紧接着上一篇我们继续分析在并发编程中所用到的一些并发工具。
5.Fork/Join 框架
5.1 什么是 Fork/Join 框架
Fork/Join 框架是 Java7 提供的一个用于并行执行任务的框架,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
Fork :就是把一个大任务切分成若干子任务并行的执行;Join:就是合并这些子任务的执行结果。
设计思路图:
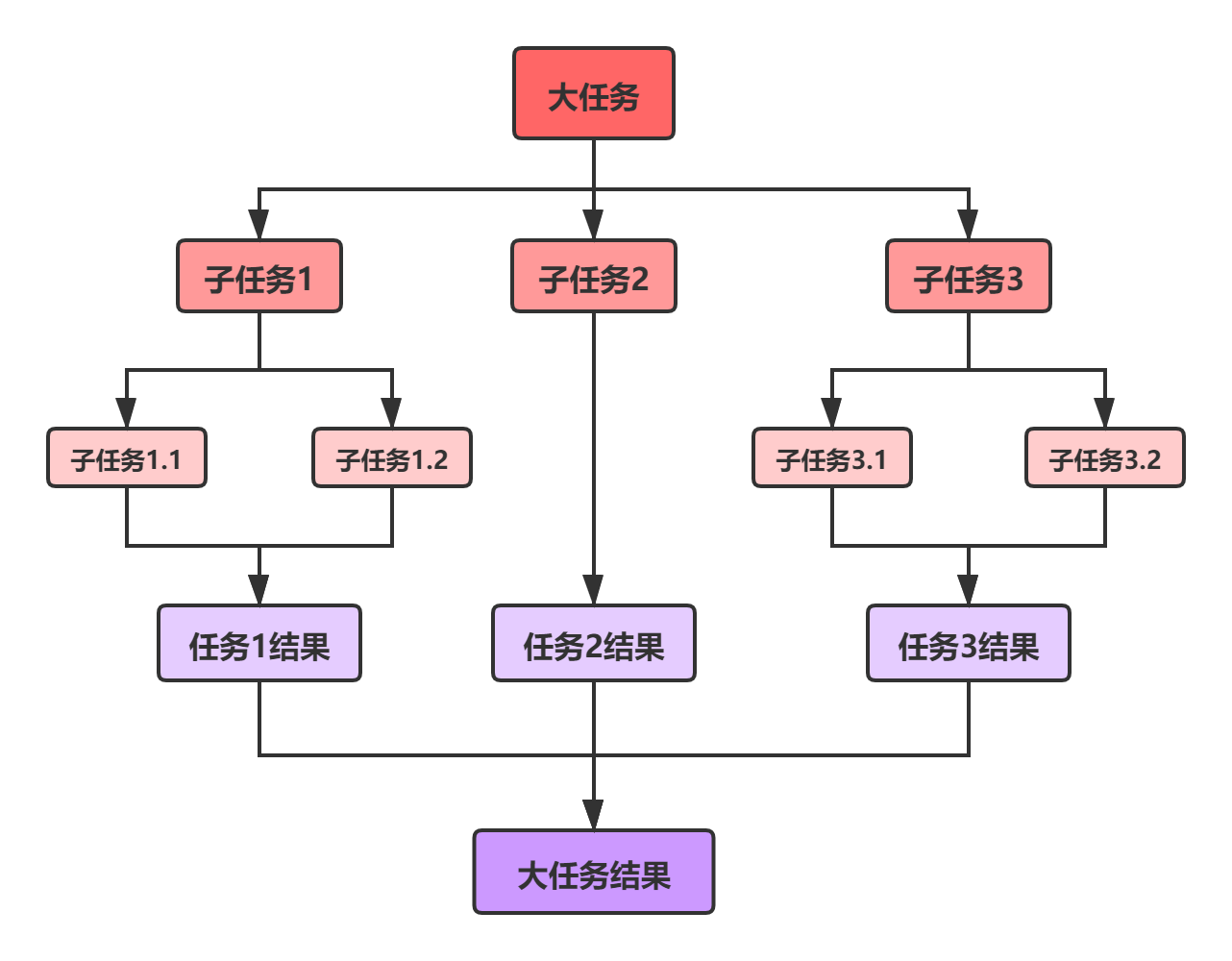
5.2 工作窃取算法
工作窃取(work-stealing)算法:某个线程从其他队列中窃取任务来执行。
在 Fork/Join 框架中为了减少线程间的竞争,把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应。但是,有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时他们会访问同一个队列,所以减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
双线程工作窃取的工作流程:
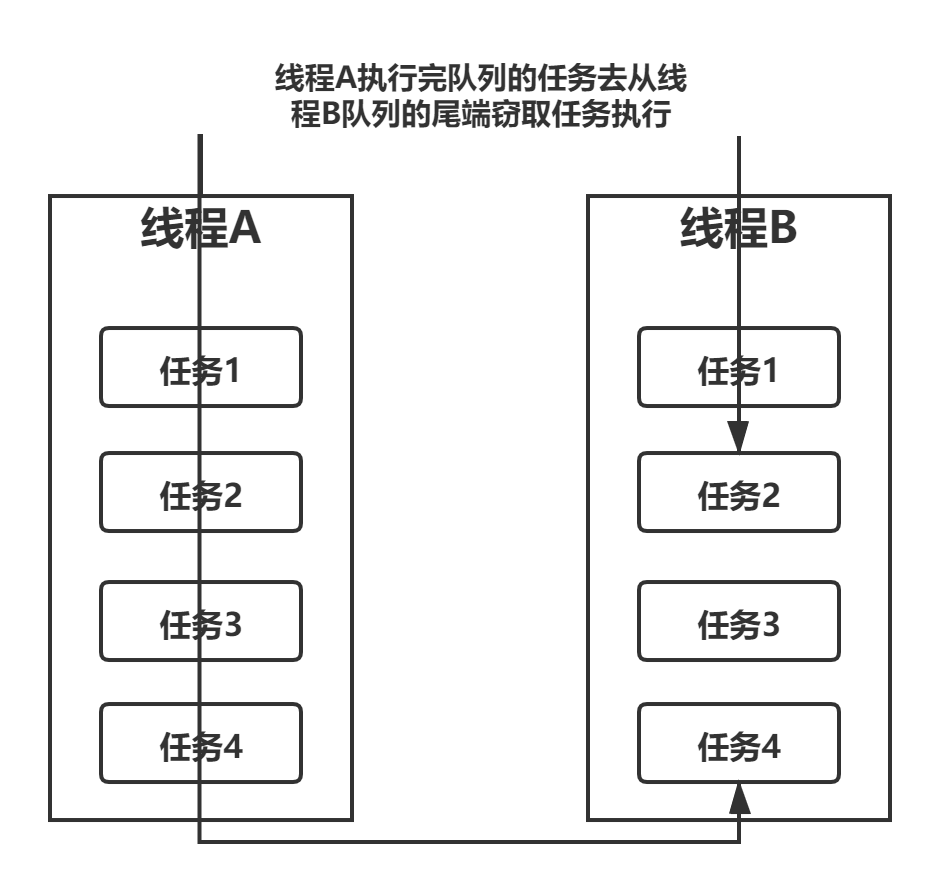
工作窃取算法的优点:充分利用线程进行并行计算,减少了线程间的竞争。
工作窃取算法的缺点:在某些情况下还是存在竞争,比如双端队列只有一个任务时;算法会消耗更多的系统资源,可能会创建多个线程和双端队列。
5.3 使用 Fork/Join 框架
使用 Fork/Join 框架来完成任务大概分为两个步骤:
- 分割任务;
- 执行任务并合并结果。
Fork/Join 框架使用两个类完成以上的两件事情。
-
ForkJoinTask:我们要使用 Fork/Join 框架,必须首先创建一个 ForkJoin任务。它提供在任务中执行 fork() 和 join() 操作机制。通常情况下我们不需要直接继承 ForkJoinTask 类,只需要继承它的子类,Fork/Join 框架提供了两个子类。
RecursiveAction:用于没有返回结果的任务。
RecursiveTask:用于有返回结果的任务。 -
ForkJoinPool:ForkJoinTask 需要通过 ForkJoinPool 来执行。
任务分割出的子任务会添加到当前工作线程多维护的双端队列中,进入队列的头部。当一个工作线程的队列里暂时没有任务时,它会随机从其他工作线程的队列的尾部获取一个任务。
光说不练,下面我们设计一个利用 Fork/Join 框架实现的排序算法:
public class SortTask extends RecursiveTask<int[]> {
private static final int THRESHOLD = 10;
private int start;
private int end;
private int[] arrays;
public SortTask(int start, int end, int[] arrays) {
this.start = start;
this.end = end;
this.arrays = arrays;
}
@Override
protected int[] compute() {
boolean canCompute = (end - start + 1) <= THRESHOLD;
