint=self.bias_constraint)
else:
self.bias = None
self.input_spec = InputSpec(min_ndim=2, axes={-1: input_dim})
self.built = True #设置为真
#注意点3:当我们使用该类创建完一个示例后,实例名()就是在调用Call里的函数
def call(self, inputs):
output = K.dot(inputs, self.kernel)
if self.use_bias:
output = K.bias_add(output, self.bias, data_format='channels_last')
if self.activation is not None:#是否使用激活函数
output = self.activation(output)
return output
#注意点4:计算输出的形状的,下面例子为Dense的维度变换
def compute_output_shape(self, input_shape):
assert input_shape and len(input_shape) >= 2
assert input_shape[-1]
output_shape = list(input_shape)#继承输入的形状
output_shape[-1] = self.units #改变最后一维为当前单元数
return tuple(output_shape)
#注意点5:可以使用config获取该类信息
def get_config(self):
config = {
'units': self.units,
'activation': activations.serialize(self.activation),
###配置信息,省略
}
base_config = super(Dense, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
在上面代码中,需要重点关注以下函数,我在源码中都已经标注:
build
用来创建当前层的weights,子类必须实现。add_weight
每层的参数通过这个函数来设定。call / __call__
call是最重要的函数,它用于实现层的功能,子类必须实现。
魔法函数 call 会将收到的输入传递给 call 函数,然后调用 call 函数实现具体的功能。comput_output_shape
根据input_shape 计算输出的shape,子类必须实现。用于自动推断下一层的输入尺寸。get_config / from_config
get_config 返回一个字典,获取当前层的参数信息。
from_config 使用根据参数生成一个新的层。代码只有一行:
@classmethod
def from_config(cls, config):
return cls(**config)
可见from_config是一个classmethod,根据传入的参数,使用当前类的构造函数来生成一个实例。通过子类调用时,cls是子类而不是基类Layer。
1.3 卷积层(CNN)
卷积层就是一个加权平均的过程,具体的使用可以参考《CNN的使用》。令人神奇的是,Keras自己并没有实现核心代码,下面是Keras的卷积层的基类代码
class _Conv(Layer):
"""Abstract nD convolution layer (private, used as implementation base).
### 函数说明
# Arguments
rank: An integer, the rank of the convolution,
e.g. "2" for 2D convolution.
filters: Integer, the dimensionality of the output space
(i.e. the number of output filters in the convolution).
kernel_size: An integer or tuple/list of n integers, specifying the
dimensions of the convolution window.
#### 参数注释
"""
def __init__(self, rank,
filters,
kernel_size,
strides=1,
padding='valid',
data_format=None,
dilation_rate=1,
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs):
super(_Conv, self).__init__(**kwargs)
self.rank = rank
self.filters = filters
self.kernel_size = conv_utils.normalize_tuple(kernel_size, rank,
'kernel_size')
self.strides = conv_utils.normalize_tuple(strides, rank, 'strides')
self.padding = conv_utils.normalize_padding(padding)
### 初始化参数
def build(self, input_shape):
if self.data_format == 'channels_first':
channel_axis = 1
else:
channel_axis = -1
if input_shape[channel_axis] is None:
raise ValueError('The channel dimension of the inputs '
'should be defined. Found `None`.')
