视觉识别入门之人脸识别————
基于FACENET的高精度人脸识别
一:项目展示:
-

这是实时视频读取的展示,是可以读单张图片,或者本地视频流,抑或是实时人脸检测与分类的,至于我为什么不展示我的自拍,主要原因是因为太丑了hhhh
本文中我吧我暂且把我的模型称作为:孩子,因为机器学习,深度学习,实际是一个拟人的过程,通俗的说,就是我们的小时候,什么都不会,妈妈一个一个教你认字,久而久之,你就认识了一些字了,也就是著名的 有监督机器学习。这些概念类的科普,后期会给大家全面科普的,请多多关注!
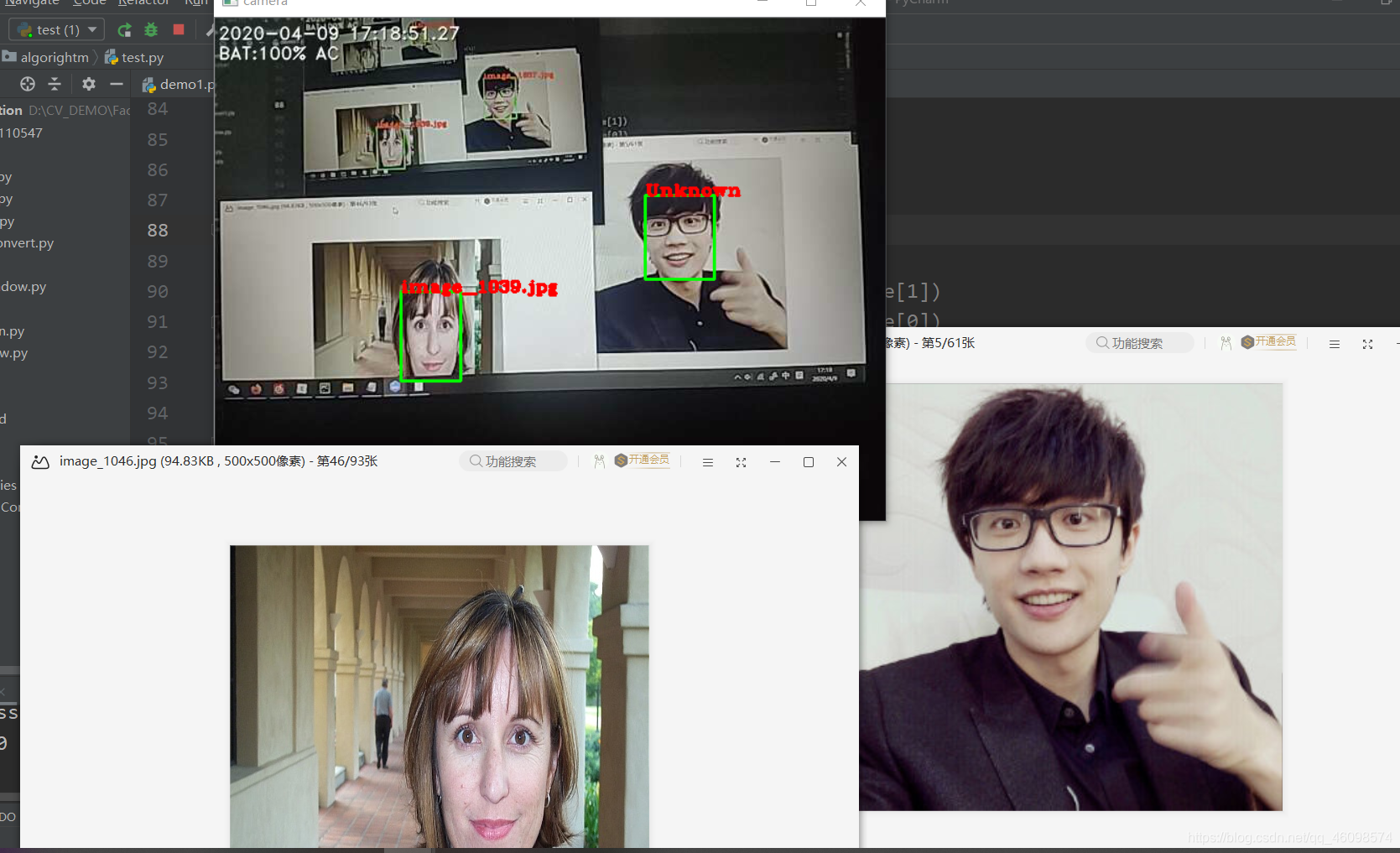
解读一下,左边的图片的是一个著名的博士,可能大家不熟悉,不过不重要,我的项目中让他充作正例学习样本,也就是,我想让我的孩子认识的人,我只“教会了”孩子认识几个人,比如这个博士,和我(我的照片是暂时不放出来滴),然后图片的右边是我孩子不认识的歌手——许嵩,
项目的目的很简单,现在还没有完善(请期(因)待(为)后(我)续(菜)),就只有简单的识别人脸而已,如果我的孩子不认识这个人,那么就会标注出“UNKNOWN”,如果他认识这个人,像这个博士,他就会给出他的名字(我姑且用这个博士的文件名代替名字)
如图中,他都正确识别了,经过我的反复测试,实时的准确率是很高的,纵使是在昏暗的情况下,
只要你露出来了一张脸,亦或者你带上了口罩,戴上了眼镜,张了嘴巴,我的孩子都认识,实话说,还是挺聪明的,好下面我们来解读一下内容:(关注博主,后续项目会分享出来,需要的兄弟自提吧!)
