【python web开发知识点整理1】- Python基础
【python web开发知识点整理2】- Python Web基础
【python web开发知识点整理3】- 容器基础
【python web开发知识点整理4】- 数据库基础
【python web开发知识点整理5】- Linux基础
【python web开发知识点整理6】- 设计模式
1. Python基础
1.1. PEP8是什么?
PEP8是Python编码风格指南,即 Style Guide for Python Code。一些关于如何让你的程序更具有可读性的建议。
1.2. Python之禅(import this)是什么?
Python shell 里执行一下:import this,是作者对开发者的建议。
1.3. Python常用的容器类型有哪些以及它们之间的差别?
常用的容器类型list、tuple、dict、set等。
- list是可变类型,其大小可以改变,其元素是对象的引用。
- tuple是不可变类型,其大小创建后可以改变,其元素是对象的引用。
- dict是可变类型,字典可以存储键值对但键必须唯一,只有可哈希的对象可以做键,其元素是对象的引用。
- set是可变类型,可以理解为特殊的字典,只存储键且是唯一的。
list和tuple的差别:
list一个是可变的,tuple是不可变的
set、dict和list、tuple的差别:
- set、dict是无序的,键是哈希后再排序进行存储的,插入顺序和输出顺序不一致,
list、tulpe是有序的。 - 获取方式不同,list、tulpe可以通过索引获取,可以切片,dict通过键获取
- 对于key来说,set、dict是存放元素是唯一的,不能重复的,list、tulpe是可重复的
- 可变类型不同
- 查询速度不同
还有一些常用的容器类型,比如OrderedDict可以解决字典无序的问题
1.4. 解释下闭包是什么,以及日常中什么场景会用到?
1.4.1 闭包的条件
- 在一个外函数中定义了一个内函数。
- 内函数里运用了外函数的临时变量。
- 并且外函数的返回值是内函数的引用
1.4.2 最常用到的是装饰器
可以通过装饰器做数据缓存、打印日志、判断参数合法性等。
1.5. GIL是什么?它的影响和具体原理是什么?
GIL:Global Interpreter Lock(全局解释器锁)。
在一个进程中,同一时刻只能有一个线程能到解释器,为什么只能有一个线程拿到解释器呢?因为在 CPython 中,内存管理不是线性安全的,所以,为了避免多个线程同时访问到一个对象,就有了这么一个锁,即全局解释器锁。
1.5.1. 那么 Python 中有哪些类型是线程安全的呢?
Python中基本数据类型list, dict, tuple等都是线程安全的。
1.5.2. 那么 GIL 的影响是什么呢?
就是同一时刻只有一个线程在真实执行,对于CPU密集型的应用影响比较大,对于IO密集型的应用影响没那么大。
一个磁盘或网络为主的程序称为IO密集型的应用,一个计算为主的程序称为CPU密集型的应用,计算为主的程序利用多cup处理多进程来提供计算速度,但只有一个线程可以真实执行,其他CPU会闲置,所以影响比较大。
1.6. 进程、协程、线程分别是什么,以及区别是什么?
从操作系统角度来讲,进程是资源分配单元,线程是执行单元,多个线程可以共享所在进程的资源。而协程是从程序运行角度来叫,是由用户(程序)控制和调度的一个过程,在 Python中,协程是由用户程序自己控制调度,是单线程下的并发。
协程看上去也是子程序,但执行过程中,在子程序内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行。
注意,在一个子程序中中断,去执行其他子程序,不是函数调用,有点类似CPU的中断。
最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
第二大优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
因为协程是一个线程执行,那怎么利用多核CPU呢?最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。
yield
Python通过yield提供了对协程的基本支持,但是不完全。而第三方的gevent为Python提供了比较完善的协程支持。
gevent
gevent是第三方库,通过greenlet实现协程,其基本思想是:
当一个greenlet遇到IO操作时,比如访问网络,就自动切换到其他的greenlet,等到IO操作完成,再在适当的时候切换回来继续执行。由于IO操作非常耗时,经常使程序处于等待状态,有了gevent为我们自动切换协程,就保证总有greenlet在运行,而不是等待IO。
1.7. 面向对象设计六大原则?
