现在比较习惯于看电子版的专业书籍,但是有时候弄到的电子书没有书签,一个个手动添加太费事。于是找到了一些好工具可以实现半自动化PDF目录标签的生成。说半自动化是因为有些地方还需要手动调整,但是已经省了很多事。
比如我有这样一本书:

书自然是好书,但是很遗憾没有标签,看起来有些不方便。现在开始来自制标签。需要准备的软件:
1. PDF Shaper (免费开源软件)用来把书中目录这几页PDF拿出来
2. Adobe Acrobat Pro 2017 用来把PDF里目录这部分导出成word格式。
3. FreePic2Pdf(免费软件,网上随便下一个即可) 用来把按要求编写的文本格式目录导入到目标PDF文档中。
现在开始制作:
1. PDF Shaper打开

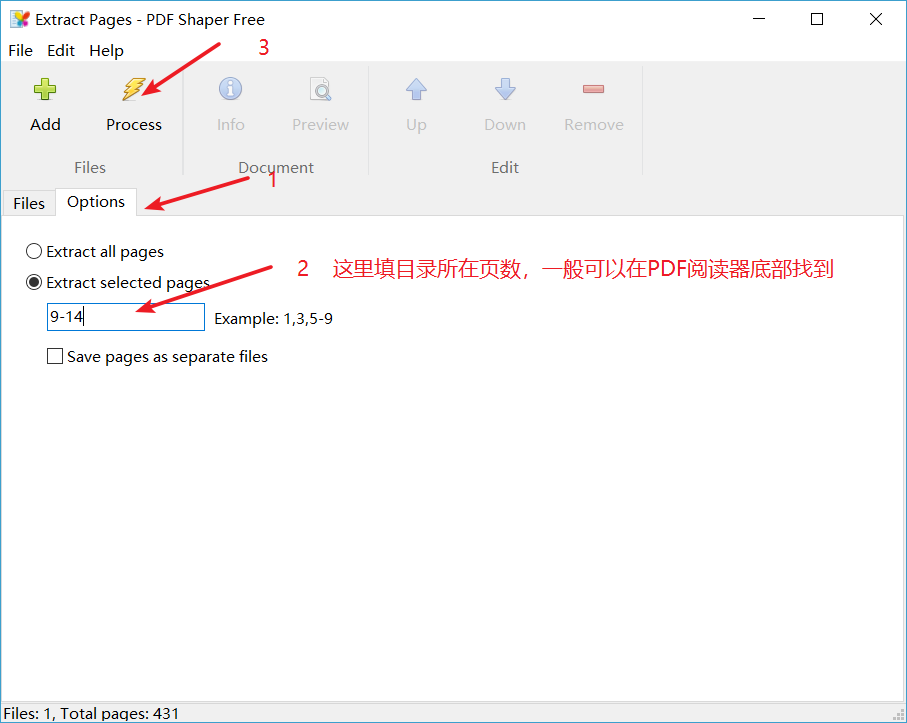
提取成功以后可以得到这么几页PDF:

2. 现在用Acrobat把这几页PDF转存成word:
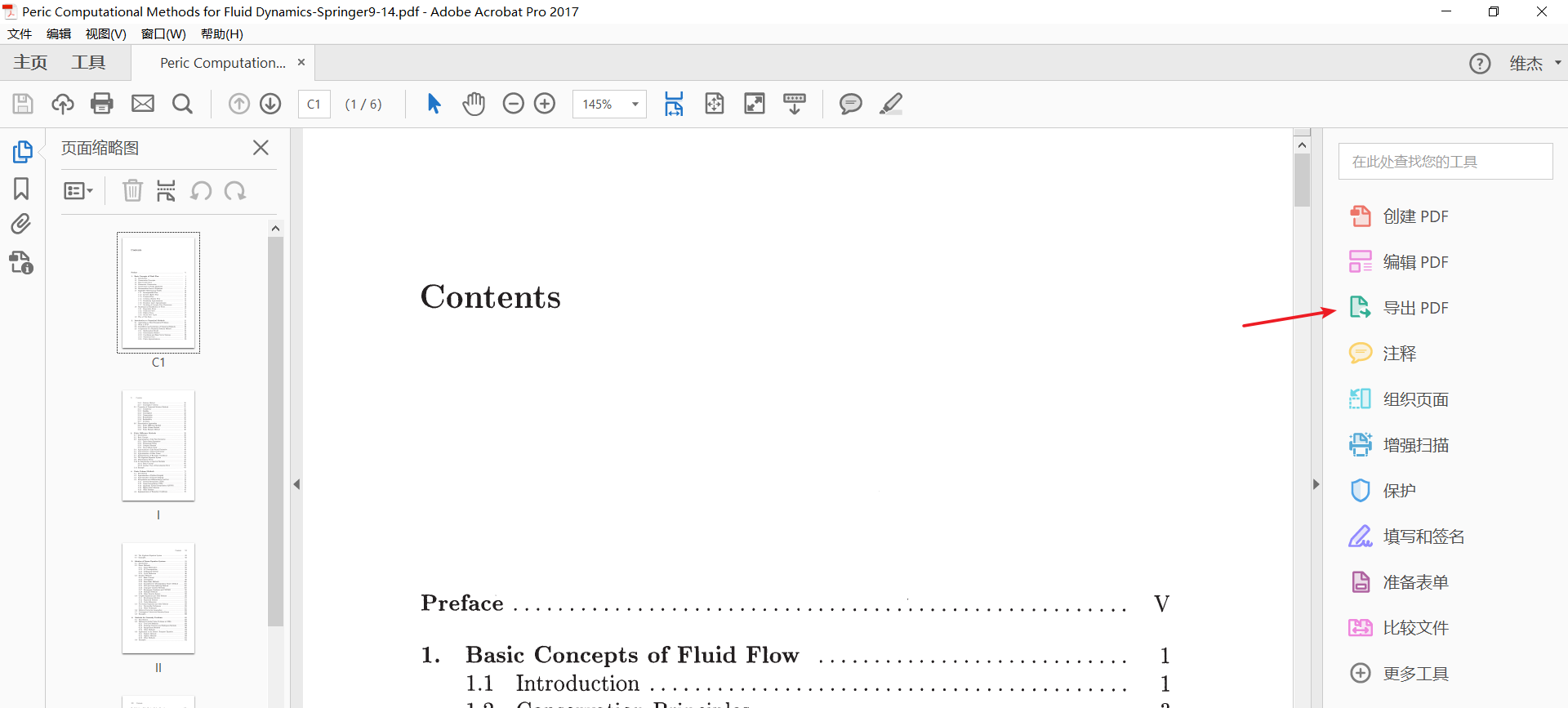
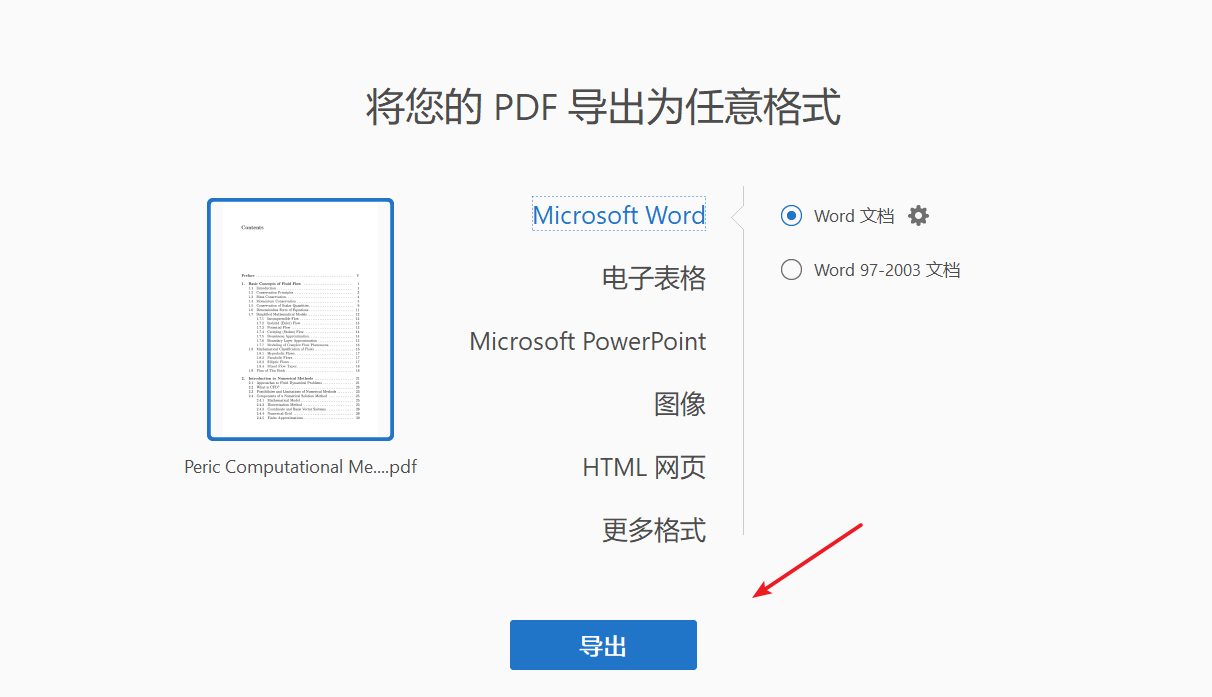
把word里的文本复制粘贴到TXT文本文件中便于处理:

这是直接从word里复制出来的格式,一会还得处理一下。
3. 用FreePic2Pdf制作书签。
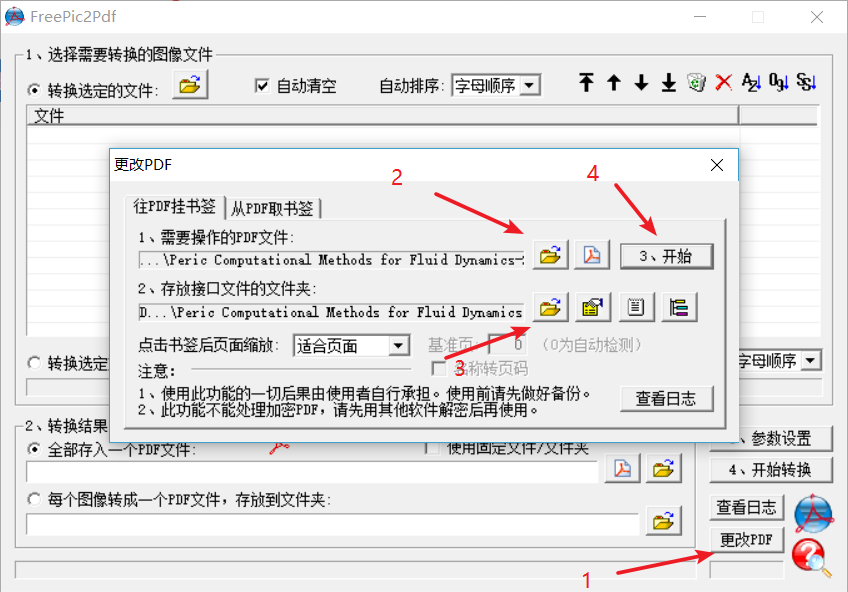
上图的第2步是选择要处理PDF所在路径,第3步是选择格式化文本文件所在路径,这个文本还没制作,要用刚刚word复制出来的文本进行排版:
因为word里导出来的目录,页码对应的是书中的页码,而不是PDF的绝对页数,比如:

这里在书中是第1页,但是在PDF文档中实际上是15页,所以只要把所有数字加14就可以。还有一个需要注意的是,最后那个数字前面不能是空格,得是\tab才行,也需要批量替换一下,这里我就写个python脚本快速处理一下,可以参考我的:
#!/usr/bin/python3 # -*- coding: UTF-8 -*- ''' @Author: Yin Weijie @Date: 2018.5.25 @Description: 替换页码 ''' fin = open("aa.txt", "r") fout = open("bb.txt", "w") for each_line in fin: list = each_line.split() for i in range(len(list) - 1): fout.write(list[i]) fout.write(' ') fout.write('\t') num = int(list[-1]) + 14 fout.write(str(num)) fout.write("\n") fin.close() fout.close()
原始文本格式:

处理后文本格式:
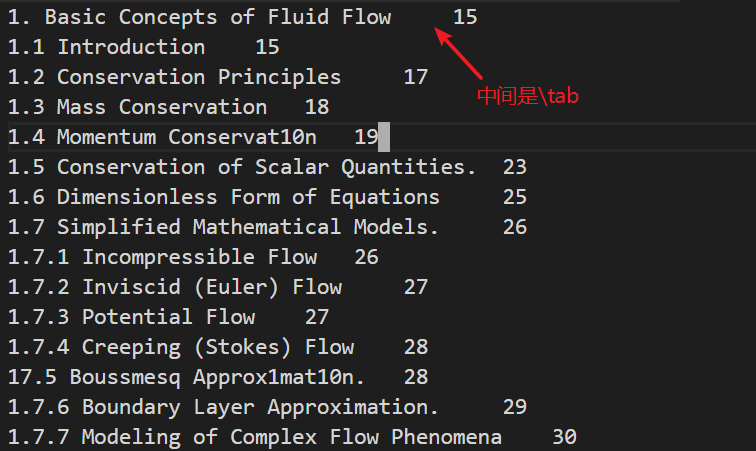
为了排版更清爽一点,可以根据目录层级,再加上一些\tab,例如:

后面都可以根据需要调整。制作好了以后,保存在名为FreePic2Pdf_bkmk.txt的文本中,再到这一步来:
把这个文本放到3所指文件夹。然后开始就可以了。
最后效果如下:

参考:
http://www.cnblogs.com/dux2016/articles/6201263.html
https://blog.csdn.net/mofei123456789/article/details/78525884