在上文中(聊聊Linux动态链接中的PLT和GOT(1)—— 何谓PLT与GOT)介绍解决动态库函数调用使用GOT表技术,然后PLT从GOT中获取地址并完成调用。这个前提是GOT必须在PLT执行之前,所有函数都已完成运行时重定位。
然而在Linux的世界里面,几乎所有可能的事情,都尽可能地延迟推后,直至无法退避时,才做最后的修正工作。典型的案例有:
fork之后父子进程内存的写时拷贝机制
Linux用户态内存空间分配与物理内存分配机制
C++库的string类写时拷贝机制当然,也少不了动态链中的延迟重定位机制。
延迟重定位
如果可执行文件调用的动态库函数很多时,那在进程初始化时都对这些函数做地址解析和重定位工作,大大增加进程的启动时间。所以Linux提出延迟重定位机制,只有动态库函数在被调用时,才会地址解析和重定位工作。
进程启动时,先不对GOT表项做重定位,等到要调用该函数时才做重定位工作。要实现这个机制必须要有一个状态描述该GOT表项是否已完重定位。
一个显而易见的方案是在GOT中增加一个状态位,描述一个GOT表项是否已完成重定位,那么每个函数就有两个GOT表项了。相应的PLT伪代码如何:
void printf@plt()
{
if (printf@got[0] != RELOCATED) { // 如果没完成重定位
调用重定位函数
printf@got[1] = 地址解析发现的printf地址;
printf@got[0] = RELOCATED;
}
jmp *printf@got[1];
}
这个方案每个函数使用两个GOT表项,占用内存明显增长了一倍。但仔细观察GOT表项中的状态位和真实地址项,这两项在任何时候都不会同时使用,那么这两个变量能复用一个GOT项来实现呢?答案是可以的,Linux动态链接器就使用类似的巧妙方案,将这两个GOT表项合二为一。
具体怎么做呢?很简单,先将上面的代码倒过来写:
void printf@plt()
{
address_good:
jmp *printf@got // 链接器将printf@got填成下一语句lookup_printf的地址
lookup_printf:
调用重定位函数查找printf地址,并写到printf@got
goto address_good;
}
在链接成可执行文件test时,链接器将printf@got表项的内容填写lookup_printf标签的地址。
也即是程序第一次调用printf是时,通过printf@got表项引导到查找printf的plt指令的后半部分。在后半部分中跳到动态链接器中将printf址解析出来,并重定位回printf@got项内。
那么神奇的作用来,第二次调用printf时,通过printf@got直接跳到printf函数执行了。
下面是test可执行文件,通过objdump -d test > test.asm命令反编译之后生成汇编代码,可以看到整个跳转过程。
下面是test.asm文件中与PLT/GOT相关的部分,并对一些容易引起误解的地方做了修改
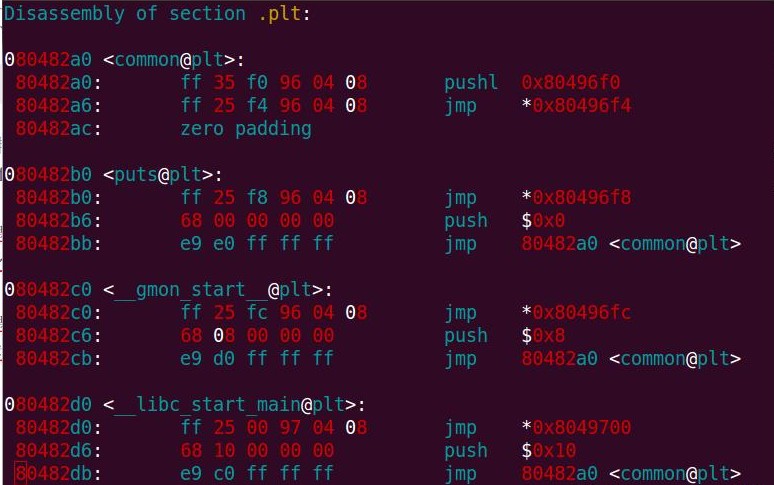
我将第一项plt表修改成<common@plt>项了,objdump -d输出结果会使用错误的符号名。那是因为该项是没有符号的,而objdump输出时,给它找了一个地址接近符号,所以会显示错误的符号名,为了避免引起误解,直接删掉。
每个plt指令中的jmp *0xf80496xx 都是访问相应的got项。在函数第一次调用之前,这些got项的内容都是链接器生成的,它的值指向对应plt中jmp的下一条指令。
下面是使用gdb命令,查看test可执行文中函数的got表内容,如下:
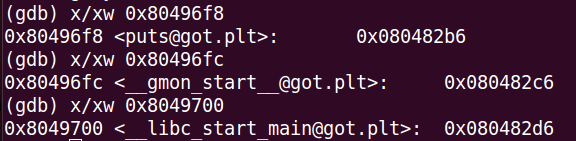
将两张图对照一下,就可以看到前面说到的规律。
最后所有plt都跳转到common@plt中执行,这是动态链接做符号解析和重定位的公共入口,而不是每个plt表都有重复的一份指令。为了减少PLT指令条数,Linux提炼成了公共函数。从这一点来看,Linux也是拼了。
