对于 CPU 主要关注平均负载(Load Average),CPU 使用率,上下文切换次数(Context Switch)。
平均负载有三个数字:63.66,58.39,57.18,分别表示过去 1 分钟、5 分钟、15 分钟机器的负载。按照经验,若数值小于 0.7*CPU 个数,则系统工作正常;若超过这个值,甚至达到 CPU 核数的四五倍,则系统的负载就明显偏高。
在Linux中,CPU主要用于 中断、内核进程以及用户进程的任务处理,优先级为:中断 > 内核进程 > 用户进程,在学习如何分析CPU消耗状况前,有三个重要概念交代一下。
上下文切换
每个CPU(或多核CPU中的每核CPU)在同一时间只能执行一个线程。 Linux采用的是抢占式调度:即为每个线程分配一定的执行时间,当到达执行时间、线程中有IO阻塞或高优先级线程要执行时,Linux将切换执行的线程,在切换时要存储目前程序的执行状态PCB(Program Control Block),并恢复要执行的线程的状态,这个过程就称为上下文切换。
对于Java应用,典型的是在进行文件IO操作、网络IO操作、锁等待或线程Sleep时,当前线程会进入阻塞或休眠状态,从而触发上下文切换,上下文切换过多会造成内核占据较多的CPU使用,使得应用的响应速度下降。
上下文切换次数发生的场景主要有如下几种:
1)时间片用完,CPU 正常调度下一个任务;
2)被其它优先级更高的任务抢占;
3)执行任务碰到 I/O 阻塞,挂起当前任务,切换到下一个任务;
4)用户代码主动挂起当前任务让出 CPU;
5)多任务抢占资源,由于没有抢到被挂起;
6)硬件中断。
Java 线程上下文切换主要来自共享资源的竞争。一般单个对象加锁很少成为系统瓶颈,除非锁粒度过大。但在一个访问频度高,对多个对象连续加锁的代码块中就可能出现大量上下文切换,成为系统瓶颈
运行队列
每个CPU核都维护了一个可运行的线程队列,例如一个4核的CPU, Java应用中启动了8个线程,且这8个线程都处于可运行状态,那么在分配平均的情况下每个CPU中的运行队列里就会有两个线程。通常而言,系统的load主要由CPU的运行队列来决定,假设以上状况维持了1分钟,那么这1分钟内系统的load就会是2,但由于load是个复杂的值,因此也不是绝对的,运行队列值越大,就意味着线程要消耗越长的时间才能执行完。 Linux System and NewWork Performance Monitoring中建议控制在每个CPU核上的运行队列为1-3个。
利用率
CPU利用率为CPU在用户进程、内核进程、中断处理、IO等待以及空闲五个部分使用的百分比,这五个值是用来分析CPU消耗情况的关键指标。 Linux System and NewWork Performance Monitoring 中建议用户进程的CPU消耗/内核的CPU消耗的比例在 65%-70% / 30%-35%
Linux观测CPU消耗状态的工具:
perf、top、vmstat、pidstat、sar、pcpu、ps Hh -eo tid
工具 perf 性能测试工具
sudo apt-get install linux-tools-common
sudo apt-get install linux-tools-3.13.0-27-generic
工具top
用工具SSH登陆到Linux 上后,在字符界面下输入top命令后即可查看CPU的消耗情况,详情查看https://blog.csdn.net/glamour2015/article/details/105025304
linux下查看根据进程查看线程的方法
1、cat /proc/${pid}/status
2、pstree -p ${pid}
3、 top -Hp ${pid}
4、ps xH
H Show threads as if they were processes。这样可以查看所有存在的线程。
5、ps -mp
m Show threads after processes。这样可以查看一个进程起的线程数。
工具pidstat
pidstat 是SYSSTAT中的工具.,如需使用pidstat,请先安装SYSSTAT:http://www.icewalkers.com/Linux/Software/59040/sysstat.html
安装方法: root$ sudo apt-get install sysstat
pidstat 1 2,在console上将会每隔1秒输出目前活动进程的CPU消耗状况,共输出2次
pidstat -p [PID] -t 1 5 查看进程中线程的CPU消耗状况
较之top命令方式而言, pidstat的好处为可查看每个线程的具体CPU利用率的状况( 例如%usr 、%system
vmstat
vmstat采样(例如每秒 vmstat 1)查看CPU的上下文切换、运行队列、利用率的具体信息。
sar
sar来查看一定时间范围内以及历史的cpu消耗状况信息
CPU消耗分析
当CPU消耗严重时,主要体现在us、sy、wa 或 hi的值变高, wa的值是IO等待造成的,hi的值变高主要为硬件终端造成的,例如网卡接受数据频繁的状况。
关于cpu主要关注4个值:us(user), sy(system), wa(wait), id(idle)。理论上他们加起来应该等于100%。而前三个每一个值过高都有可能表示存在某些问题。
us过高:
a. 代码问题。比如一个耗时的循环不加sleep,或者在一些cpu密集计算(如xml解析,加解密,加解压,数据计算)时没处理好
b. gc频繁。一个比较容易遗漏的问题就是gc频繁时us容易过高,因为垃圾回收属于大量计算的过程。gc频繁带来的cpu过高常伴有内存的大量波动,通过内存来判断并解决该问题更好。
sy过高:
上下文切换次数过多。通常是系统内线程数量较多,并且线程经常在切换,由于系统抢占相对切换时间和次数比较合理,所以sy过高通常都是主动让出cpu的情况,比如sleep或者lock wait, io wait。
