请大家多多尊重原创
GIC是ARM架构中及其重要的部分,本文只在公开ARM对应资料基础上,以MTK开发板为基础整理。个人理解之后记录,巩固和加深认识,仅此而已,如果有错误,欢迎指出。
GIC是ARM体系中重要的组件,在认识到GIC的组成和功能之后,了解到IRQ的大致流程,从硬件IRQ到来,到IRQ结束。我们实际在KERNEL里面,或者在设备驱动里面处理的IRQ其实是软件意义上的,那么硬件的中断和软件的中断如何联系起来的呢,大概的处理流程是如何呢?
这章我们介绍这部分内容。
GIC 中断处理流程
我们希望理解概念和流程,总结认识和思路,所以代码细节上的解释需要忽略掉。可以看代码细节,但是总结时候要去掉。毕竟,即使是自己看过了,过了一段时间再重新读代码,也是有些陌生的。我们还是以图开始。
我们在之前介绍“arm GIC介绍之一/二/三”:
http://blog.csdn.net/sunsissy/article/details/73791470
http://blog.csdn.net/sunsissy/article/details/73842533
http://blog.csdn.net/sunsissy/article/details/73842533
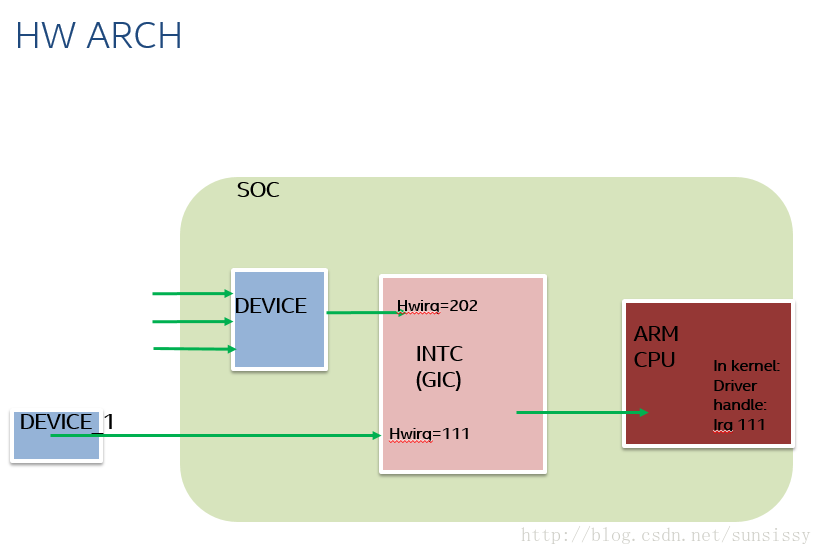
一直在强调,GIC上对物理的IRQ的处理,比如上图,一个DEVICE_1上触发一个IRQ,到GIC,HWIRQ为111,如果软件侧管理中断不冲突的话,可以直接映射desc_irq 111,以此为结构并处理。但是实际中并不这么完美。
比如图中另外一个DEVICE,同时来了3个信号,或者说,而这个设备和GIC只有一个IRQ的物理连接通路,只能传递一个IRQ信号,那么这又如何表示和区分3个信号呢,如何和CPU的软件意义上的IRQ联系起来呢?
这就新增加了IRQ_DOMAIN的概念。
struct irq_domain {
struct list_head link;
const char *name;
const struct irq_domain_ops *ops; //callback函数
void *host_data;//this will point to irq_data, and contains gicd_base, info and so on.
/* Optional data */
struct device_node *of_node;//该interrupt domain对应的interrupt controller的device node
struct irq_domain_chip_generic *gc; //generic irq chip concept , we ignore this.
/* reverse map data. The linear map gets appended to the irq_domain */
irq_hw_number_t hwirq_max; //该domain中最大的那个HW interrupt ID
unsigned int revmap_direct_max_irq; //
unsigned int revmap_size; //线性映射的size,for Radix Tree map和no map,该值等于0
struct radix_tree_root revmap_tree; //Radix Tree map will use radix tree root node
unsigned int linear_revmap[]; //linear mapping lookup table, we will pay attention to it.