- 单一职责原则——SRP
- 开闭原则——OCP
- 里式替换原则——LSP
- 依赖倒置原则——DIP
- 接口隔离原则——ISP
- 迪米特原则——LOD
1.7.1. 单一职责原则
单一职责原则,Single Responsibility Principle,简称SRP。
其定义是应该有且仅有一个类引起类的变更,这话的意思就是一个类只担负一个职责。
优点:
- 类的复杂性降低,实现什么职责都有明确的定义;
- 逻辑变得简单,类的可读性提高了,而且,因为逻辑简单,代码的可维护性也提高了;
- 变更的风险降低,因为只会在单一的类中的修改。
1.7.2. 开-闭原则
开闭原则,Open Closed Principle,是Java世界里最基础的设计原则,其定义是:
一个软件实体如类、模块和函数应该对扩展开放,对修改关闭
也就是说,一个软件实体应该通过扩展来实现变化,而不是通过修改已有的代码实现变化。这是为软件实体的未来事件而制定的对现行开发设计进行约束的一个原则。
在我们编码的过程中,需求变化是不断的发生的,当我们需要对代码进行修改时,我们应该尽量做到能不动原来的代码就不动,通过扩展的方式来满足需求。
优点:
降低了程序各部分之间的耦合性,其适应性、灵活性、稳定性都比较好。当已有软件系统需要增加新的功能时,不需要对作为系统基础的抽象层进行修改,只需要在原有基础上附加新的模块就能实现所需要添加的功能。增加的新模块对原有的模块完全没有影响或影响很小,这样就无须为原有模块进行重新测试。
1.7.3. 里氏代换原则
里氏替换原则,英文名Liskov Substitution Principle,它的定义是
如果对每一个类型为T1的对象o1,都有类型为T2的对象o2,使得以T1定义的所有程序P在所有对象o1都替换成o2的时候,程序P的行为都没有发生变化,那么类型T2是类型T1的子类型。
看起来有点绕口,它还有一个简单的定义:
所有引用基类的地方必须能够透明地使用其子类的对象。
优点:
可以很容易的实现同一父类下各个子类的互换,而客户端可以毫不察觉。
1.7.4. 依赖倒换原则
依赖倒置原则,Dependence Inversion Principle,简称DIP,它的定义是:
高层模块不应该依赖底层模块,两者都应该依赖其抽象;
抽象不应该依赖细节;
细节应该依赖抽象;
优点:
人的思维本身实际上就是很抽象的,我们分析问题的时候不是一下子就考虑到细节,而是很抽象的将整个问题都构思出来,所以面向抽象设计是符合人的思维的。另外这个原则会很好的支持(开闭原则)OCP,面向抽象的设计使我们能够不必太多依赖于实现,这样扩展就成为了可能,这个原则也是另一篇文章《Design by Contract》的基石。
1.7.5. 接口隔离原则
接口隔离原则,Interface Segregation Principle,简称ISP,其定义是:
客户端不应该依赖它不需要的接口
优点:
会使一个软件系统功能扩展时,修改的压力不会传到别的对象那里。
1.7.6. 迪米特法则或最少知识原则
迪米特原则,Law of Demeter,简称LoD,也被称为最少知识原则,它描述的规则是:
一个对象应该对其他对象有最少的了解
优点:
消除耦合。
1.8. 解释下什么是 ORM 以及它的优缺点是什么?
ORM是Object Relational Mapping(对象关系映射)
它做的事就是帮我们封装一下对数据库的操作,避免我们来写不太好维护的SQL代码。
优点:
使用ORM写的代码更容易维护,因为里面不用夹杂着各种SQL代码。
缺点:
失去了 SQL 的灵活,并且越是通用的 ORM 框架,性能损耗会越大。
1.9. 深拷贝和浅拷贝的区别是什么?