input_dim = input_shape[channel_axis]
kernel_shape = self.kernel_size + (input_dim, self.filters)
#可学习参数
self.kernel = self.add_weight(shape=kernel_shape,
initializer=self.kernel_initializer,
name='kernel',
regularizer=self.kernel_regularizer,
constraint=self.kernel_constraint)
if self.use_bias:
self.bias = self.add_weight(shape=(self.filters,),
initializer=self.bias_initializer,
name='bias',
regularizer=self.bias_regularizer,
constraint=self.bias_constraint)
else:
self.bias = None
# Set input spec.ndim=卷积维度+批次(1)+未卷积维度(1)
self.input_spec = InputSpec(ndim=self.rank + 2,
axes={channel_axis: input_dim})
self.built = True
def call(self, inputs):
#重点在这,输出是使用后端K进行的卷积操作
if self.rank == 1:
outputs = K.conv1d(
inputs,
self.kernel,
strides=self.strides[0],
padding=self.padding,
data_format=self.data_format,
dilation_rate=self.dilation_rate[0])
if self.rank == 2:
outputs = K.conv2d(
inputs,
self.kernel,
strides=self.strides,
padding=self.padding,
data_format=self.data_format,
dilation_rate=self.dilation_rate)
if self.rank == 3:
outputs = K.conv3d(
inputs,
self.kernel,
strides=self.strides,
padding=self.padding,
data_format=self.data_format,
dilation_rate=self.dilation_rate)
if self.use_bias:
outputs = K.bias_add(
outputs,
self.bias,
data_format=self.data_format)
if self.activation is not None:
return self.activation(outputs)
return outputs
def compute_output_shape(self, input_shape):
### 计算输出维度
def get_config(self):
config = {
'rank': self.rank,
'filters': self.filters,
'kernel_size': self.kernel_size,
'strides': self.strides,
### 参数说明
}
base_config = super(_Conv, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
这里可以看到,它在call里使用的是一个后端的conv1d函数,而这个函数在Keras里并没有显式的给出,我们追溯了Tensorflow和CNTK等后端发现,它们实现这个函数时,同样是封装好的,并看不到最终源码。不过我们也知道卷积只是局部的加权求和过程,因此也能够手动实现。我们这里更想强调的是如何将公式和代码相结合,以便于后来的自定义层的编写。
1.4 循环层(RNN)
相比较CNN,RNN就友善的许多,其中两个比较著名的层SimpleRNN和LSTM都有相关的代码,我们下面来解析一下。
1.4.1 SimpleRNN
SimpleRNN就是正统的RNN,它就是最简单的循环层,首先看一下图示:
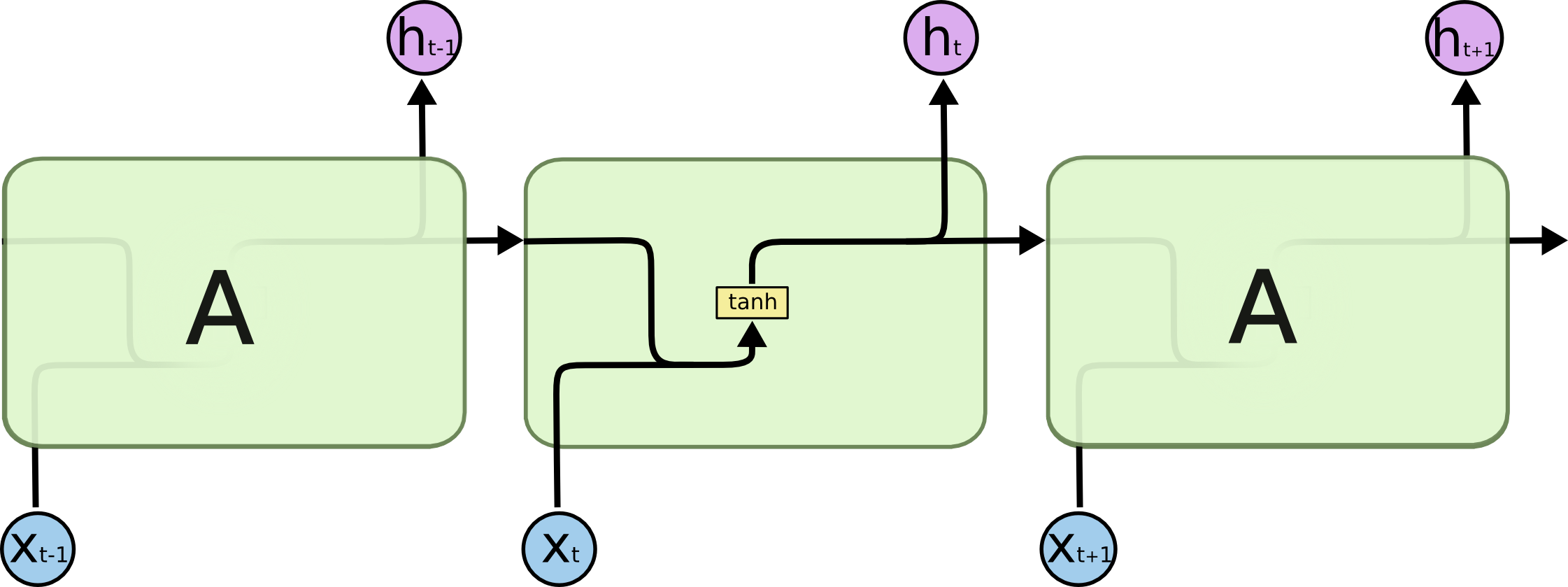
再看一下其数学公式表达为:
它的当前步的输出结合了当前步的输入以及上一步的输出,我们下面看一下源码是如何实现的。
class SimpleRNNCell(Layer):
"""Cell class for SimpleRNN.