if (canCompute) {
Arrays.sort(arrays, start, end);
} else {
// 如果任务大于阈值,就分裂成两个子任务计算
int mid = (start + end) / 2;
SortTask leftTask = new SortTask(start, mid, arrays);
SortTask rightTask = new SortTask(mid+1, end, arrays);
// 执行子任务
leftTask.fork();
rightTask.fork();
// 等待子任务执行完成,得到结果
int[] leftArrays = leftTask.join();
int[] rightArrays = rightTask.join();
// 合并子任务
Arrays.sort(leftArrays, start, end);
}
return arrays;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
SortTask sortTask = new SortTask(0, 20, new int[]{20, 1, 3, 5, 4, 3, 6, 7, 1, 11, 19, 18, 13, 14, 15, 21, 3, 44, 3, 7});
ForkJoinTask<int[]> result = forkJoinPool.submit(sortTask);
try {
int[] ints = result.get();
for (int i = 0; i < ints.length; i++) {
System.out.print(ints[i] + " ");
}
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
5.4 Fork/Join 框架的实现原理
Fork/Join 框架中双端队列的相关操作与 ConcurrentHashMap 的 table 数组较为相似,都是采用 CAS 的方式来处理每个桶的并发,这里推荐两篇博客可以结合着理解 Fork/Join 框架的实现原理:
Fork/Join框架(1) 原理
Fork/Join框架(2)实现
这两篇分别从原理和源码实现来分析了Fork/Join 框架。
三、并发工具类
在JDK并发包里提供了几个非常有用的并发工具类。CountDownLatch、CyclicBarrier、Semaphore和Phaser 工具类提供了一种并发流程控制的手段,Exchanger 工具类则提供了在线程间交换数据的一种手段。
1.等待多线程完成的 CountDownLatch
CountDownLatch 允许一个或多个线程等待其他线程完成操作。
1.1 CountDownLatch 简介
CountDownLatch是一个辅助同步器类,用来作计数使用,它的作用类似于倒数计数器,先设定一个计数初始值,当计数降到0时,将会触发一些操作。
初始计数值在构造CountDownLatch对象时传入,每调用一次 countDown() 方法,计数值就会减1。
线程可以调用CountDownLatch的await方法进入阻塞,当计数值降到0时,所有之前调用await阻塞的线程都会释放。
