《相见你》短评分析
前几天,女朋友一直在追想见你这个台剧,然后去豆瓣搜了一下,看到了评分竟然高达9.2分

想想我以前做的那些分析,所以就做一个简单的数据分析来分析一下想见你这部电视剧
爬取短评和评分
其实豆瓣作为爬虫新手联系已经够无奈了,后来豆瓣从根源上避免爬虫,在豆瓣短评上只会显示500条短评
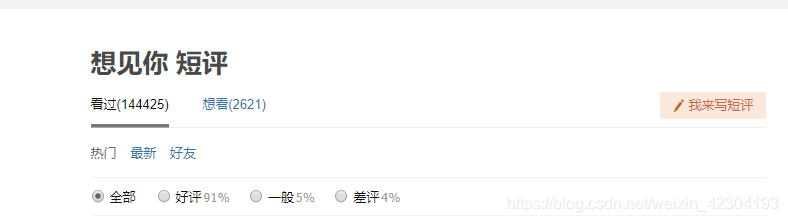
这里可以看到短评有14多万条,但是你不断下一页就可以发现,最多只会显示到500条,而我觉得非常的无奈,然后就去找了时光网、猫眼等等的影评,但是最多也就是凑齐了1600多条影评和评论,下面只演示一下在豆瓣的爬虫
import requests
from lxml import etree
import pandas as pd
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36","Cookie":'ll="118281"; bid=EDNXYtW8L7w; __yadk_uid=RVvI1oTanjPtjRsv6HtGu4HIC6Kqovwu; __gads=ID=1a054006518de23e:T=1583498908:S=ALNI_MYt37CtrdWsoH7GS4Ybhlpz7wOEtw; ct=y; _vwo_uuid_v2=D308461F850E43F2F56AB5732A9A76C8D|1d99baae6ee74e400ec3c3c2c54ec9fe; push_doumail_num=0; push_noty_num=0; __utmc=30149280; __utmz=30149280.1583642326.4.4.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=(not%20provided); __utmc=223695111; ap_v=0,6.0; __utmz=223695111.1583661503.7.5.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=(not%20provided); dbcl2="213145170:iSkk3Xy0Uoc"; ck=PhDl; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1583666031%2C%22https%3A%2F%2Fwww.douban.com%2Fsearch%3Fq%3D%25E6%2583%25B3%25E8%25A7%2581%25E4%25BD%25A0%22%5D; _pk_ses.100001.4cf6=*; __utma=30149280.1985249643.1583498911.1583661369.1583666031.7; __utmb=30149280.0.10.1583666031; __utma=223695111.1434622178.1583498925.1583661503.1583666031.8; __utmb=223695111.0.10.1583666031; douban-fav-remind=1; _pk_id.100001.4cf6=0b60581925fe7e5b.1583498925.7.1583666840.1583664038.'}
data_list = []
for e in ["h","m","l"]:
for i in range(25):
response = requests.get(
url="https://movie.douban.com/subject/30468961/comments?start={0}&limit=20&sort=new_score&status=P&percent_type={1}".format(str(i*20),e),
headers=headers).text
html = etree.HTML(response)
data = html.xpath("//div[@id='comments']/div[@class='comment-item']")
text = data[0].xpath("//div[@class='comment']/p/span[@class='short']/text()")
score = data[0].xpath("//div[@class='comment']/h3/span[@class='comment-info']/span[2]/@title")
date = data[0].xpath("//div[@class='comment']/h3/span[@class='comment-info']/span[3]/@title")
print(text)
for j in range(len(text)):
print("test")
data_dict = {}
data_dict["comment"] = text[j].strip().replace("\n","")
if(score[j] == "很差"):
data_dict["score"] = 1
elif(score[j] == "较差"):
data_dict["score"] = 2
elif(score[j] == "还行"):
data_dict["score"] = 3
elif(score[j] == "推荐"):
data_dict["score"] = 4