# Arguments
units: Positive integer, dimensionality of the output space.
### 参数说明
"""
def __init__(self, units,
activation='tanh',
use_bias=True,
kernel_initializer='glorot_uniform',
recurrent_initializer='orthogonal',
bias_initializer='zeros',
kernel_regularizer=None,
recurrent_regularizer=None,
bias_regularizer=None,
kernel_constraint=None,
recurrent_constraint=None,
bias_constraint=None,
dropout=0.,
recurrent_dropout=0.,
**kwargs):
super(SimpleRNNCell, self).__init__(**kwargs)
self.units = units
### 初始化参数
def build(self, input_shape):
### 两个学习变量
self.kernel = self.add_weight(shape=(input_shape[-1], self.units),
name='kernel',
initializer=self.kernel_initializer,
regularizer=self.kernel_regularizer,
constraint=self.kernel_constraint)
self.recurrent_kernel = self.add_weight(
shape=(self.units, self.units),
name='recurrent_kernel',
initializer=self.recurrent_initializer,
regularizer=self.recurrent_regularizer,
constraint=self.recurrent_constraint)
if self.use_bias:
self.bias = self.add_weight(shape=(self.units,),
name='bias',
initializer=self.bias_initializer,
regularizer=self.bias_regularizer,
constraint=self.bias_constraint)
else:
self.bias = None
self.built = True
def call(self, inputs, states, training=None):
prev_output = states[0]
if 0 < self.dropout < 1 and self._dropout_mask is None:
self._dropout_mask = _generate_dropout_mask(
K.ones_like(inputs),
self.dropout,
training=training)
if (0 < self.recurrent_dropout < 1 and
self._recurrent_dropout_mask is None):
self._recurrent_dropout_mask = _generate_dropout_mask(
K.ones_like(prev_output),
self.recurrent_dropout,
training=training)
dp_mask = self._dropout_mask
rec_dp_mask = self._recurrent_dropout_mask
### 计算的重点来了
if dp_mask is not None:
h = K.dot(inputs * dp_mask, self.kernel)
else:
#h_t=x_t*W_x
h = K.dot(inputs, self.kernel)
if self.bias is not None:
h = K.bias_add(h, self.bias)
if rec_dp_mask is not None:
prev_output *= rec_dp_mask
# o_t=x_t*W_x+o_t-1*W_h
output = h + K.dot(prev_output, self.recurrent_kernel)
if self.activation is not None:
output = self.activation(output)
# Properly set learning phase on output tensor.
if 0 < self.dropout + self.recurrent_dropout:
if training is None:
output._uses_learning_phase = True
return output, [output]
def get_config(self):
###返回参数配置
1.4.2 GRU
门控循环神经网络(GRU)是另一个常用的循环层,它比SimpleRNN稍微复杂一些,其图解如下:
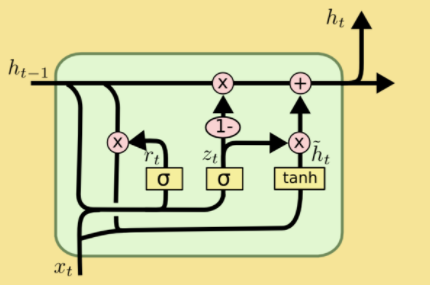
我们接着看一看它的公式:
这四行公式解释如下:
是 update gate,即决定当前步信息和上一步信息的取舍比例
是 reset gate,即决定上一步骤信息要哪些
这是当前步信息
是 activation,是 GRU 的隐层,接收
这是当前步最后传递出的信息
class GRUCell(LayerRNNCell):
"""Gated Recurrent Unit cell (cf. http://arxiv.org/abs/1406.1078).