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
简化后如图:
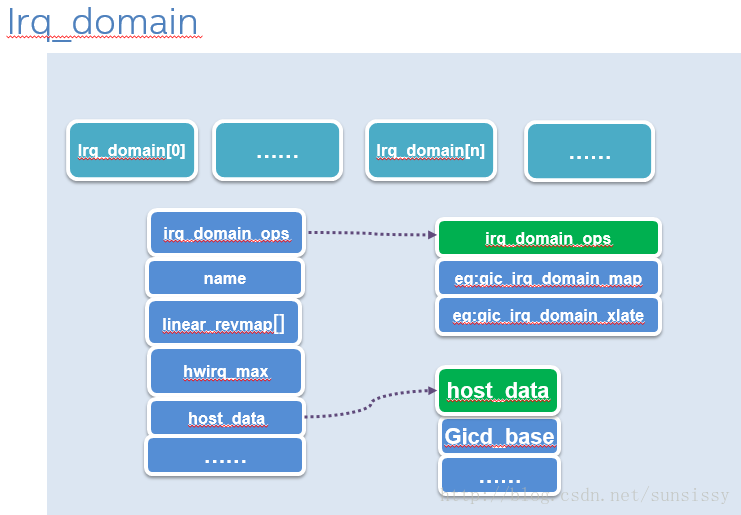
总结来说,IRQ_DOMAIN是以GIC 为单位,一个GIC设备对应一个IRQ_DOMAIN, 从图中可以看出,如果系统中有多个IRQ_DOMAIN,那么会形成一个list,统一管理。
IRQ_DOMAIN里面包含了GIC的基本信息,比如host_data,可以保存对应的Distributor的基地址;最大的硬件中断数目hwirq_max;如果是线性映射,那么linear_revmap保存了线性映射的关系;
当然,重要的irq_domain_ops里面有对应的操作,eg:gic_irq_domain_map这就是如何把硬件IRQ和软件处理侧的desc_irq对应起来的。
只有这样映射后,软件侧才方便以desc_irq单位对IRQ进行管理和处理,desc_irq如图: 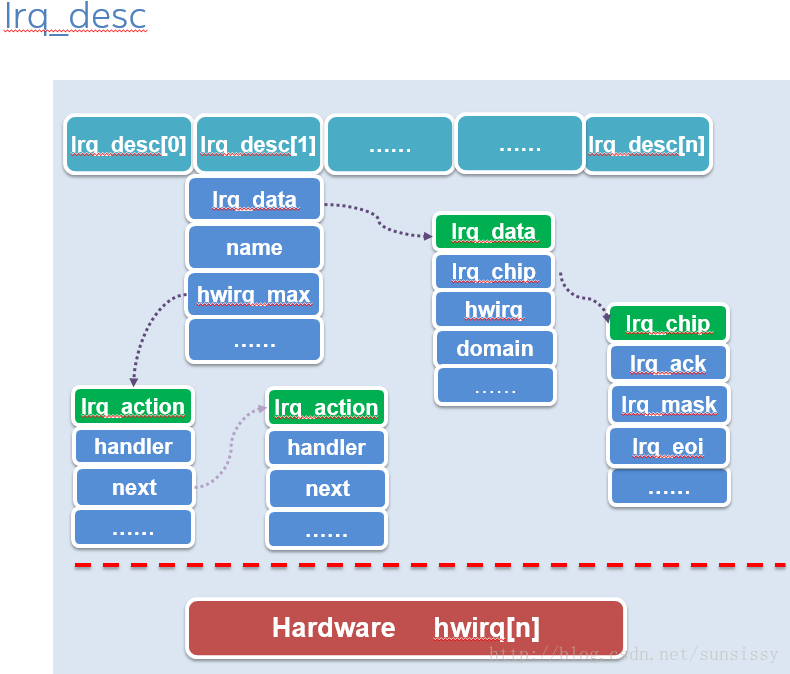
对每个desc_irq,不仅包含了一个IRQ的基本信息,也包含了对应的控制等信息。
Irq_data中,有一个IRQ对应的硬件中断号hwirq,对应的GIC DOMAIN。当然Irq_chip以及对应的API,提供了如何向GIC写入信息比如表示IRQ处理结束写入Irq_eoi等等。
Irq_action 里面有中断的处理入口,以及对应的具体函数HANDLER。
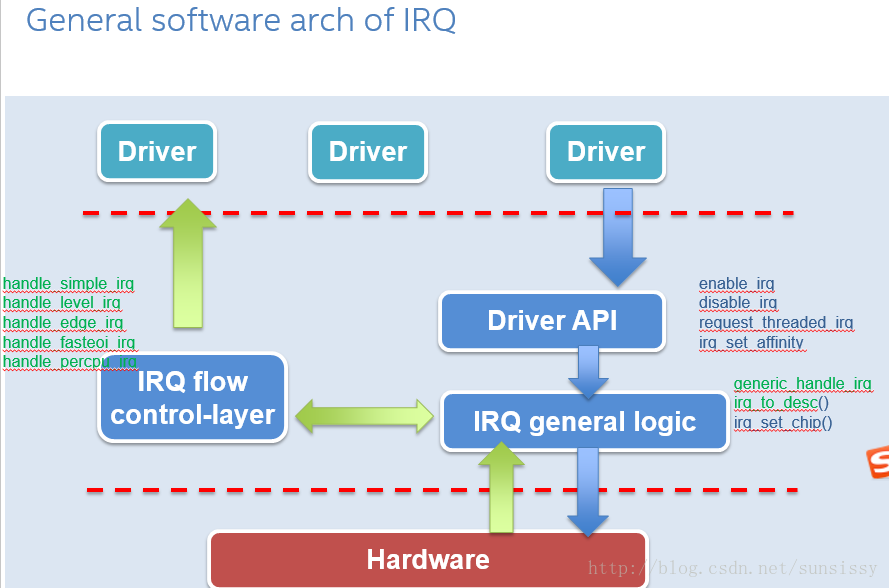
这是在软件处理层面的,有了这样的接口和信息,一个驱动才可以获得一个desc_irq,把对应的IRQ注册到里面,并对触发方式,是否MASK进行控制,并找到对应的HANDLER进行注册和后续处理。所以从整个的流程来说我们给出这样的逻辑结构,见下图:
整个结构分为3部分,上面试DRIVER,可以认为是使用者,中间是软件的层面,最下面是Hardware ,这里重要的是中间的结构,为上层DRIVER提供了IRQ的注册接口request_threaded_irq,使能接口enable_irq,亲和性或者说送到具体CPU处理的配置接口irq_set_affinity等,这里不全部列举。