wa过高:
等待io的cpu占比较多。注意与上面情况的区别,io wait引起的sy过高指的是io不停的wait然后唤醒,因为数量较大,导致上下文切换较多,强调的是动态的过程;而io wait引起的wa过高指的是io wait的线程占比较多,cpu切换到这个线程是io wait,到那个线程也是io wait,于是总cpu就是wait占比较高。
id过高:
很多人认为id高是好的,其实在性能测试中id高说明资源未完全利用,或者压测不到位,并不是好事。
对于Java应用而言,CPU消耗严重主要体现在us、sy两个值上,分别看看Java应用在这两个值高的情况下应如何找到对应造成瓶颈的代码。
us (CPU的用户进程处理所占的百分比)
当us值过高时,表示运行的应用消耗了大部分的CPU. 在这种情况下,对于Java应用而言,最重要的是找到具体消耗CPU的线程及锁执行的代码。
pstree以树结构显示进程
寻找过程:
1.top/jps命令发现占用us较高,查看cpu消耗较高的进程Id
2.1 top -Hp 30420通过进程ID查找占用cpu过高的线程Id
2.2 pidstat -p 30420 -t 1 5 | less 找到消耗CPU多的线程Id
3.python -c ‘print hex(线程id)’ 把获取的线程Id转成16进制
4.jstack 30420|grep -C100x62fa 定位到线程池中的线程信息
4.1 jstack -30420 > jstack03.txt
从其代码可看出整个线程一直处于运行过程中,中途没有IO中断、锁等待现象,因此造成了CPU消耗严重。
但是如果在一个操作中循环调用了很多其他的操作,如果其他的操作每次都比较快,但由于循环太多次,造成了CPU消耗,在这种情况下jstack是无法捕捉出来的。可以使用pstack显示每个进程的栈跟踪
分析进程调用-pstack
通过top等工具发现系统性能问题是由某个进程导致的之后,接下来我们就需要分析这个进程;继续 查询问题在哪;
pstack用来跟踪进程栈,这个命令在排查进程问题时非常有用,比如我们发现一个服务一直处于work状态(如假死状态,好似死循环),使用这个命令就能轻松定位问题所在;可以在一段时间内,多执行几次pstack,若发现代码栈总是停在同一个位置,那个位置就需要重点关注,很可能就是出问题的地方;
示例:查看bash程序进程栈:
/opt/app/tdev1$ps -fe| grep bash
tdev1 7013 7012 0 19:42 pts/1 00:00:00 -bash
tdev1 11402 11401 0 20:31 pts/2 00:00:00 -bash
tdev1 11474 11402 0 20:32 pts/2 00:00:00 grep bash
/opt/app/tdev1$pstack 7013
#0 0x00000039958c5620 in __read_nocancel () from /lib64/libc.so.6
#1 0x000000000047dafe in rl_getc ()
#2 0x000000000047def6 in rl_read_key ()
#3 0x000000000046d0f5 in readline_internal_char ()
#4 0x000000000046d4e5 in readline ()
#5 0x00000000004213cf in ?? ()
#6 0x000000000041d685 in ?? ()
#7 0x000000000041e89e in ?? ()
#8 0x00000000004218dc in yyparse ()
#9 0x000000000041b507 in parse_command ()
#10 0x000000000041b5c6 in read_command ()
#11 0x000000000041b74e in reader_loop ()
#12 0x000000000041b2aa in main ()
而strace用来跟踪进程中的系统调用;这个工具能够动态的跟踪进程执行时的系统调用和所接收的信号。是一个非常有效的检测、指导和调试工具。系统管理员可以通过该命令容易地解决程序问题。
参考: strace 跟踪进程中的系统调用 ;
sy (内核线程处理所占的百分比)
当sy值高时表示Linux花费了更多的时间在进行线程切换,Java应用造成这种现象的主要原因是启动的线程比较多,且这些线程多数都处于不断的阻塞(例如锁等待、IO等待状态)和执行状态的变化过程中,这就导致了操作系统要不断地切换执行的线程,产生大量的上下文切换。在这种状况下,对Java应用而言,最重要的是找出线程不断切换状态的原因,可采用的方法为通过 kill -3 [javapid] 或jstack -l [javapid] 的方式dump出java应用程序的线程信息,查看线程的状态信息以及锁信息,找出等待状态或锁竞争过多的线程。
- java -jar SyHighOfCpuDemo.jar ,运行java程序
- top/jps命令发现占用sy过高
- vmstat -n 3 执行一下看一下上下文切换情况
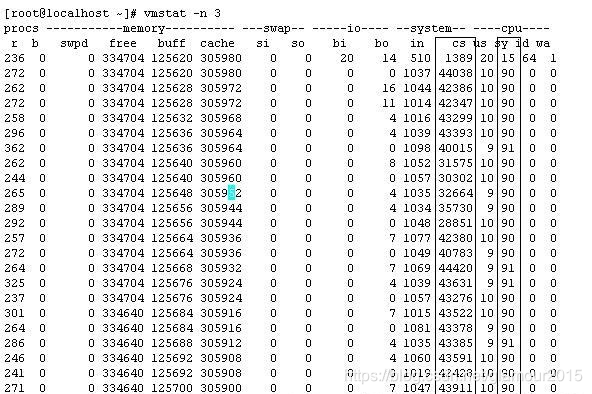
由上可知,CPU在cs(内核线程上下文切换) 以及sy上消耗很大。
- 运行时采用jstack -l 查看程序的线程状况,可以看到启动了很多线程,并且很多的线程都经常处于 TIMED_WAITING(on object monitor)状态、WAITING (on object monitor)和Runnable状态的切换中。
通过on object monitor对应的堆栈信息,可查找到系统中锁竞争激烈的代码,这是造成系统更多时间消耗在线程上下文切换的原因。