Note that this cell is not optimized for performance. Please use
`tf.contrib.cudnn_rnn.CudnnGRU` for better performance on GPU, or
`tf.contrib.rnn.GRUBlockCellV2` for better performance on CPU.
Args:
num_units: int, The number of units in the GRU cell.
activation: Nonlinearity to use. Default: `tanh`.
###参数说明
"""
@deprecated(None, "This class is equivalent as tf.keras.layers.GRUCell,"
" and will be replaced by that in Tensorflow 2.0.")
def __init__(self,
num_units,
activation=None,
reuse=None,
kernel_initializer=None,
bias_initializer=None,
name=None,
dtype=None,
**kwargs):
super(GRUCell, self).__init__(
_reuse=reuse, name=name, dtype=dtype, **kwargs)
if context.executing_eagerly() and context.num_gpus() > 0:
logging.warn("%s: Note that this cell is not optimized for performance. "
"Please use tf.contrib.cudnn_rnn.CudnnGRU for better "
"performance on GPU.", self)
### 初始化参数
@property
def state_size(self):
return self._num_units
@property
def output_size(self):
return self._num_units
@tf_utils.shape_type_conversion
def build(self, inputs_shape):
if inputs_shape[-1] is None:
raise ValueError("Expected inputs.shape[-1] to be known, saw shape: %s"
% str(inputs_shape))
input_depth = inputs_shape[-1]
# 1个可学习变量
self._gate_kernel = self.add_variable(
"gates/%s" % _WEIGHTS_VARIABLE_NAME,
shape=[input_depth + self._num_units, 2 * self._num_units],
initializer=self._kernel_initializer)
self._gate_bias = self.add_variable(
"gates/%s" % _BIAS_VARIABLE_NAME,
shape=[2 * self._num_units],
initializer=(
self._bias_initializer
if self._bias_initializer is not None
else init_ops.constant_initializer(1.0, dtype=self.dtype)))
# 2个可学习变量
self._candidate_kernel = self.add_variable(
"candidate/%s" % _WEIGHTS_VARIABLE_NAME,
shape=[input_depth + self._num_units, self._num_units],
initializer=self._kernel_initializer)
self._candidate_bias = self.add_variable(
"candidate/%s" % _BIAS_VARIABLE_NAME,
shape=[self._num_units],
initializer=(
self._bias_initializer
if self._bias_initializer is not None
else init_ops.zeros_initializer(dtype=self.dtype)))
self.built = True
def call(self, inputs, state):
"""Gated recurrent unit (GRU) with nunits cells."""