elif(score[j] == "力荐"):
data_dict["score"] = 5
try:
data_dict["date"] = date[j]
except:
data_dict["date"] = "0000-00-00 00:00:00"
data_list.append(data_dict)
print(text[j].strip().replace("\n",""))
data_frame = pd.DataFrame(data_list)
代码逻辑,首先是请求头,先要伪装成浏览器来访问,不然很容易就会被封,
然后循环访问url地址,获取的数据进行xpath表达式来处理,获取到评论内容,评论时间,和评分,因为有些评论没有时间,所以要加一个错误处理来处理掉没有时间的评论。
人物出场次数
在评论在分析每个人物的出场次数,也就是在评论区出现的次数,来表达观众对某个演员或者是某个角色的关注。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 先分析演员的出现次数
class Hero_time(object):
def __init__(self):
self.a_1 = ['柯佳嬿', '黄雨萱', '陈韵如','佳嬿','雨萱','韵如','女主','女主角']
self.a_2 = ['严艺文', '吴瑛婵', '艺文', '瑛婵']
self.a_3 = ['郭文颐', '昆布','文颐']
self.a_4 = ['林子珊', '小黛', '子珊']
self.a_5 = ['张毓晨', '毓晨', '娜姐']
self.a_6 = ['曾之乔', 'Sunny老师', 'sunny老师', 'Sunny', 'sunny']
self.a_7 = ['朱芷莹', '杨碧云', '芷莹', '碧云']
self.a_8 = ['简廷芮', '廷芮', 'Vicky', 'vicky']
self.a_9 = ['马惠珍', '惠珍', '莫奶奶']
self.a_10 = ['梁洳瑄','蔡旻柔','洳瑄','旻柔']
self.a_11 = ['江少仪', '诠胜母', '诠胜妈妈','男主的妈妈']
self.b_1 = ['许光汉', '王诠胜', '李子维', '光汉', '诠胜', '子维','男主','男主角']
self.b_2 = ['施柏宇', '莫俊杰', '柏宇', '俊杰']
self.b_3 = ['颜毓麟', '谢宗儒', '谢芝齐', '毓麟', '宗儒', '芝齐']
self.b_4 = ['张翰', '吴文磊', '文磊']
self.b_5 = ['林鹤轩', '陈思源', '鹤轩','思源']
self.b_6 = ['陈匡荣', '阿财', '匡荣']
self.b_7 = ['徐诣帆', '诣帆', '教官']
self.b_8 = ['连晨翔', '阿哲', '晨翔']
self.b_9 = ['黄鸿升', '杜齐闵', '鸿升','齐闵']
self.b_10 = ['邱胜翊', '颜力正', '力正', '胜翊', '王子']
def read_comments(self):
data = pd.read_csv("I:/crack/DATA/want_see.csv",encoding="utf_8_sig")
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 200)
pd.set_option('display.max_colwidth', 1000)
comments = data['comment']
return comments
def counts(self,heros,hero_name):
count = 0
for i in self.read_comments():
for name in heros:
if name in i:
count +=1
else:
continue
comment_1 = {"英雄名称":hero_name,"出现次数":count}
return comment_1
def all_hero(self):
list = []
list.append(self.counts(self.a_1,"柯佳嬿"))
list.append(self.counts(self.a_2, "严艺文"))
list.append(self.counts(self.a_3,"郭文颐"))
list.append(self.counts(self.a_4,"林子珊"))
list.append(self.counts(self.a_5,"张毓晨"))
list.append(self.counts(self.a_6,"曾之乔"))
list.append(self.counts(self.a_7,"朱芷莹"))
list.append(self.counts(self.a_8,"简廷芮"))
list.append(self.counts(self.a_9,"梁洳瑄"))
list.append(self.counts(self.a_10, "马惠珍"))
list.append(self.counts(self.a_11, "江少仪"))
list.append(self.counts(self.b_1, "许光汉"))
list.append(self.counts(self.b_2, "施柏宇"))
