作者:chen_h
微信号 & QQ:862251340
微信公众号:coderpai
当你嫌弃 Python 速度慢时
Python编程语言几乎可用于任何类型的快速原型设计和快速开发。它具有很强的功能,例如它的高级特性,具有几乎人性化可读性的语法。此外,它是跨平台的,具有多样性的标准库,它是多范式的,为程序员提供了很多自由,可以使用不同的编程范例,如面向对象,功能或者程序。但是,有时我们系统的某些部分具有高性能要求,因此 Python 提供的速度可能远远不够,那么,我们如何在不离开 Python 领域的情况下提高性能。
其中一个可能的解决方案是使用 Numba,这是一种将 Python 代码转换为机器指令的运行编辑器,同时让我们使用 Python 的简洁和表达能力,并实现机器码的速度。
什么是 Numba?
Numba 是一个执行 JIT 编译的库,即使用 LLVM 行业标准编译器在运行时将纯 Python 代码转换为优化的机器代码。它还能够自动并行化在多个核上面运行代码。Numba 是跨平台的,因为它适用于不同的操作系统(Linux,Windows,OSX)和不同的架构(x86,x86_64,ppc64le等等)。它还能够在GPU(NVIDIA CUDA 或者 AMD ROC)上运行相同的代码,并与 Python 2.7 和 3.4-3.7兼容。总的来说,最令人印象深刻的功能是它的使用简单,因为我们只需要一些装饰器来充分利用 JIT 的全部功能。
Numba模式和 @jit 装饰器
最重要的指令是 @jit 装饰器。正是这个装饰器指示编译器运行哪种模式以及使用什么配置。在这种配置下,我们的装饰函数的生成字节码与我们在装饰器中指定的参数(例如输入参数的类型)相结合,进行分析,优化,最后使用 LLVM 进行编译,生成特定定制的本机机器指令。然后,为每个函数调用此编译版本。
有两种重要的模式:nopython和object。noPython 完全避免了 Python 解释器,并将完整代码转换为可以在没有 Python 帮助的情况下运行的本机指令。但是,如果由于某种原因,该模式不可用(例如,当使用不受支持的 Python功能或者外部库时),编译将回退到对象模式,当它无法编译某些代码时,它将使用 Python 解释器。当然,nopython 模式是提供最佳性能提升的模式。
Numba 的高层架构
Numba 的转换过程可以在一系列重要步骤中进行转换,从字节码分析到最终机器代码生成。下面的图片说明了这个过程,其中绿色框对应于 Numba 编译器的前端,蓝色框属于后端。

Numba 编译器首先对所需函数的 byecode 进行分析。此步骤生成一个描述可能的执行流程的图表,称为控制流程图(CFG)。基于该图,我们就可以计算分析整个过程。完成这些步骤后,编译器开始将字节码转换为中间表示(IR),Numba 将执行进一步的优化和转换。然后,执行类型推断,这是最重要的步骤之一。在此步骤中,编译器将尝试推断所有变量的类型。此外,如果启用并行设置,IR 代码将转换为等效的并行版本。
如果成功推断出所有类型,则将 Numba IR代码转换为有效的 LLVM IR 代码。但是,如果类型推断过程失败,LLVM 生成的代码将会变慢,因为它仍然需要处理对 Python C API 的调用。最后,LLVM IR 代码由 LLVM JIT 编译器编译为本机指令。然后将这个优化的加工代码加载到内存中,并在对同一函数的多次调用中重用,使其比纯 Python 快数百倍。
出于调试目的,Numba 还提供了一组可以启用的标志,以便查看不同阶段的输出。

os.environ["NUMBA_DUMP_CFG"] = "1"
os.environ["NUMBA_DUMP_IR"] = "1"
os.environ["NUMBA_DUMP_ANNOTATION"] = "1"
os.environ["NUMBA_DEBUG_ARRAY_OPT_STATS"] = "1"
os.environ["NUMBA_DUMP_LLVM"] = "1"
os.environ["NUMBA_DUMP_OPTIMIZED"] = "1"
os.environ["NUMBA_DUMP_ASSEMBLY"] = "1"
加速运算的一个例子
我们可以使用 Numba 库的一个绝佳例子是进行密集的数值运算。举个例子,让我们计算一组 个随机数的 softmax 函数。softmax 函数,用于将一组实际值转换为概率并通常用作神经网络体系结构中的最后一层,定义为:
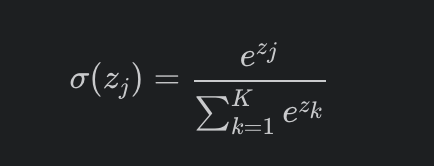
下面的代码显示了这个函数的两个不同的实现,一个纯 Python 方法,一个使用 numba 和 numpy 的优化版本:
import time
import math
import numpy as np
from numba import jit
@jit("f8(f8[:])", cache=False, nopython=True, nogil=True, parallel=True)
def esum(z):
return np.sum(np.exp(z))
@jit("f8[:](f8[:])", cache=False, nopython=True, nogil=True, parallel=True)
def softmax_optimized(z):
num = np.exp(z)
s = num / esum(z)
return s
def softmax_python(z):
s = []
exp_sum = 0
for i in range(len(z)):
exp_sum += math.exp(z[i])
for i in range(len(z)):
s += [math.exp(z[i]) / exp_sum]