##重点来了
##操作1
gate_inputs = math_ops.matmul(
array_ops.concat([inputs, state], 1), self._gate_kernel)
gate_inputs = nn_ops.bias_add(gate_inputs, self._gate_bias)
value = math_ops.sigmoid(gate_inputs)
r, u = array_ops.split(value=value, num_or_size_splits=2, axis=1)
#操作2
r_state = r * state
#操作3
candidate = math_ops.matmul(
array_ops.concat([inputs, r_state], 1), self._candidate_kernel)
candidate = nn_ops.bias_add(candidate, self._candidate_bias)
c = self._activation(candidate)
#操作4
new_h = u * state + (1 - u) * c
return new_h, new_h
def get_config(self):
config = {
"num_units": self._num_units,
"kernel_initializer": initializers.serialize(self._kernel_initializer),
"bias_initializer": initializers.serialize(self._bias_initializer),
"activation": activations.serialize(self._activation),
"reuse": self._reuse,
}
base_config = super(GRUCell, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
这里的GRU的代码好像和公式不对应,可学习变量只有2个(公式里有6个),式子也不是4个?其实是对应的,不过它做了非常巧妙的运算。
- 在操作1中,将 和 同时计算了,然后再拆分出z(代码中的u)和r。
- 在操作2中计算了r的变换,这里state就是 。
- 在操作3中执行了公式 。
- 在操作4中执行了公式
整体来看都是一一对应的,而Tensorflow这边将变量默认是张量也是有意义的,在数学计算时是什么,在公式里就是什么样,非常的方便。
其实也发现这个代码好像是Tensorflow风格的,并不是Keras的风格。
1.4.2 LSTM
LSTM是最常用的循环层了,它的核心在于LSTM-Cell层,首先我们看一下图示:
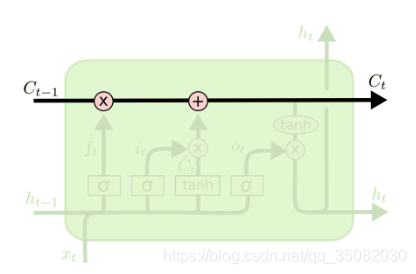
图里其他部分不太清楚,是因为我从《详解LSTM》中没找到像RNN和GRU一样又完整有清晰的图,其次我们来看一下公式:
下面是它的核心代码:
class LSTMCell(Layer):
"""Cell class for the LSTM layer.
# Arguments
units: Positive integer, dimensionality of the output space.
### 参数说明
"""
def __init__(self, units,
activation='tanh',
recurrent_activation='hard_sigmoid',
use_bias=True,
kernel_initializer='glorot_uniform',
recurrent_initializer='orthogonal',
bias_initializer='zeros',
unit_forget_bias=True,
kernel_regularizer=None,
recurrent_regularizer=None,
bias_regularizer=None,
kernel_constraint=None,
recurrent_constraint=None,
bias_constraint=None,
dropout=0.,
recurrent_dropout=0.,
implementation=1,
**kwargs):
super(LSTMCell, self).__init__(**kwargs)
self.units = units
###初始化参数
def build(self, input_shape):
input_dim = input_shape[-1]
if type(self.recurrent_initializer).__name__ == 'Identity':
def recurrent_identity(shape, gain=1., dtype=None):
del dtype
return gain * np.concatenate(
[np.identity(shape[0])] * (shape[1] // shape[0]), axis=1)
self.recurrent_initializer = recurrent_identity
###仍然是只有两个可学习参数
self.kernel = self.add_weight(shape=(input_dim, self.units * 4),
name='kernel',
initializer=self.kernel_initializer,
regularizer=self.kernel_regularizer,
constraint=self.kernel_constraint)
self.recurrent_kernel = self.add_weight(
shape=(self.units, self.units * 4),
name='recurrent_kernel',
initializer=self.recurrent_initializer,
regularizer=self.recurrent_regularizer,
constraint=self.recurrent_constraint)
if self.use_bias:
if self.unit_forget_bias:
def bias_initializer(_, *args, **kwargs):
return K.concatenate([
self.bias_initializer((self.units,), *args, **kwargs),
initializers.Ones()((self.units,), *args, **kwargs),
self.bias_initializer((self.units * 2,), *args, **kwargs),
])
else:
bias_initializer = self.bias_initializer
self.bias = self.add_weight(shape=(self.units * 4,),
name='bias',
