正在开会,突然线上站点线程数破千。然后一群人现场dump分析。
先看一眼线程运行状态 !eeversion

发现CPU占用并不高,19%,937条线程正在运行。
看看他们都在干什么。 ~* e !clrstack
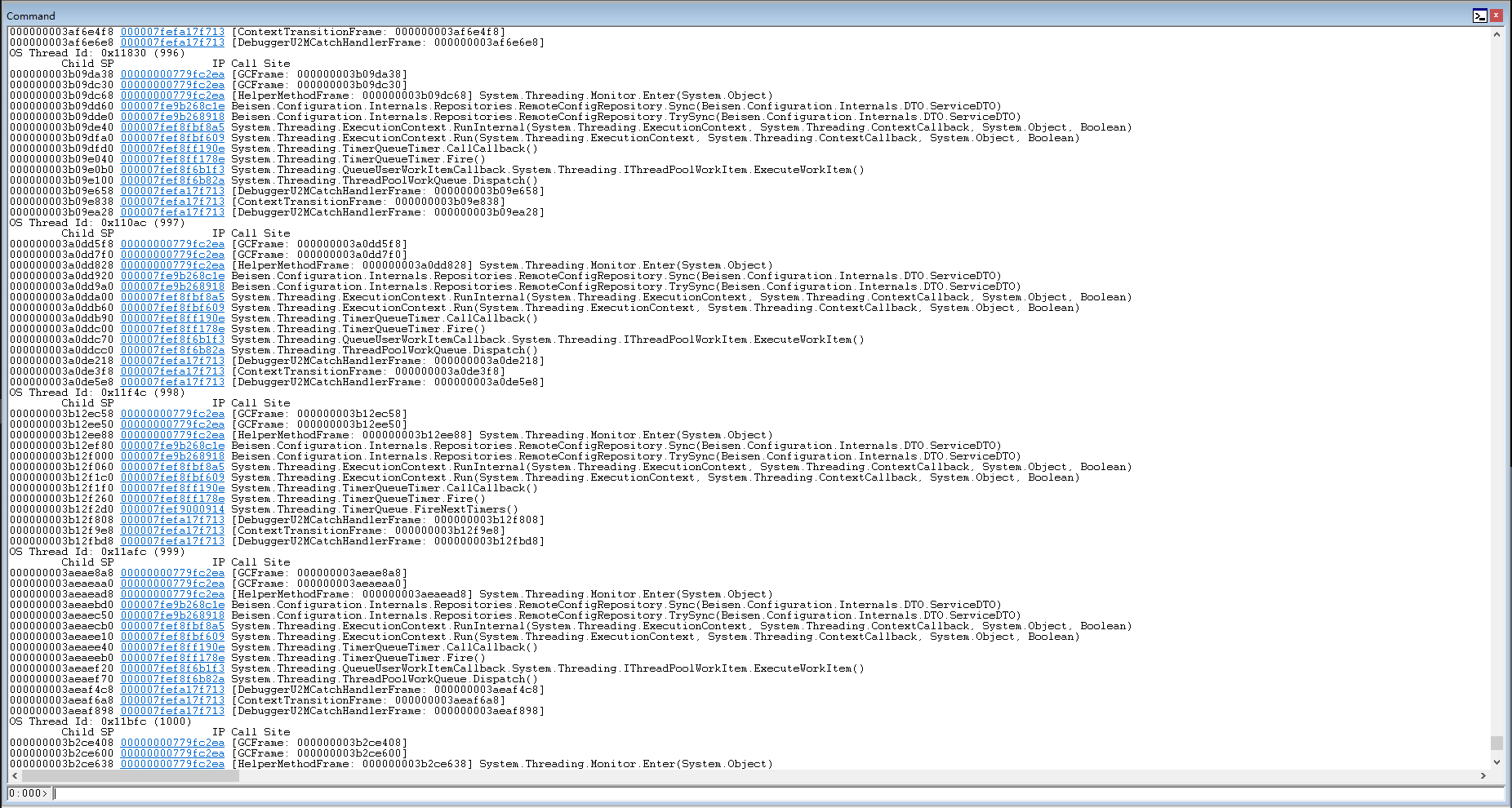