那么这些接口要具体配置到GIC硬件的Hardware上,在IRQ general logic中就有对应的 irq_set_chip,这里面对应的操作会去执行和具体平台硬件相关的设置。不仅如此,当设置完成,允许中断,如果来了一个硬件中断到Hardware ,那么也在IRQ general logic进行先处理,所以这提供双向的SERVICE。会先irq_to_desc,找到对应的desc_irq,然后分类处理如果IPI走对应处理,如果是其它的走generic_handle_irq,这就转到了左侧的IRQ flow
control-layer 。
IRQ flow control-layer顾名思义,就是把众多的接受到的中断分流,如果是LEVEL触发类型的,走handle_level_irq,上下沿触发的走handle_edge_irq,不同的入口可能对EOI的写入时机和方式有区别等等。再如handle_percpu_irq在处理时候,因为不涉及到其它CPU,所以对于多个CPU之间共享的操作就不需要LOCK做保护。然后再去找特定的每个驱动定义的HANDLER处理。
GIC 中断处理流程实例
看下:
shell@amt6797_64_open:/ shell@amt679764open:/shell@amt679764open:/ cat /proc/interrupts
CPU0
29: 0 GICv3 29 arch_timer_sec_zhonghua
30: 50721 GICv3 30 arch_timer
96: 0 GICv3 96 mtk_cpuxgpt0
97: 0 GICv3 97 mtk_cpuxgpt1
……
184: 45 GICv3 184 mtk_cmdq
188: 0 GICv3 188 m4u
201: 0 GICv3 201 mt-gpt
210: 0 GICv3 210 pmic_wrap
211: 0 GICv3 211 mtk-kpd
212: 0 GICv3 212 SPM
231: 0 GICv3 231 SCP IPC_MD2HOST
234: 720 GICv3 234 mutex
……
255: 0 GICv3 255 aal
361: 0 GICv3 361 ocp_cluster2
362: 0 GICv3 362 ocp_cluster2
389: 1 mt-eint 5 TOUCH_PANEL-eint
390: 0 mt-eint 6 11240000.msdc1 cd
392: 0 mt-eint 8 iddig_eint