initializer=bias_initializer,
regularizer=self.bias_regularizer,
constraint=self.bias_constraint)
else:
self.bias = None
#不同参数在于可学习参数的位置不同
self.kernel_i = self.kernel[:, :self.units]
self.kernel_f = self.kernel[:, self.units: self.units * 2]
self.kernel_c = self.kernel[:, self.units * 2: self.units * 3]
self.kernel_o = self.kernel[:, self.units * 3:]
self.recurrent_kernel_i = self.recurrent_kernel[:, :self.units]
self.recurrent_kernel_f = (
self.recurrent_kernel[:, self.units: self.units * 2])
self.recurrent_kernel_c = (
self.recurrent_kernel[:, self.units * 2: self.units * 3])
self.recurrent_kernel_o = self.recurrent_kernel[:, self.units * 3:]
if self.use_bias:
self.bias_i = self.bias[:self.units]
self.bias_f = self.bias[self.units: self.units * 2]
self.bias_c = self.bias[self.units * 2: self.units * 3]
self.bias_o = self.bias[self.units * 3:]
else:
self.bias_i = None
self.bias_f = None
self.bias_c = None
self.bias_o = None
self.built = True
def call(self, inputs, states, training=None):
if 0 < self.dropout < 1 and self._dropout_mask is None:
self._dropout_mask = _generate_dropout_mask(
K.ones_like(inputs),
self.dropout,
training=training,
count=4)
if (0 < self.recurrent_dropout < 1 and
self._recurrent_dropout_mask is None):
self._recurrent_dropout_mask = _generate_dropout_mask(
K.ones_like(states[0]),
self.recurrent_dropout,
training=training,
count=4)
# dropout matrices for input units
dp_mask = self._dropout_mask
# dropout matrices for recurrent units
rec_dp_mask = self._recurrent_dropout_mask
h_tm1 = states[0] # previous memory state
c_tm1 = states[1] # previous carry state
if self.implementation == 1:
if 0 < self.dropout < 1.:
inputs_i = inputs * dp_mask[0]
inputs_f = inputs * dp_mask[1]
inputs_c = inputs * dp_mask[2]
inputs_o = inputs * dp_mask[3]
else:
inputs_i = inputs
inputs_f = inputs
inputs_c = inputs
inputs_o = inputs
#操作1
x_i = K.dot(inputs_i, self.kernel_i)
x_f = K.dot(inputs_f, self.kernel_f)
x_c = K.dot(inputs_c, self.kernel_c)
x_o = K.dot(inputs_o, self.kernel_o)
if self.use_bias:
x_i = K.bias_add(x_i, self.bias_i)
x_f = K.bias_add(x_f, self.bias_f)
x_c = K.bias_add(x_c, self.bias_c)
x_o = K.bias_add(x_o, self.bias_o)
if 0 < self.recurrent_dropout < 1.:
h_tm1_i = h_tm1 * rec_dp_mask[0]
h_tm1_f = h_tm1 * rec_dp_mask[1]
h_tm1_c = h_tm1 * rec_dp_mask[2]
h_tm1_o = h_tm1 * rec_dp_mask[3]
else:
h_tm1_i = h_tm1
h_tm1_f = h_tm1
h_tm1_c = h_tm1
h_tm1_o = h_tm1
#操作2
i = self.recurrent_activation(x_i + K.dot(h_tm1_i,
self.recurrent_kernel_i))
f = self.recurrent_activation(x_f + K.dot(h_tm1_f,
self.recurrent_kernel_f))
c = f * c_tm1 + i * self.activation(x_c + K.dot(h_tm1_c,
self.recurrent_kernel_c))
o = self.recurrent_activation(x_o + K.dot(h_tm1_o,
self.recurrent_kernel_o))
else:
if 0. < self.dropout < 1.:
inputs *= dp_mask[0]
z = K.dot(inputs, self.kernel)
if 0. < self.recurrent_dropout < 1.:
h_tm1 *= rec_dp_mask[0]
z += K.dot(h_tm1, self.recurrent_kernel)
if self.use_bias:
z = K.bias_add(z, self.bias)
z0 = z[:, :self.units]
z1 = z[:, self.units: 2 * self.units]
z2 = z[:, 2 * self.units: 3 * self.units]
z3 = z[:, 3 * self.units:]
