1.导入需要的库
import time
from selenium import webdriver
2.浏览器获取驱动
需要下载跟chrome浏览器相匹配的驱动driverchrome.exe,详情见:根据电脑浏览器的版本下载相应的驱动chromedriver.exe,环境变量的配置,详情见这里Window 下配置ChromeDriver(简单4步完成)
再将driverchrome.exe复制到Anaconda3所在的文件Script文件夹中,我的是:

获取驱动
# 获取驱动
driver = webdriver.Chrome()
将窗口最大化
# 将窗口最大化
driver.maximize_window
3.网页操作
获取网页网址,开始对网页进行操作

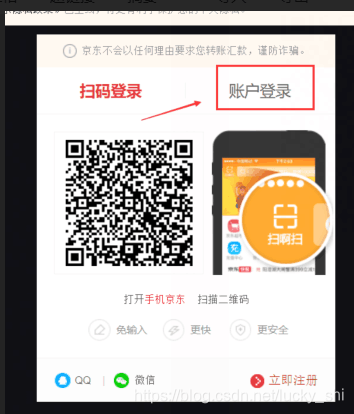
图中箭头两处点击操作均使用
driver.find_element_by_link_text('xxxxxx').click()
完整代码为:
# 导入库
import time
from selenium import webdriver
# 浏览器获得驱动
driver = webdriver.Chrome()
def loadpage(userid, password):
# 窗口最大化
driver.maximize_window()
url = "https://cart.jd.com"
driver.get(url)
time.sleep(1)
# 进入登录页面
driver.find_element_by_link_text('你好,请登录').click()
# 选择账户登录方式
driver.find_element_by_link_text('账户登录').click()
# 输入框输入账号和密码
driver.find_element_by_id('loginname').send_keys(userid)
driver.find_element_by_id('nloginpwd').send_keys(password)
# driver.find_element_by_xpath('//*[@id="loginname"]').send_keys('xxxxxxxx')
# driver.find_element_by_xpath('//*[@id="nloginpwd"]').send_keys('xxxxxxxx')
driver.find_element_by_id('loginsubmit').click()
if __name__ == '__main__':
id = "xxxxxxxx" # 用户账号
passwd = "xxxxxxxx" # 用户密码
loadpage(id, passwd)
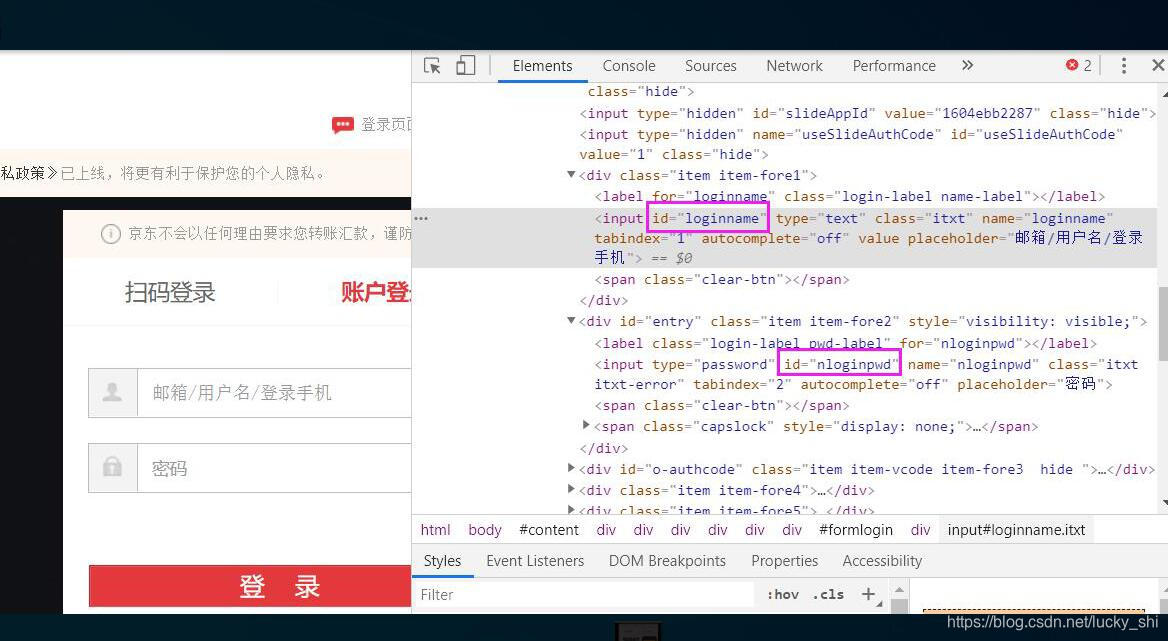
另:上述是使用driver.find_element_by_id() 定位标签的,也可替换为driver.find_element_by_xpath() 可以右击 copy XPath来定位标签
# 输入框输入账号和密码
driver.find_element_by_xpath('//*[@id="loginname"]').send_keys('xxxxxxx')
driver.find_element_by_xpath('//*[@id="nloginpwd"]').send_keys('xxxxxxx')
总结:
①导入需要的库
②导入驱动
①对网页操作