深拷贝是将对象本身复制给另一个对象。这意味着如果对对象的副本进行更改时不会影响原对象。在 Python 中,我们使用 deepcopy()函数进行深拷贝。
浅拷贝是将对象的引用复制给另一个对象。因此,如果我们在副本中进行更改,则会影响原对象。使用 copy()函数进行浅拷贝。
1.10. 解释 Python 中的三元表达式
[on true] if [expression]else [on false]
如果 [expression] 为真, 则 [on true] 部分被执行。如果表示为假则 [on false] 部分被执行
1.11. Python 中如何实现多线程?
python主要是通过thread和threading这两个模块来实现多线程支持。
_thread提供了低级别的、原始的线程以及一个简单的锁,它相比于threading模块的功能还是比较有限的,可以更加方便的被使用。但是python(cpython)由于GIL的存在无法使用threading充分利用CPU资源,如果想充分发挥多核CPU的计算能力需要使用multiprocessing模块(Windows下使用会有诸多问题)。
1.12. 解释继承
一个类继承自另一个类,也可以说是一个孩子类/派生类/子类,继承自父类/基类/超类,同时获取所有的类成员(属性和方法)。
继承使我们可以重用代码,并且还可以更方便地创建和维护代码。Python支持以下类型的继承:
- 单继承- 一个子类类继承自单个基类
- 多重继承- 一个子类继承自多个基类
- 多级继承- 一个子类继承自一个基类,而基类继承自另一个基类
- 分层继承- 多个子类继承自同一个基类
- 混合继承- 两种或两种以上继承类型的组合
1.13. Python是如何进行内存管理的?
1.13.1. 引用计数:
Pyhton的内部使用引用计数,来保持内存中的对象,所有对象都有引用计数。
-
引用计数增加:
- 一个对象分配一个新名称
- 将其放入一个容器中(列表、元素或字典)
-
引用减少的情况
- 使用del语句将对象的别名显式的销毁
- 引用被重新赋值
- 获取应用对象:
- 通过sys.getrefcount()函数获取某个引用的引用数,函数参数实际上创建了一个临时的引用。因此,getrefcount( )所得到的结果,会比期望多1。
1.13.2. 垃圾回收:
- 当一个对象的引用计数归零时,它将被垃圾回收机制处理掉
- python的自动垃圾回收:当分配对象的次数和取消分配对象的次数的差值高于某个阈值时,垃圾回收才会启动。
1.13.2.1 标记清除
『标记清除(Mark—Sweep)』算法是一种基于追踪回收(tracing GC)技术实现的垃圾回收算法。它分为两个阶段:第一阶段是标记阶段,GC会把所有的『活动对象』打上标记,第二阶段是把那些没有标记的对象『非活动对象』进行回收。那么GC又是如何判断哪些是活动对象哪些是非活动对象的呢?