i = self.recurrent_activation(z0)
f = self.recurrent_activation(z1)
c = f * c_tm1 + i * self.activation(z2)
o = self.recurrent_activation(z3)
#操作3
h = o * self.activation(c)
if 0 < self.dropout + self.recurrent_dropout:
if training is None:
h._uses_learning_phase = True
return h, [h, c]
def get_config(self):
### 获得参数
这里代码也对于原公式进行了一些修改,其中2个可学习参数分别代表W和U。
操作1计算了以下公式中的Wx+b的部分:
操作2则补全了公式中的Uh部分
操作3则是实现了最后一步
1.5 小结
通过以上几个Keras源码的解析,让我们熟悉了公式和真正代码之间是如何建立起映射关系的,为我们接下来自定义层打下基础,值得注意的是2件事,一、以上代码具有时效性,将来会被tensorflow 2.0取代一部分;二、以上代码仅供理解和学习使用,没有进行任何CUDA的优化,优化模块不是此写法。
2. 自定义层
自定义层都是为了自己的公式而实现的层,从丰满程度上确实不如官方层,普适性也不高,因此不会像官方层一样拖着很多参数和判断,下面提供两个简单的层的样例,当做是抛砖引玉,以后我们会介绍更多数学公式转换而来的层。
2.1 MyDense层
这里实现的是全连接层,即y=xw+b的张量化版本。相比较官方的Dense层,这个代码简单了许多,当然也有很多局限性了。
# import tensorflow as tf
# import tensorflow.keras as keras
class MyDense(layers.Layer):
def __init__(self, units=32):
super(MyDense, self).__init__()
self.units = units
def build(self, input_shape):
self.w = self.add_weight(shape=(input_shape[-1], self.units),
initializer='random_normal',
trainable=True)
self.b = self.add_weight(shape=(self.units,),
initializer='random_normal',
trainable=True)
def call(self, inputs):
#简单核心:y=xw+b,返回32大小
return tf.matmul(inputs, self.w) + self.b
def get_config(self):
return {'units': self.units}
#这是新添加的函数,从官方Dense层中获取的。
def compute_output_shape(self, input_shape):
assert input_shape and len(input_shape) >= 2
assert input_shape[-1]
output_shape = list(input_shape)#继承输入的形状
output_shape[-1] = self.units #改变最后一维为当前单元数
return tuple(output_shape)
inputs = keras.Input((4,))
outputs = MyDense(10)(inputs)
model = keras.Model(inputs, outputs)
config = model.get_config()
new_model = keras.Model.from_config(
#在调用时需要使用自定义对象定义才行
config, custom_objects={'MyDense':MyDense}
)
2.2 MyRNN层
这里使用自定义的RNN更清楚的表示RNN的过程,而且是自带分类的RNN。
# 超参
time_step = 10
batch_size = 32
hidden_dim = 32
inputs_dim = 5
# 网络
class MyRnn(layers.Layer):
def __init__(self):
super(MyRnn, self).__init__()
self.hidden_dim = hidden_dim
self.projection1 = layers.Dense(units=hidden_dim, activation='relu')
self.projection2 = layers.Dense(units=hidden_dim, activation='relu')
self.classifier = layers.Dense(1, activation='sigmoid')
def call(self, inputs):
outs = []
states = tf.zeros(shape=[inputs.shape[0], self.hidden_dim])
for t in range(inputs.shape[1]):
x = inputs[:,t,:]
#h=wx+b
h = self.projection1(x)
#y=h+wy_t-1+b
y = h + self.projection2(states)
states = y
outs.append(y)
# print(outs)
features = tf.stack(outs, axis=1)
print(features.shape)
#返回的是分类结果
return self.classifier(features)
# 构建网络
inputs = keras.Input(batch_shape=(batch_size, time_step, inputs_dim))
x = layers.Conv1D(32, 3)(inputs)
print(x.shape)
outputs = MyRnn()(x)
model = keras.Model(inputs, outputs)
rnn_model = MyRnn()
_ = rnn_model(tf.zeros((1, 10, 5)))
2.3 多输入,多输出层
多输入多输出层就是接受两个以上的输入,两个以上的输出,其实现形式都是以列表的形式输入输出,下面是一个示例代码:
from keras import backend as K
from keras.engine.topology import Layer
class MyLayer(Layer):
def __init__(self, output_dim, **kwargs):
self.output_dim = output_dim
super(MyLayer, self).__init__(**kwargs)
def build(self, input_shape):
assert isinstance(input_shape, list)