list.append(self.counts(self.b_3, "颜毓麟"))
list.append(self.counts(self.b_4, "张翰"))
list.append(self.counts(self.b_5, "林鹤轩"))
list.append(self.counts(self.b_6, "陈匡荣"))
list.append(self.counts(self.b_7, "徐诣帆"))
list.append(self.counts(self.b_8, "连晨翔"))
list.append(self.counts(self.b_9, "黄鸿升"))
return list
def draw(self):
hero_counts = self.all_hero()
data = pd.DataFrame(hero_counts).sort_values('出现次数',ascending=False)
data_time = data['出现次数']
data_hero = data['英雄名称']
x = data_hero.values
y = data_time.values
#设置中文字体
plt.rcParams['font.family'] = 'SimHei'
# 设置x刻度
plt.xticks(range(len(x)), x,rotation=45)
#绘图
rect = plt.bar(range(len(x)),y,width=0.5,label="测试豆瓣评论,各英雄出现的次数可视化")
plt.xticks(range(len(x)),x)
plt.legend()
plt.show()
def main():
test = Hero_time()
test.draw()
if __name__ == '__main__':
main()
结果

虽然很多人都说男主因为这部电视剧比较红,但是从分析中看出,观众对女主的关注度比较高,其次都是男演员比较受关注,可能是因为女观众比较多吧,而且几个男演员也是比较帅的。
评论云图
import pandas as pd
import wordcloud
import jieba
from cv2 import imread
from PIL import Image
from os import path
import numpy as np
import matplotlib.pyplot as plt
data = pd.read_csv("I:/crack/DATA/want_see.csv",encoding="utf_8_sig")
comment = data["comment"].tolist()
world_all = "".join(comment)
word_list = jieba.cut(world_all,cut_all=False)
txt = "".join(word_list)
w = wordcloud.WordCloud(font_path = "I:crack/font/msyh.TTF",width = 1000,height = 700,background_color = "Pink") #这个是配置词云设置
w.generate(txt)
plt.imshow(w, interpolation="bilinear")
plt.show()
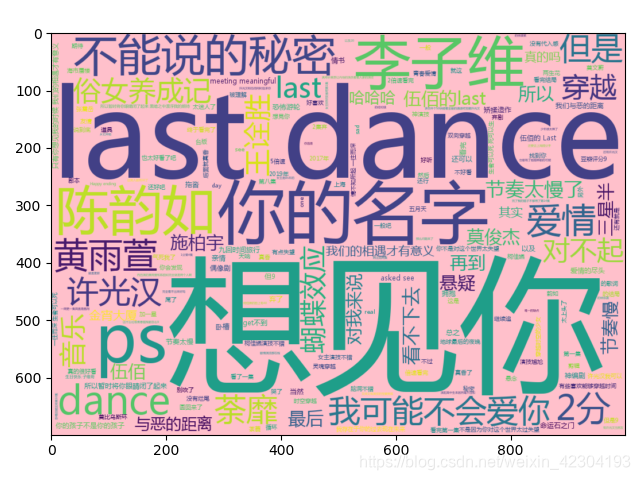
从云图中看出,除了电视剧的名字,在评论区出现比较多的还是,伍佰的歌,因为我女朋友在看想见你的时候我也是听到这首歌比较多。shou
其次出现比较多的是“你的名字”,我还不知道评论区出现这么多的这个词是为什么,然后比较受关注的角色是 李子维和陈韵如。
评分分布
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from collections import Counter
data = pd.read_csv("I:/crack/DATA/want_see.csv",encoding="utf_8_sig")
plt.rcParams['font.family'] = 'SimHei'
socre = data["score"].tolist()
socre_dict = Counter(socre)
socre_data = []
labels = []
for key,value in socre_dict.items():
socre_data.append(value)
labels.append(str(key) + "分")
plt.pie(socre_data,labels=labels,autopct = '%1.1f%%',shadow=True,startangle=90,radius=1.2,pctdistance=0.7,labeldistance=1.1,wedgeprops={'linewidth':5},textprops={'fontsize':16,'color':'w'})
#设置标题
plt.title('评分图')
# 将横、纵坐标轴标准化处理,保证饼图是一个正圆,否则为椭圆
plt.legend(loc='upper right')
plt.show()
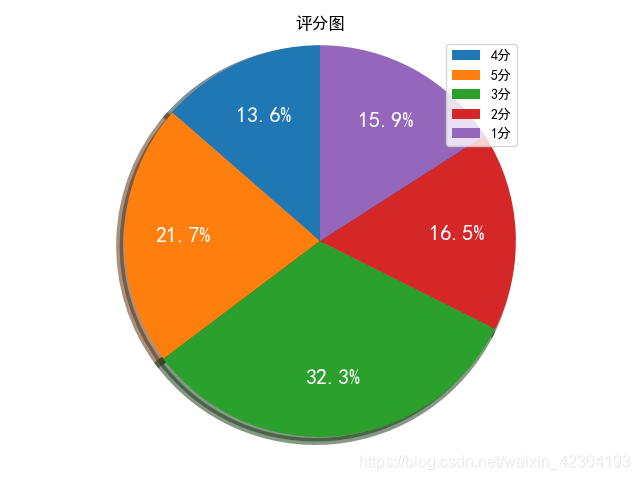
这次分析的短评都主要是热门的评论,所以可以看到评分分布的状态还是3星的评分比较多,虽然豆瓣评分是9.2分,但是可能大部分观众还是觉得中等吧