400: 0 mt-eint 16 accdet-eint
560: 1 mt-eint 176 pmic-eint
IPI0: 7106 Rescheduling interrupts
IPI1: 7 Function call interrupts
IPI2: 196 Single function call interrupts
IPI3: 0 CPU stop interrupts
IPI4: 0 Timer broadcast interrupts
IPI5: 112 IRQ work interrupts
Err: 0
shell@amt6797_64_open:/
上面是从X20上看到interrupts。左侧部分加粗体是硬件中断号,右侧对应的斜体数字是软件看到的desc_irq对应的编号。
这里面可以看到,以左侧硬件中断号为索引来说。上面是29和30号中断,这个是PPI中断类型,在这里是CPU对应的TIMER,从这往后到362是SPI,在X20上支持384个硬件中断号,所以多出来的389~560就奇怪了。我们后面介绍。
另外就是IPI消息,这个比较少。
我们先分析下,硬件中断号如何和软件对应的。
首先: 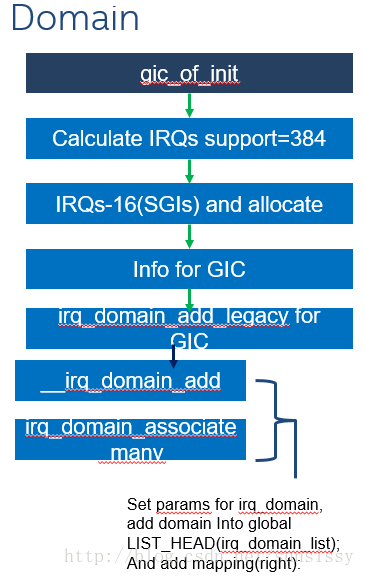
在进入KERNEL之后,进行GIC初始化后,我们之前提到IRQ_DOMAIN的配置,提到以GIC为单位。那么在这里通过读取参数获取到支持的HARDWARE IRQ数目是384个,去掉其中16个SGI(不需要映射),新申请384-16个desc_irq,并且把IRQ_DOMAIN其它数据如基地址等都填好,挂到LIST上统一管理。在这里,采用的是简单的线性MAPPING,所以17到384这中间的硬件中断号和软件中断号是一一对应的,打印出来: 
第一个编号为16,最后一个编号为383的IRQ。
之后进行基本的irq_domain_associate_many。我们看下这里做了什么:
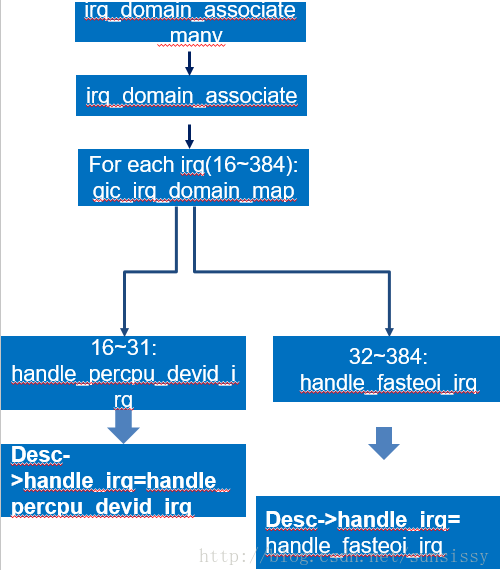
这里名字上说是associate,其实是对这些IRQ做些分类的基本信息填充,主要的是区分16~31号中断的描述信息,由于是PPI中断,所以将其分流入口设定为handle_percpu_devid_irq。那么其它一般的SPI 分流入口这里都设定为handle_fasteoi_irq,而不是handle_level_irq或者handle_edge_irq。