发现大片内容相似的,并且最后一行是System.Threading.Monitor.Enter,尝试获取锁。很大概率是死锁了,排查一下是否存在死锁的情况。
运行 !syncblk 查看当前的锁的情况

等待数并不是真的等待数,需要(线程数 -1) / 2,至于具体为什么这么算我就不清楚了。将所有的数据相加 正好是等于937。也就是说所有的线程都在运行,所有的线程都得等待锁,所以肯定出现死锁了。复制内容出来备用。
从第一个线程 90 开始查。~90s,进入90号线程上下文,然后打印堆栈信息 !clrstack -l

上下文信息中只有这个有值,这个很大概率就是锁对象的地址。然后去锁对象列表中查一下
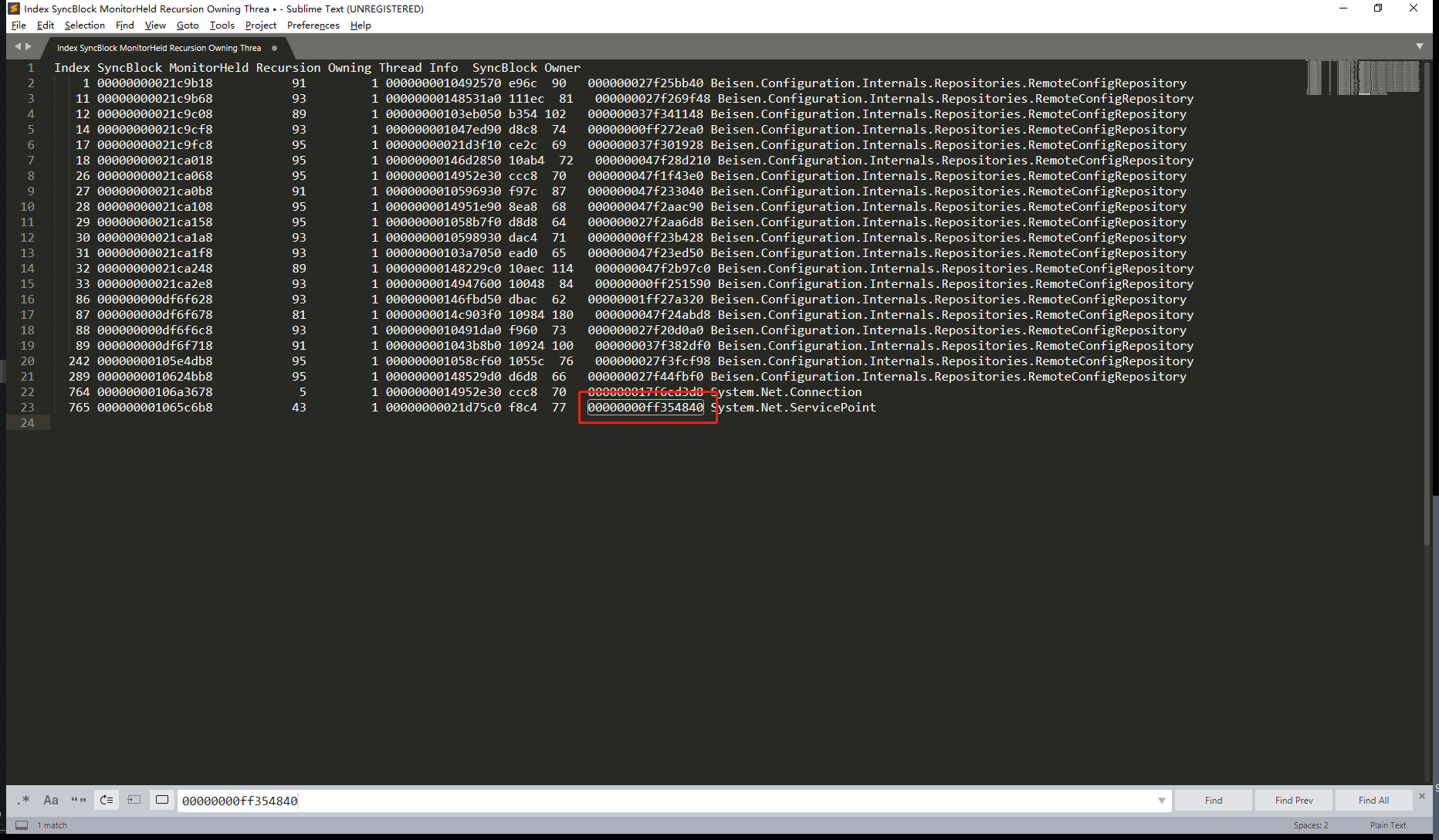
