人工智能是当前、也将成为未来相当长时间的热门领域。本文概括其在音乐领域的垂直应用。作为交叉学科,该领域需要有一定数理基础,特别是傅里叶变换变体、卷积运算、动态规划算法(特别是Viterbi算法)和各种图结构、简单的物理声学基础、常见随机过程,最好有NLP基础。在智能编配等分支,对基础乐理、和声学、配器法等有高要求。技术细节和代码实现将在后续逐一讨论,在此只描绘大致框架,蜻蜓点水。
音乐人工智能包括若干分支,如听歌识曲、分类推荐、智能作曲、智能配器、智能混音等,本文先介绍应用最成熟的领域———听歌识曲。
-
AI+机器听觉(Content-Based MIR,实现基于内容的音乐检索)
从根据语言数据(直接用文字标定每一首歌的风格,歌手等信息)到直接根据音乐本身进行推断的转变。
1.1 Music Fingerprinting(音乐指纹)

H(X)理解为哈希函数,将音频数组X映射到哈希值Y,Y有更小的数据量,同时体现歌曲间的差异,具有辨别不同歌曲的特性。

上图为著名的飞利浦算法。简述为,对源音频加窗(如汉宁窗),做短时傅里叶变换(STFT)。分窗步比一般语音识别的步长更小,窗间隔只取到窗宽度的1/32。

类似上图,通过ABS(类似复数取模)将二维的幅度相位合并为一维(不用功率谱的原因可能是它丢失了相位,丢失大量信息)。使用带通滤波器不重叠地(non-overlapping)按照对数规则划分若干频段(经典算法中划分33个,300Hz~2000Hz(各种播放设备,无论喇叭,收音机,手机,超市扩音器等等,都能在此频段集中))。类似于图像处理中的池化(Pooling),我们在差分处理需要对这些密集的分频段频域数据在保持相对不变(Invariance)基础上降维。取sub Fingerprint,32比特为一帧(frame)。对于每一帧中的信号能量做bit derivation。大致过程如下。
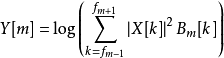
上式中,X[k]是第k频段幅度,Bm[k]为遮罩,由下式确定。此式对应流程图中Energy Computation和bit Derivation的第一步。
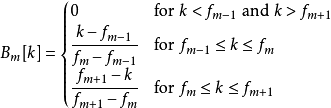
下式引入改进的IDCT,对应bit derivation第二步。
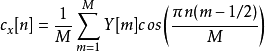
最后获取音频基因并进行比对,归一化获得每个频段的决策。比如,若比对结果大于0则取1涂黑,反之取0留白,如下图。对应流程图bit derivation第三步和第四步。

整个过程可总结为:分窗做短时傅里叶变换;分频并将频谱映射至梅尔刻度;利用三角窗函数取对数;取离散余弦转换(discrete cosine transform)得出梅尔倒频谱(MFCC)。最后,以256帧为一块(block),以块为单位检索音乐。一个块时长约为3.3秒(取窗的宽度为0.37s,那么256×0.37÷32约为2.9,再考虑块两端未重叠的窗宽,最终长度约为3.3秒)。上图指纹即为一块,一行表示一帧各频段,分别取1或0.
通过比对两段音频的指纹,便可知两者的相似程度。以上概述了该算法流程,现在简单描述该算法的可行性。
假设两个音频片段没有任何联系,指纹中任一比特均相互独立,互相匹配的概率为0.5.单个比特匹配随机变量服从p=0.5的伯努利分布。
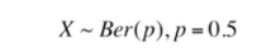
则总匹配数服从含量8192,单次成功概率为0.5的二项分布。n很大,故可近似为正态分布。即可按照下式求出相似比率的μ=0.5,σ≈0.006。这是很窄的正态分布,即当两者无关时,Ratio落在0.5之外的概率微乎其微,落在0.8以上几乎不可能。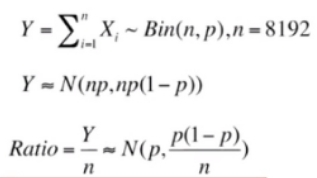
以上看起来很好。然而实际情况中,每个比特互相独立是不可能的。第一步取窗时产生大量重合部分;任何音乐都几乎连续,有律动和音调,因此不可能每个比特互相独立。有的解决方法将非独立因素等效为计算比率时有效点比实际少,即通过适当减小ratio中的分母实现近似,但难以精确描述。若严谨验证需要仿真。下图使用100K随机生成音频律动序列仿真,得出标准差仍在可接受范围。

