数据批次表:
public class SmsMarkBatch {
private Long id;
private String batchname;
private String inittype;
private Integer smscount;
private Integer typemarkcount;
private Integer entitymarkcount;
private Date insertdate;
private String reserved;
}
待标注数据表
public class SmsMark implements Cloneable {
private Long id;
private String smscontent;
private Integer realcount;
private String inittype;
private String realtype;
private String entitymarksms;
private Boolean ismarkentity;
private Boolean ismarktype;
private Integer batchid;
private String typemarkaccount;
private String entifymarkaccount;
private String reserved;
标注系统介绍:
可以完成对文本的类别标注和实体标注。但不是完全从空白开始标,事先有一个预标签,预实体。这是我们的模型生成的。传入这样的数据好处就是可以在模型标注后的基础上修改,减少操作。
标注策略:
优先标注同一个批次的数据。可供模型训练。那我们标注系统返回给用户的标注数据就是,先根据用户选择的预标签,还有想标什么,找到未完成标注的批次,再根据批次,预标签,labelWhat返回给用户一条标注数据。同时也会返回给用户当前批次的一些标注情况,如当前批次,已经完成多少条标注了,还差多少
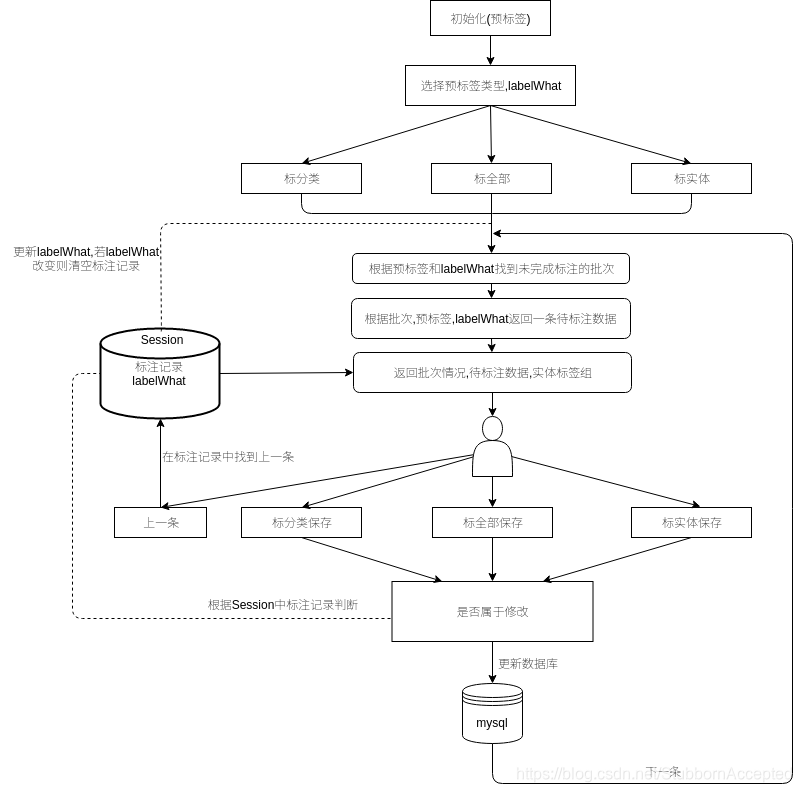
一.获取待标注数据
获取逻辑:
1.获取一个没标注完的批次
2.根据这个批次的id,获取一条这个批次中还没有标完的数据。
问题1:
如果多个用户取到同一条数据,造成重复标注,丢失修改,浪费工作量的问题。
解决:
当用户取到数据后,将该条数据的某个预留字段设置为inmarking.取数据时将inmarking的数据过滤掉.然后在进行标注。
问题2:
这样做又会引发这样的问题:我们优先标注同一批次的数据,先根据批次取数据,会取标注数量小于实际数量的批次;再从这个批次里取待标注数据。但由于获取待标注数据时已经过滤掉inmarking的数据,所以取不到数据导致返回为空.将永远卡在 当前批次没标注完,但又取不到待标注数据 无法跳转到下一个批次.的尴尬情景中。
解决:
设置一个尝试次数。获取到一个标注数量小于实际数量的未完成的批次后,循环尝试从这个批次里取标注数据,如果能直接取到就更好了。如果取不到,是因为剩余数据都是处于inmarking的状态。尝试了n次,我们就需要将这个批次再标识一下complete,代表这个批次虽然标注数量小于实际数量的批次,但由于存在inmarking的数据,我们就不管它们了。直接跳到下一个批次。 取批次时,注意过滤掉complete标识的。
二.保存标注结果
一方面要更新 标注数据表:
sms.setType("~~~");
sms.setTypeIsMark(true);
smsMark.update(sms);
另一方面要更新 当前批次标注数量
问题:
在多用户并发修改同一个批次的标注数据量时,后提交的将覆盖掉先提交的结果,造成计数错误。
解决:
1.悲观锁(适用于并发量很高)
对当前批次的这条记录加排他锁。
select id,typemarkcount from smsMarkBatch where id="666" for update;
#加排他锁,阻塞其它事务
update smsMarkBatch set typemarkcount=typemarkcount+1 where id="666";
2.乐观锁(适用于并发量不高,因为加锁也消耗性能)
设计一个版本号字段,每次修改使其+1,再提交时对比提交前的版本号就知道是不是并发提交了。
在这里,我们可以直接把标注数量作为版本号,不用额外设置;
select id,typemarkcount as oldcount from smsMarkBatch where id="666" ;
#不加锁,这里是共享锁,所有事物读到的是同一个结果
update smsMarkBatch set typemarkcount=oldcount+1 where id="666" and typemarkcount=oldcount;
#只有表中 数量等于之前获取的数量时才可以更新
如果修改失败了,就自旋尝试。
思考:
这个问题跟防止库存超卖是一样的。
但在秒杀情况下,肯定不能如此高频率的去读写数据库,会造成很严重的性能问题。
秒杀时的常用解决方案:启用数据缓存层,避免高频率的去读写数据库
在秒杀的情况下,肯定不能如此高频率的去读写数据库,会严重造成性能问题的
必须使用缓存,将需要秒杀的商品放入缓存中,并使用锁来处理其并发情况。当接到用户秒杀提交订单的情况下,先将商品数量递减(加锁/解锁)后再进行其他方面的处理,处理失败在将数据递增1(加锁/解锁),否则表示交易成功。
当商品数量递减到0时,表示商品秒杀完毕,拒绝其他用户的请求。
比如:把你要卖出的商品比如10个商品放到缓存中;然后在memcache里设置一个计数器来记录请求数,这个请求书你可以以你要秒杀卖出的商品数为基数,比如你 想卖出10个商品,只允许100个请求进来。那当计数器达到100的时候,后面进来的就显示秒杀结束,这样可以减轻你的服务器的压力。然后根据这100个 请求,先付款的先得后付款的提示商品以秒杀完。