注意:计数器必须大于等于0,计数器等于0时,调用await方法时不会阻塞当前线程。CountDownLatch 不可能重新初始化或者修改 CountDownLatch 对象的内部计数器的值。
1.2 CountDownLatch 应用场景
作为一个开关/入口
需求一:假设上学某天老师迟到(老师拿的钥匙),那么来的学生就只能在教室门外等老师,老师来了学生才能进入教室,这里老师就相当于一个教室的入口。
public class Holder {
private static final CountDownLatch startLatch = new CountDownLatch(1);
private static final int N = 5;
public static void main(String[] args) {
for (int i = 0; i < N; i++) {
new Student(startLatch).start();
}
// 主线程调用countDown方法,相当于老师来了
startLatch.countDown();
System.out.println("teach coming,open the door");
}
}
class Student extends Thread {
private final CountDownLatch waitLatch;
public Student(CountDownLatch waitLatch) {
this.waitLatch = waitLatch;
}
@Override
public void run() {
try {
// 如果count不为0,说明老师没来
if (waitLatch.getCount() != 0) {
System.out.println("student need wait");
waitLatch.await();
} else {
System.out.println("the teacher coming, student can enter");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
程序运行可能会出现打印语句顺序的问题,这是因为没有同步出现的原因,因为这不是重点,就没有给代码加锁。
作为一个事件的完成信号
需求二:使某个线程在其它N个线程完成某项操作之前一直等待。
public class Holder {
private static final int N = 5;
private static final CountDownLatch Latch = new CountDownLatch(N);
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < N; i++) {
new Worker(Latch).start();
}
Latch.await();
System.out.println("work finish");
}
}
class Worker extends Thread {
private final CountDownLatch latch;
public Worker(CountDownLatch latch) {
this.latch = latch;
}
@Override
public void run() {
doWork();
latch.countDown();