这边几张图片都是,左边的博士们,我得孩子是认识的,许嵩,他还太嫩了,我暂且还没教我孩子认~
首先,很高兴在这里与大家相遇,这是我个人的第三篇博客,我会按时更新,与大家一起进步,我现在是真实地菜鸡,但是,学习是我的信仰,大家有缘相遇,记的关注再走哟!
facenet是谷歌的一篇很有名的论文和开源项目,其实现了将输入的人像最终转换为shape为1*128的向量,然后通过计算不同照片之间的欧几里得距离(俗称欧氏距离)来判断他们的相似度,当然其中还包含许多技巧以及创新的想法,最终的在lfw(一个很有名的人脸数据库)准确率达到99.60%左右,在后面我会尽可能的解读其论文和代码中的有意思的想法
mtcnn是一个用来检测图片中人脸位置(人脸检测)的深度学习模型,其使用了三个卷积网络实现了对图像中人脸的检测,在后面再具体的介绍其实现的细节
基于lfw的训练集: 正例样本 :100张(4个人图像)size:500x500(便于识别与快速加载)
负例样本:13700 张来自facenet官网
训练前的准备:加载图片集:
def load_data(data_dir):
data = {}
pics_ctr = 0
for guy in os.listdir(data_dir):
person_dir = pjoin(data_dir, guy)
curr_pics = [read_img(person_dir, f) for f in os.listdir(person_dir)]
data[guy] = curr_pics
return data
我将这一万多张图片按照比例分出了三成的验证集:
X_train, X_test, y_train, y_test = train_test_split(train_x, train_y, test_size=.2, random_state=42)
使用mtcnn模型获取每张图片中人脸的数量以及位置,并将得到的embdding数据储存,后续会介绍embdding嵌入层
for x in data[keys[0]]:
_, images_me, i = load_and_align_data(x, 160, 44, 1.0)
if i:
feed_dict = {images_placeholder: images_me, phase_train_placeholder: False}
emb = sess.run(embeddings, feed_dict=feed_dict)
for xx in range(len(emb)):
train_x.append(emb[xx, :])
加载完图片后使用KNN(无监督机器学习中的K邻近算法,用的K-means++)这些依旧后续介绍
def knn_classifier(train_x, train_y):
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_jobs=-1)
model.fit(train_x, train_y)
return model
model = knn_classifier(X_train, y_train)
predict = model.predict(X_test)
accuracy = metrics.accuracy_score(y_test, predict)
print('accuracy: %.2f%%' % (100 * accuracy))
这时,我们查看一下accuracy用的大致3000多张的验证集进行识别:
然后模型持久化操作,保存一下模型就行,
训练时间不长,然后我们介绍实际使用模块
开始识别模块,先定义好几个参数分别是:图片最小尺寸,阈值(拿来识别用的),和切割尺寸:
minsize = 20
threshold = [0.6, 0.7, 0.7]
factor = 0.709
bounding_boxes, _ = align.detect_face.detect_face(img, minsize, pnet, rnet, onet, threshold, factor)
然后使用tensorflow 的session进入“上下文”并加载模型:facenet模型和我们的训练好的KNN模型:
with tf.Graph().as_default():
with tf.Session() as sess:
# 加载模型
facenet.load_model(model_dir)
images_placeholder = tf.get_default_graph().get_tensor_by_name("input:0")
embeddings = tf.get_default_graph().get_tensor_by_name("embeddings:0")
phase_train_placeholder = tf.get_default_graph().get_tensor_by_name("phase_train:0")
model = joblib.load('../models/knn_classifier.model')
接下来就开始识别了
首先加载摄像头:
def run():
# 开启ip摄像头
# video = 0
# 参数为0表示打开内置摄像头,参数是视频文件路径则打开视频
video = 'http://admin:[email protected]:8081/' # 我自己手机摄像头ip
capture = cv2.VideoCapture(video)
cv2.namedWindow("camera", 1)
c = 0
num = 0
frame_interval = 3 # frame intervals
while True:
ret, frame = capture.read()
这里我依旧用的自己的手机摄像头,因为电脑的内置摄像头不是很清晰(因为谁会用电脑摄像头拍照呢?)