果然是锁对象,也就是说90号线程应该是在等77号线程。那么77号线程在等什么?切到77号线程,然后打印上下文。
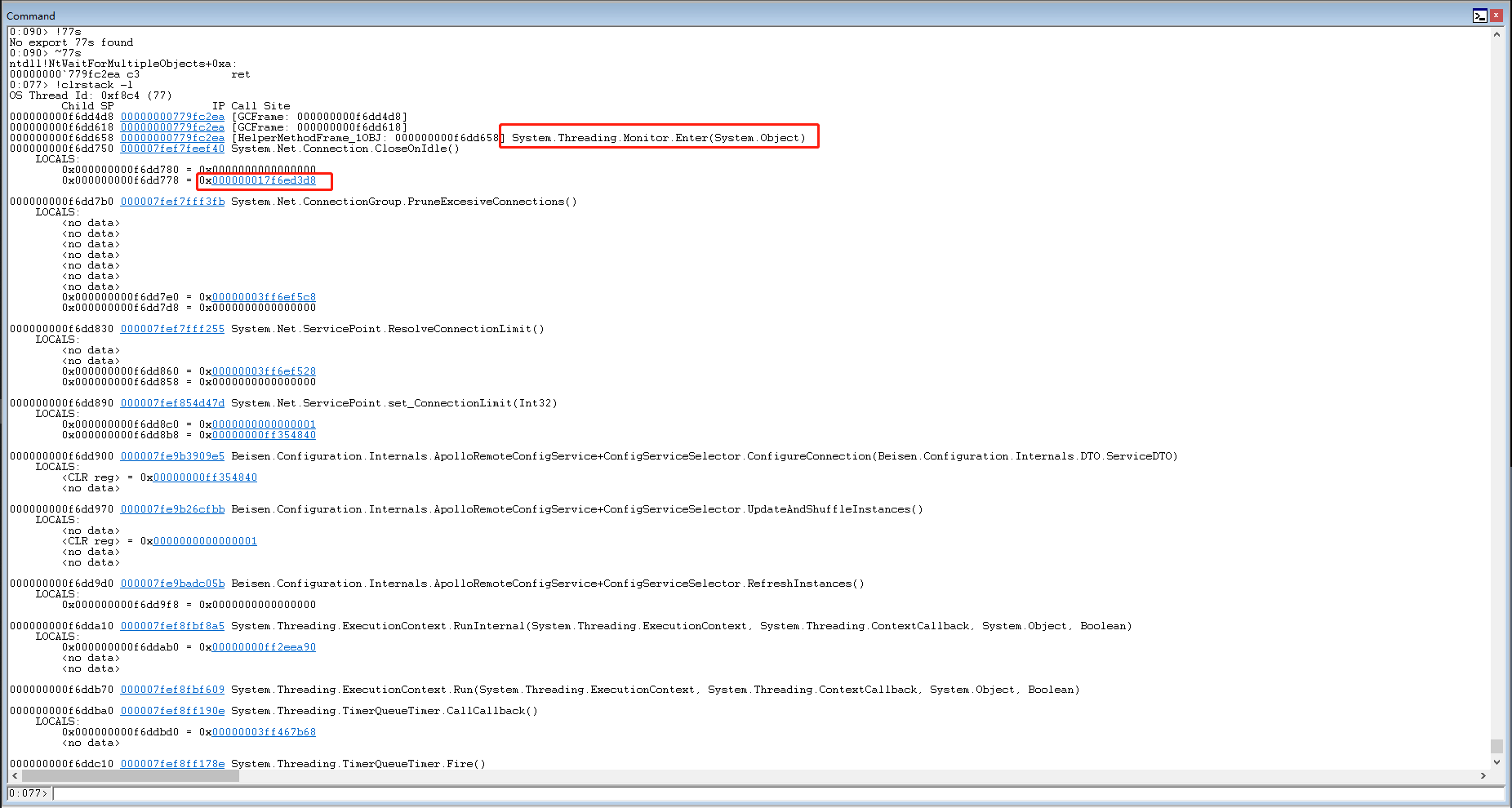
发现也是类似的情况,最后在申请锁。我们再查一下这个锁是什么情况。
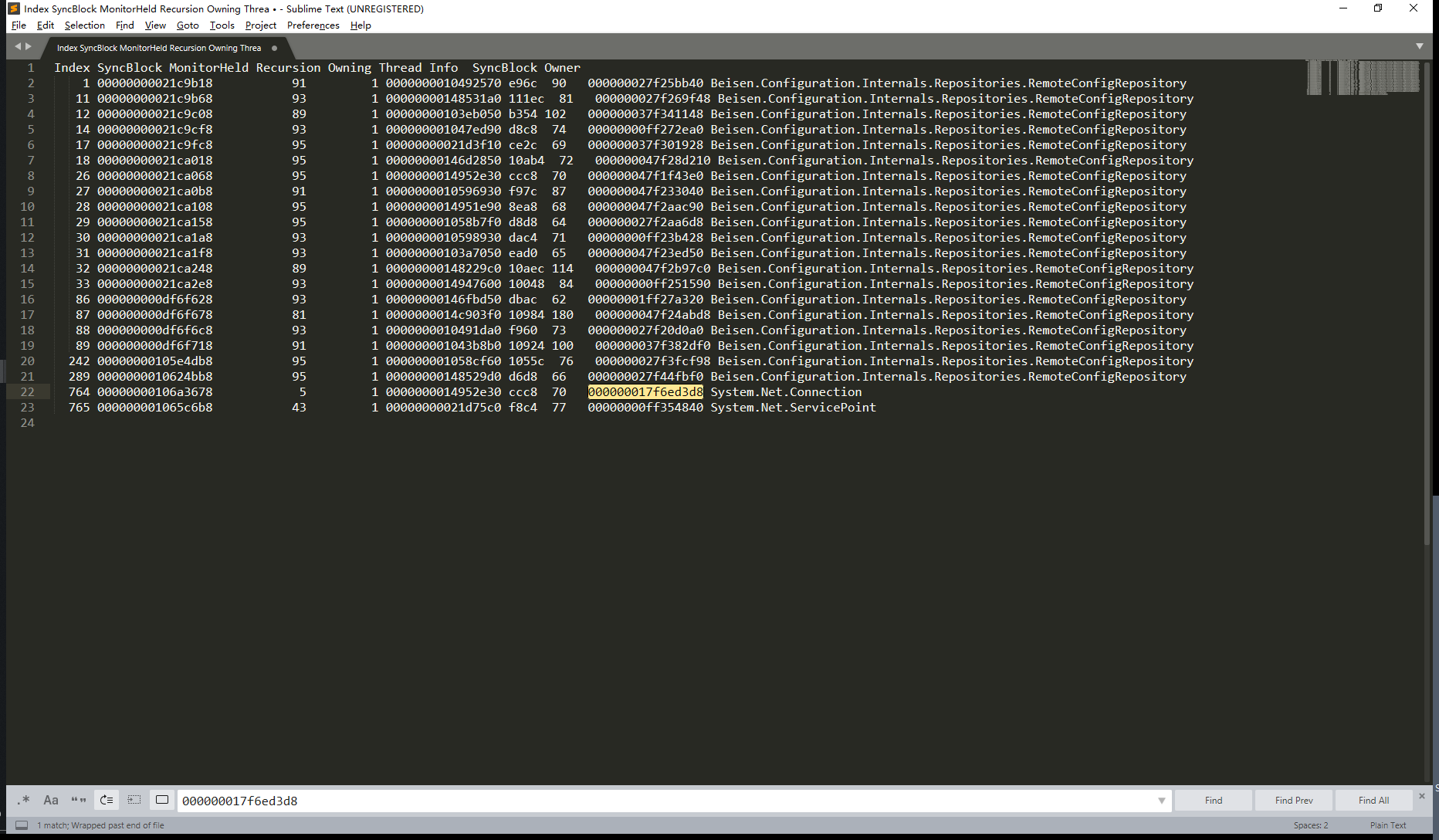
77号在等70号线程。那么70号线程在等谁?切换上下文到70号线程,然后打印上下文。