对象之间通过引用(指针)连在一起,构成一个有向图,对象构成这个有向图的节点,而引用关系构成这个有向图的边。从根对象(root object)出发,沿着有向边遍历对象,可达的(reachable)对象标记为活动对象,不可达的对象就是要被清除的非活动对象。根对象就是全局变量、调用栈、寄存器。
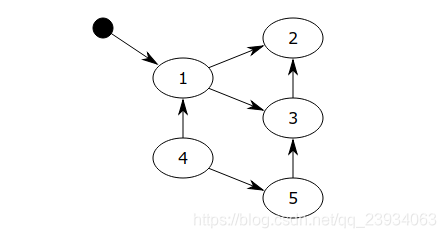
在上图中,我们把小黑圈视为全局变量,也就是把它作为root object,从小黑圈出发,对象1可直达,那么它将被标记,对象2、3可间接到达也会被标记,而4和5不可达,那么1、2、3就是活动对象,4和5是非活动对象会被GC回收。
标记清除算法作为Python的辅助垃圾收集技术主要处理的是一些容器对象,比如list、dict、tuple,instance等,因为对于字符串、数值对象是不可能造成循环引用问题。Python使用一个双向链表将这些容器对象组织起来。不过,这种简单粗暴的标记清除算法也有明显的缺点:清除非活动的对象前它必须顺序扫描整个堆内存,哪怕只剩下小部分活动对象也要扫描所有对象。
1.13.2.2 分代回收
python将内存根据对象的存活时间分为不同的集合,每个集合称为一代,python将内存分为了3代。分别为 年轻代(第0代)、中年代(第1代)、老年代(第2代)
这三代分别对应的是三个链表
新创建的对象会被分配在年轻代。年轻代链表总数达到上限的时候,python的垃圾回收机制就会触发,把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去。以此类推,老年代中的对象是存活时间最久的对象
分代回收建立在标记清除的技术基础上
分代回收是一种以空间换时间的操作方式,Python将内存根据对象的存活时间划分为不同的集合,每个集合称为一个代,Python将内存分为了3“代”,分别为年轻代(第0代)、中年代(第1代)、老年代(第2代),他们对应的是3个链表,它们的垃圾收集频率与对象的存活时间的增大而减小。新创建的对象都会分配在年轻代,年轻代链表的总数达到上限时,Python垃圾收集机制就会被触发,把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,依此类推,老年代中的对象是存活时间最久的对象,甚至是存活于整个系统的生命周期内。同时,分代回收是建立在标记清除技术基础之上。分代回收同样作为Python的辅助垃圾收集技术处理那些容器对象
1.13.2.2 三种触发垃圾回收的情况
调用gc.collect(),需要先导入gc模块
当gc模块的计数器达到阈值的时候
程序退出时
1.13.3. 内存池机制
Python的内存垃圾回收机制,将不用的内存放到内存池而不是返回给操作系统。
- Pymalloc机制。为了加速Python的执行效率,Python引入内存池机制,用于管理对小块内存的管理和释放。
- 对于所有小于256个字节的对象都使用pymalloc实现的分配器;而大于这个长度的对象则使用系统的malloc。
- 对于Python对象,如整数、浮点数和List,都有其独立的私有内存池,对象间不共享他们的内存池。如果你分配又释放了大量的整数,用于缓存这些整数的内存不能再分配给浮点数。
1.14. 描述数组、链表、队列、堆栈的区别?
数组与链表是数据存储方式的概念,数组在连续的空间中存储数据,而链表可以在非连续的空间中存储数据;
队列和堆栈是描述数据存取方式的概念,队列是先进先出,而堆栈是后进先出;
队列和堆栈可以用数组来实现,也可以用链表实现。
1.15. 当退出Python时是否释放所有内存分配?
具有对象循环引用或者全局命名空间引用的变量,在Python退出是往往不会被释放。
另外不会释放C库保留的部分内容。
1.16. 什么是猴子补丁?
在运行时动态修改类和模块。
1.17. 能否解释一下 *args 和 **kwargs?
如果我们不知道将多少个参数传递给函数,比如当我们想传递一个列表或一个元组值时,就可以使用*args。
当我们不知道将会传入多少关键字参数时,使用**kwargs 会收集关键字参数。
使用 args 和 kwargs 作为参数名只是举例,可以任意替换。
1.18. 什么是负索引?
Python中的序列索引可以是正也可以是负。如果是正索引,0是序列中的第一个索引,1是第二个索引。如果是负索引,(-1)是最后一个索引而(-2)是倒数第二个索引。
1.19.python中的构造方法和初始化方法的区别?
对于类的 new 方法和 init 方法可以概括为:
new 方法是Python的新式类中真正的构造方法,负责创建并返回实例,因此,new 方法必须要有返回值;
init 方法是初始化方法,负责初始化 new 方法返回的实例对象。
1.20.请简述一下互斥锁和递归锁的异同?
不同点:互斥锁不能连续acquire,连续acquire会产生死锁现象;递归锁可以连续的acquire。
相同点:互斥锁和递归锁都可以保证同一段代码在同一时间只有一个线程执行。