return s
def main():
np.random.seed(0)
z = np.random.uniform(0, 10, 10 ** 8) # generate random floats in the range [0,10)
start = time.time()
softmax_python(z.tolist()) # run pure python version of softmax
elapsed = time.time() - start
print('Ran pure python softmax calculations in {} seconds'.format(elapsed))
softmax_optimized(z) # cache jit compilation
start = time.time()
softmax_optimized(z) # run optimzed version of softmax
elapsed = time.time() - start
print('\nRan optimized softmax calculations in {} seconds'.format(elapsed))
if __name__ == '__main__':
main()
上述脚本的输出结果为:
Ran pure python softmax calculations in 77.56219696998596 seconds
Ran optimized softmax calculations in 1.517017126083374 seconds
这些结果清楚的显示了将代码转换为 Numba 能够理解的代码时获得的性能提升。
在 softmax_optimized 函数中,已经存在 Numba 注释,它充分利用了 JIT 优化的全部功能。事实上,在编译过程中,以下字节码将被分析,优化并编译为本机指令:
> python
import dis
from softmax import esum, softmax_optimized
>>> dis.dis(softmax_optimized)
14 0 LOAD_GLOBAL 0 (np)
2 LOAD_ATTR 1 (exp)
4 LOAD_FAST 0 (z)
6 CALL_FUNCTION 1
8 STORE_FAST 1 (num)
15 10 LOAD_FAST 1 (num)
12 LOAD_GLOBAL 2 (esum)
14 LOAD_FAST 0 (z)
16 CALL_FUNCTION 1
18 BINARY_TRUE_DIVIDE
20 STORE_FAST 2 (s)
16 22 LOAD_FAST 2 (s)
24 RETURN_VALUE
>>> dis.dis(esum)
9 0 LOAD_GLOBAL 0 (np)
2 LOAD_ATTR 1 (sum)
4 LOAD_GLOBAL 0 (np)
6 LOAD_ATTR 2 (exp)
8 LOAD_FAST 0 (z)
10 CALL_FUNCTION 1
12 CALL_FUNCTION 1
14 RETURN_VALUE
我们可以通过签名提供有关预期输入和输出类型的更多信息。在上面的示例中,签名"f8[:](f8[:])" 用于指定函数接受双精度浮点数组并返回另一个 64 位浮点数组。
签名也可以使用显式类型名称:“float64 [:](float64 [:])”。一般形式是类型(类型,类型,…),类似于经典函数,其中参数名称由其类型替换,函数名称由其返回类型替换。Numba 接受许多不同的类型,如下所述:
| Type name(s) | Type short name | Description |
|---|---|---|
| boolean | b1 | represented as a byte |
| uint8, byte | u1 | 8-bit unsigned byte |
| uint16 | u2 | 16-bit unsigned integer |
| uint32 | u4 | 32-bit unsigned integer |
| uint64 | u8 | 64-bit unsigned integer |
| int8, char | i1 | 8-bit signed byte |
| int16 | i2 | 16-bit signed integer |
| int32 | i4 | 32-bit signed integer |
| int64 | i8 | 64-bit signed integer |
| intc | – | C |
| uintc | – | C |
| intp | – | pointer-sized integer |
| uintp | – | pointer-sized unsigned integer |
| float32 | f4 | single-precision floating-point number |
| float64, double | f8 | double-precision floating-point number |
| complex64 | c8 | single-precision complex number |
| complex128 | c16 | double-precision complex number |
这些注释很容易使用 [:],[: , :] 或者 [: , : , ;] 分别扩展为数组形式,分别用于 1,2和3维。
最后
Python 是一个非常棒的工具。但是,它也有一些限制,但是我们可以通过一些别的途径来提高它的性能,本文介绍的 Nubma 就是一种非常好的方式。