# Create a trainable weight variable for this layer.
self.kernel = self.add_weight(name='kernel',
shape=(input_shape[0][1], self.output_dim),
initializer='uniform',
trainable=True)
super(MyLayer, self).build(input_shape) # Be sure to call this at the end
def call(self, inputs):
assert isinstance(inputs, list)
#两个输入
a, b = inputs
#两个输出
return [K.dot(a, self.kernel) + b, K.mean(b, axis=-1)]
def compute_output_shape(self, input_shape):
assert isinstance(input_shape, list)
shape_a, shape_b = input_shape
return [(shape_a[0], self.output_dim), shape_b[:-1]]
3. lambda表达式与Lambda层
不同于之前所说的严格意义上的层,因为上面的层有着完善的结构,可以在很多信息里获得。而如果只是一个变换,不需要学习参数的话,例如激活函数那种,那只需要使用Lambda层即可。这里算是借用了Python中的lambda的说法,但是并不是严格意义上的lambda,接下来我们先介绍Python中的lambda表达式,然后,我们再介绍Keras中的Lambda层,这样对于两者的区别就有一个更加直观的认识。
3.1 python 背景知识
lambda表达式在各个语言中都有出现,例如java和C#中,它是一种轻型函数,因为它只能够执行一行表达式,下面是一个简单的例子。
add = lambda x, y : x+y
add(1,2) # 结果为3
由上式可以看到lambda表达式的样子,即只有输入和用于输出的一个句子,相当于一个函数只有return一条语句:
lambda [输入变量] :[运算式]
它能够广泛应用于轻量级的运算中,例如排序算法:
# 需求:将列表中的元素按照绝对值大小进行升序排列
list1 = [3,5,-4,-1,0,-2,-6]
sorted(list1, key=lambda x: abs(x))
#上式等价于下式
list1 = [3,5,-4,-1,0,-2,-6]
def get_abs(x):
return abs(x)
sorted(list1,key=get_abs)
它具有以下3个特性:
- lambda函数是匿名的:所谓匿名函数,通俗地说就是没有名字的函数。lambda函数没有名字。
- lambda函数有输入和输出:输入是传入到参数列表argument_list的值,输出是根据表达式expression计算得到的值。
- lambda函数一般功能简单:单行expression决定了lambda函数不可能完成复杂的逻辑,只能完成非常简单的功能。由于其实现的功能一目了然,甚至不需要专门的名字来说明。
总体来看,它更像是一种简单的接口,可以当做一个对象来使用。
3.2 Lambda层
首先我们来看Keras中Lambda层的样子:
keras.layers.core.Lambda(function, output_shape=None, mask=None, arguments=None)
参数说明:
function:要实现的函数,该函数仅接受一个变量,即上一层的输出
output_shape:函数应该返回的值的shape,可以是一个tuple,也可以是一个根据输入shape计算输出shape的函数
mask: 掩膜
arguments:可选,字典,用来记录向函数中传递的其他关键字参数
它的实际使用方法如下,这是一个切片的例子:
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Activation,Reshape
from keras.layers import merge
from keras.utils.visualize_util import plot
from keras.layers import Input, Lambda
from keras.models import Model
def slice(x,index): #定义的切片函数
return x[:,:,index]
a = Input(shape=(4,2)) #注意点1:第一层输入要带shape
x1 = Lambda(slice,output_shape=(4,1),arguments={‘index‘:0})(a)#注意点2,:使用Lambda作为一层,参数传递方法
x2 = Lambda(slice,output_shape=(4,1),arguments={‘index‘:1})(a)
x1 = Reshape((4,1,1))(x1)
x2 = Reshape((4,1,1))(x2)
output = merge([x1,x2],mode=‘concat‘)
model = Model(a, output)
x_test = np.array([[[1,2],[2,3],[3,4],[4,5]]])
print model.predict(x_test)
plot(model, to_file=‘lambda.png‘,show_shapes=True)
4.总结
本章主要讲解了如何使用Keras或者Tensorflow的层,并解读了一些Keras官方层的源码,加深了对于代码和公式之间联系的理解。并且,我们也讲解了如何编写自己的自定义层。在接下来的时间里,我们会继续讲解其他类型的层,并深入探究其计算图模型的运行时的一些要点,如张量大小的变换等。