发现他也在等一个锁对象,我们查一下这个锁对象的拥有者是咋回事。
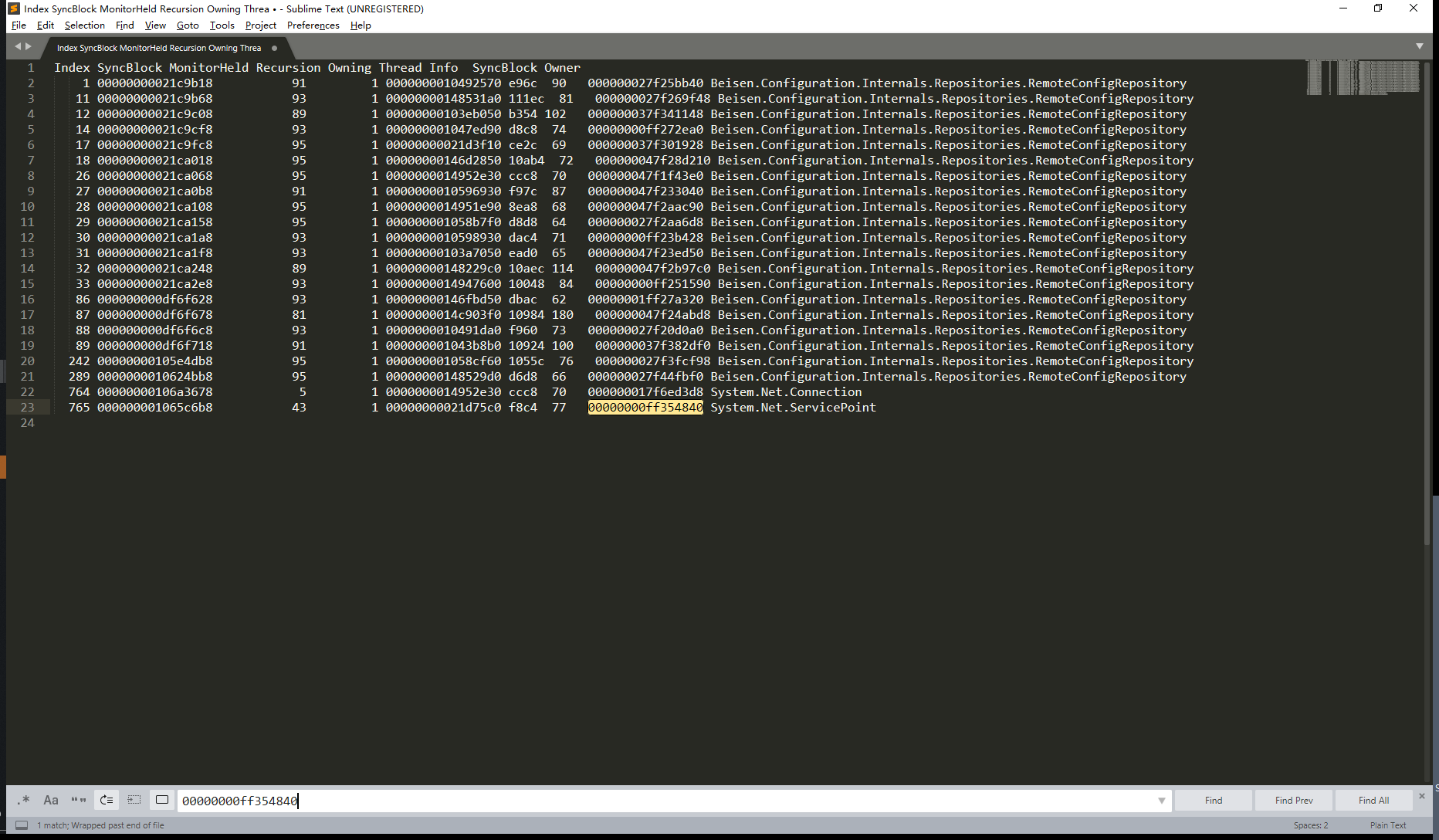
我们发现 70线程在等77号。那么现在70号跟77号在相互等待,那么这两个也就死锁了,其他的相关线程大概率都是跟这个死锁相关的。