如何使用netcdf包来读取NC文件
1.首先,你需要下载netcdf的jar包.这里给出官网地址,选择合适的下载.
官网地址:
https://www.unidata.ucar.edu/software/thredds/current/netcdf-java/documentation.htm
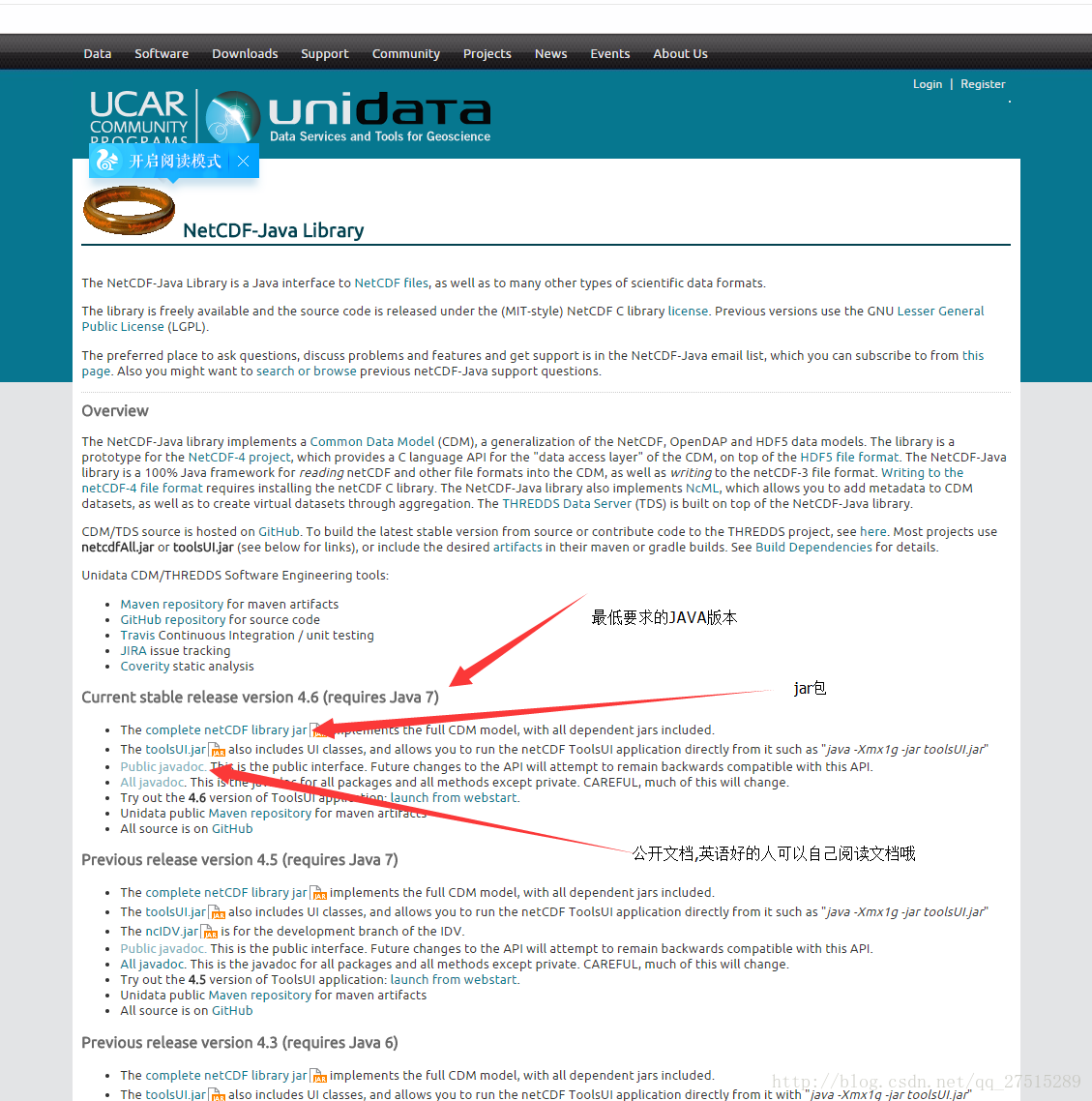
2.下载好jar包之后,导入eclipse之中
3.开始读取.nc文件
要读取NC文件,首先你需要了解它的结构.它是由一个个多维数组变量组成.简单的来说,就是如下图:
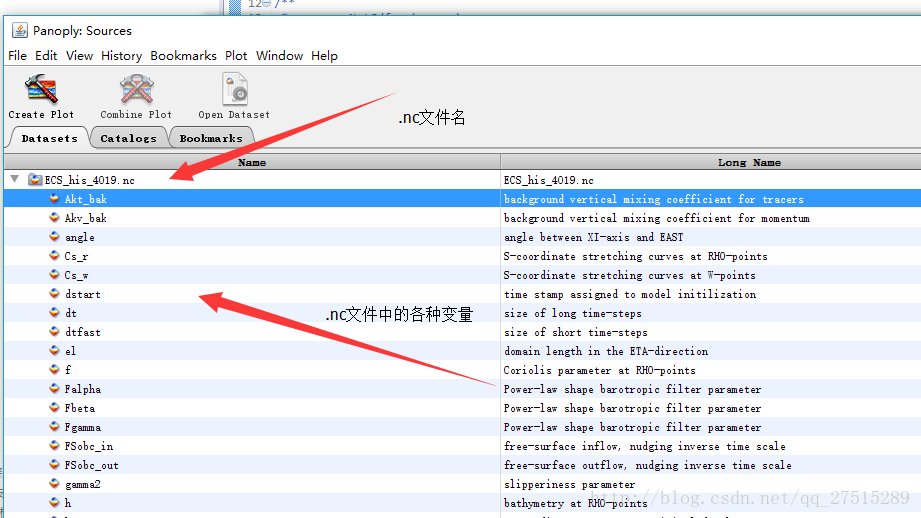
了解NC文件之后,在进行读取就方便多了
首先,打开文件
NetcdfFile openNC = NetcdfFile.open(filePath); //filePath:文件地址
Variable n = openNC.findVariable("n") //"n"这个方法是找到变量名称为n的变量取数据分为两种,一种是一维数据,一种是多维数据
取一维数据较为简单
例如n为一维数据,那么
float[] data = (float[]) n.read().copyTo1DJavaArray();例如n为五维数据,那么
double[][][][][] data = (double[][][][][]) n.read().copyTo1DJavaArray();这里需要特别注意,一般多维数据都很大,例如一个四维数据
double[24][32][500][300] 类型的数据需要占据24*32*500*300*64(double类型占用内存字节长度)个字节
换算为G就是6.8G.
也就是说,如果你一次性把这么多数据全读进数据库,那么你的jvm一定会报堆空间溢出错误.
这里就需要我们一部分一部分的来读取数据了
配置好维度起点,以及相应维度需要取多少条数据.这里需要好好权衡一下,因为频繁进行文件读取很费时间,但是一次性读取太多会造成堆空间溢出.
例如我要读取数据double[24][32][500][300],那么我可以一维一维的读
int[] org = {0,0,0,0};
int[] sha = {1,32,500,300};
double[][][][][] data = (double[][][][][]) n.read(org,sha).copyTo1DJavaArray();这样,我循环24次就可以将数据全读出来,每次占用内存大小为292Mb,在可接受范围内.
org参数表示每一维的起点,sha表示相应维读取的条数
例如第一次读完后,读取第二次则设置为
int[] org = {1,0,0,0};
int[] sha = {1,32,500,300};
double[][][][][] data = (double[][][][][]) n.read().copyTo1DJavaArray();最后得到的data数据就是我们需要的.nc文件中的数据
最后的最后,一定一定记得关闭文件.
openNC.close()