det, crop_image, j = load_and_align_data(img, 160, 44, 1.0)
if j:
feed_dict = {images_placeholder: crop_image, phase_train_placeholder: False}
emb = sess.run(embeddings, feed_dict=feed_dict)
for xx in range(len(emb)):
print(type(emb[xx, :]), emb[xx, :].shape)
detect_face.append(emb[xx, :])
detect_face = np.array(detect_face)
detect_face = detect_face.reshape(-1, 128)
predict = model.predict(detect_face)
最后就是识别结果与数据标注了:
for i in range(len(predict)):
if predict[i] == 1000:
result.append('Unknown')
else:
try:
result.append(list(dict.keys())[list(dict.values()).index(predict[i])])
except:
result.append('Unknowns')
绘制矩形框,添加文字(其中也可以换成中文识别,我暂时还没有做):
for rec_position in range(len(det)):
cv2.rectangle(frame, (det[rec_position, 0], det[rec_position, 1]),
(det[rec_position, 2], det[rec_position, 3]), (0, 255, 0), 2, 8, 0)
cv2.putText(
frame,
result[rec_position],
(det[rec_position, 0], det[rec_position, 1]),
cv2.FONT_HERSHEY_COMPLEX_SMALL,
0.8,
(0, 0, 255),
thickness=2,
lineType=2)
其中数据标注部分,我是自己思考了一些时间的,用的将数据字典方式,把标签和名字串起来,比如:
labels = os.listdir(datas)
labels_num = []
i = 0
for i in range(len(labels)):
labels_num.append(i)
i += 1
list2 = labels
list3 = labels_num
dict = {}
i = 0
length = len(list2)
while i < length:
dit = {list2[i]: list3[i]}
dict.update(dit)
i += 1
训练的时候,加载相应的标签,根据返回值,来显示图像的名字,下面是验证集的准确率:

我的项目配置: tensorflow -gpu 1.14 (另外需要安装CUDA/cuDNN) scipy -1.2.1 numpy -1.16.2
我的调优: 1:启动gpu环境(os.environ[“CUDA_VISIBLE_DEVICES”] = ‘0’)总时间50秒。
2:解决人脸识别中的名字显示问题:使用了数据字典做的映射(因为做训练的时候传入的只能是0,1,2等数字)后期对于显示真正的名字,只需要把训练集中正例图片名称修改就行,中文显示名字也只是方法问题(可以实现)
3:多线程启动程序和ui 界面(暂未完善)
4:优化首选: 1:换显卡高的电脑运行 2:启动多线程多进程 训练 和 预测 和 使用 , 3:分布式训练(模型并行和数据并行(首选)两种方法) ,4:租GPU版服务 器,或找学校实验室资源
一不小心,这边文章,就要结尾了,上述是项目的简介,很大程度上说,人脸识别已经被大牛们玩烂了,我作为一个初学者,自然得碰一碰了,初期,自己遇到了很多困难,不断地 发现问题 解决问题 又制造问题的过程,其中,也参考了很多朋友的文章,很多的论文,文中参考了一些朋友的意见,很代码,我也在此提出感谢,我是站在巨人的肩膀上希望有一天会超越巨人!项目中,facenet也是封装的很完美,自己目前是没有能力修改 的,至于自己搭建神经网络,我也不是很熟悉,自己只搭过几次,效果,自然没有专家们做的好,以后熟练了,就要开始研究底层结构了,地基是项目的核心。

自己码了这么多字了,希望又朋友喜欢,正如我得标签:喜欢的事,努力去做就行了!另外,想要代码来跑一跑的同学们,可以关注博主,再私信我哟,或者过段时间会开源的。大佬看到我得文章也不要笑,初学~
有缘人!既然都划到最后了有缘人是否可以留下一个关注呢~
又是梦想成为大博主的一天:2020年4月9日
上海第二工业大学智能科学与技术大二学子
不甘心做XX调包侠的:周小夏