既然是这样,我们分别打印一下77号和70号相关的调用堆栈,就可以对比着代码查一下,为什么会出现死锁了。
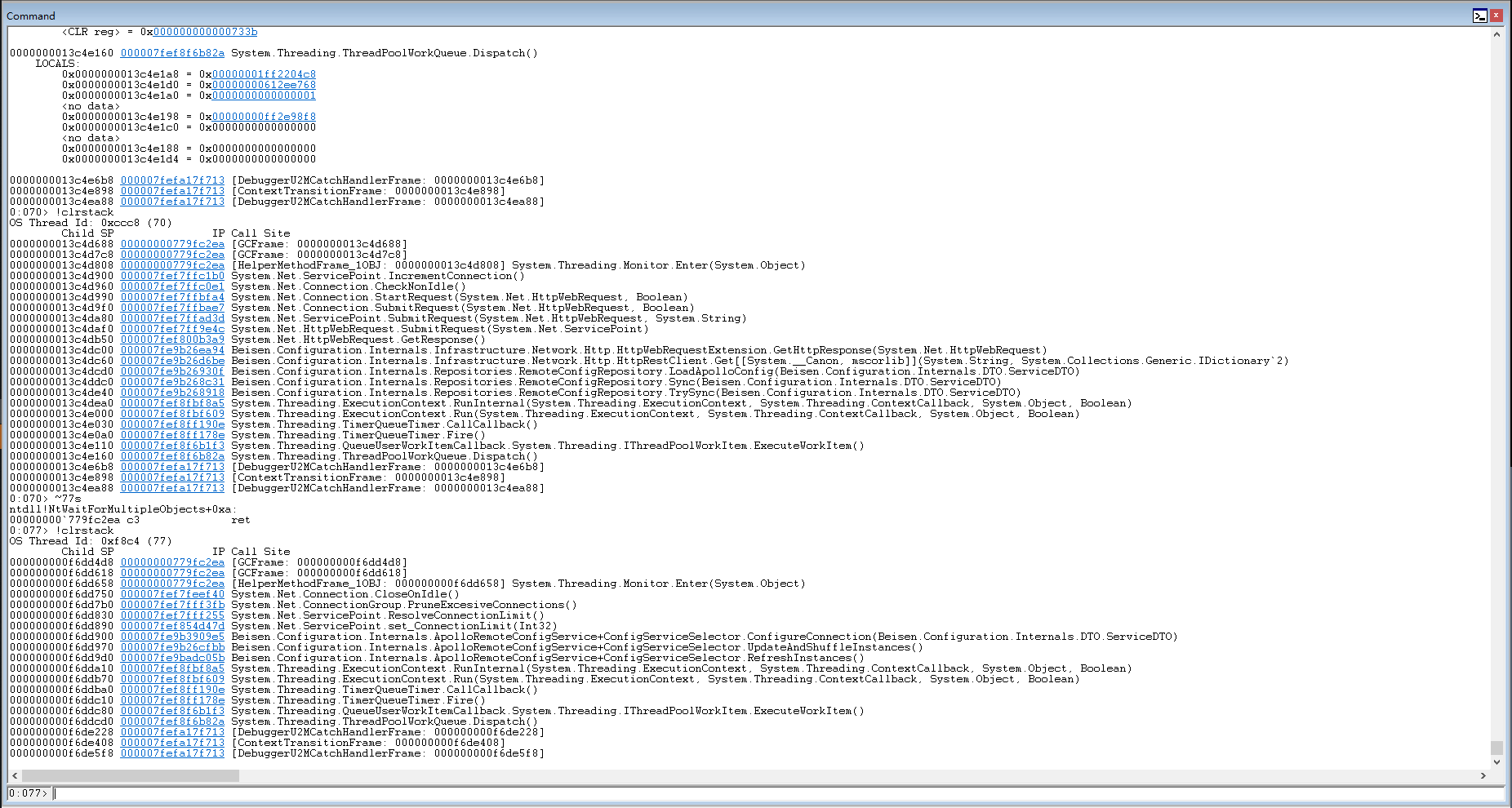
从这个函数名字上看很大概率是IncrementConnection和CloseOnIdle函数发生了死锁的情况,上下文其实也算是相关的。剩下的就只能对比代码,为什么这两个函数可能发生死锁了。