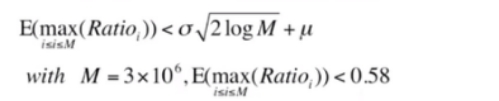
上式对匹配比率的最大值进行估计,得出即使不匹配样本块容量达300万(折合约5000首歌),得出最大匹配率期望仍小于0.58.实验中发现,对于实际匹配样本,即使信噪比(SNR)为-3db,匹配率仍大于0.58.由此可见,该算法非常鲁棒。
以此算法为基础,苹果旗下shazam、谷歌等公司改进诸多方面,基本形成听歌识曲的算法框架。
一般听歌识曲局限在于只能匹配信号精确相同的音频(可以有噪音)。例如,开麦现场无法识别歌曲;播放Live或K歌版本,绝对无法匹配原版。从刚才描述中显然看出,听歌识曲是通过音频的瞬态(几毫秒)特征进行匹配,不同版本的音乐听来是一首,但在波形、频谱上几乎没有关系,因此该算法无效。为此,引入Query by Humming.1.2 Query by Humming (哼唱检索)
这是基于旋律的算法,理解简单但实现相对繁琐:这种匹配是部分的、模糊的,歌者往往部分跑调。
首先进行预处理:onset detection(音符起止点检测,使用python中librosa库可实现大部分)、傅里叶变换提取基波并使用硬拐点分辨音高、计算相对音高(Relative Pitch)和时值比例(IOI Ratio),最后与midi信号匹配,如下图。

匹配的关键算法是动态规划(DP)。

上图展示传统连续系统动态规划(CDP)。横轴为待匹配字符(实际哼唱得到的相对音高和时值比例),纵轴为数据集(每个0代表每首歌对应的字符)。类比正则表达式中的模糊匹配,横轴相当于text,纵轴相当于pattern。现在要填满状态转移矩阵。初始条件是数据库维度第一列的矩阵元素都是0.由于横轴都用负数表示,故在最后一列找出最小值,找到对应行的歌曲即为最佳匹配。上图与下图a同理,通过累加database和query feature的局部相似函数s(t,τ)得到累积相似度S(t,τ),只不过下图横轴累积的是正数。对于上下这两图简单理解为:若某个数据库与第一个音符关系不符合,则略过。若找到符合,进入第二个音符关系寻找匹配。之后的每一次匹配按照下图(c)的规则判断最佳匹配选择应该如何,同时逐渐填满矩阵。

传统CDP算法表达式如下所示。递归终止(矩阵边界)S(t,0)、S(t,-1)、S(-1,τ)、S(0,τ)均为0,递归式中,上图©对应下式(1),描述了获取最佳局部路径的解。每一点旁边的数(1,2,3)表示某状态下把局部相似度计入总相似度时的权重。注意到每沿参考轴(上图向右,上上图向下)前进一次,总相似度都加了3次该前进过程中的局部相似函数值.所以累积函数除3即可归一化。
然后,寻找相似片段。上图(b)展示了累积相似度函数图像。CDP将相似片段的端点计为累计相似度大于门限α的交点。于是便找到可能的一首或几首歌曲。

以上传统CDP算法可以针对音乐特征进行优化。例如,根据音高直方图(表达relative pitch出现频次)过滤;根据旋律走向和时值比例过滤完全不可能匹配的歌曲;事先分析数据库中数据主题并评估检测权重(类似调参)。
传统听歌识曲基本原理大致如此,接下来将介绍关于智能分类(推荐)和智能作曲的基本原理,未完待续。
(部分图片引自CMU Dr. Gus Xia课件)
.