}
void doWork(){
System.out.println("doWork..");
}
}
1.3 CountDownLatch 原理
CountDownLatch 利用 AQS 来实现对线程的控制,状态变量 state 和 CountDownLatch 计数器的值一致。
每次调用countDown方法 state-1:
for (;;) {
int c = getState();
if (c == 0)
return false;
int nextc = c-1; // state-1
if (compareAndSetState(c, nextc))
return nextc == 0;
}
每次调用await方法会判断 state 是否为0,为0 则不需要等待,不为0 就将该线程加入到 AQS 的同步队列:
/**
1. 判断state是否为0
2. 0:tryAcquireShared(arg) 返回1,不需要等待退出该方法
3. 不为0:tryAcquireShared(arg) 返回-1,进入doAcquireSharedInterruptibly(arg)
*/
if (tryAcquireShared(arg) < 0)
// 该方法会将线程结点添加到同步队列中,直到state=0,释放同步队列线程取消等待
doAcquireSharedInterruptibly(arg);
CountDownLatch 原理非常简单,这里就不在赘述,如果需要了解 AQS 的原理实现可以参考:
JUC AQS源码分析(上) – AQS原理分析
以及后面两篇对ReentrantLock的源码分析,看懂之后再回过头看 CountDownLatch 的源码就感觉非常简单了。
2.循环屏障 CyclicBarrier
CyclicBarrier 的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它的作用是让一组线程到达一个屏障时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才能继续运行。
2.1 CyclicBarrier 简介
一共4个线程A、B、C、D,它们到达栅栏的顺序可能各不相同。当A、B、C到达栅栏后,由于没有满足总数【4】的要求,所以会一直等待,当线程D到达后,栅栏才会放行。
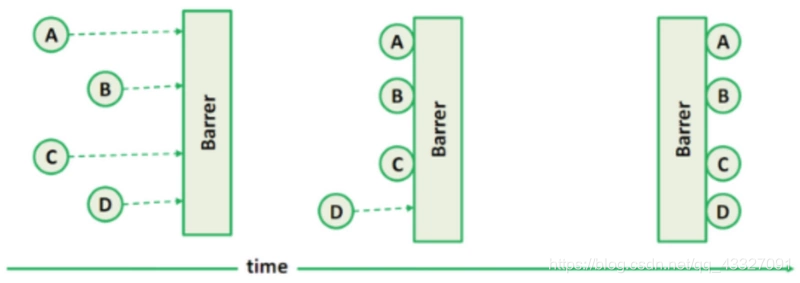
CyclicBarrier 有两个构造方法:
public CyclicBarrier(int parties)
其参数表示屏障拦截的线程数量,每个线程调用 await 方法告诉 CyclicBarrier 已经到达屏障,然后当前线程被阻塞。public CyclicBarrier(int parties, Runnable barrierAction)
这是一种更高级的构造方法,用于在线程到达屏障时,优先执行barrierAction,方便处理更复杂的业务场景。
2.2 CyclicBarrier 应用场景
CyclicBarrier 可以用于多线程计算数据,最后合并计算结果的场景。
public class Holder implements Runnable{
// 创建线程数量为4个限制的屏障,处理完后执行当前类的run方法
private final CyclicBarrier barrier = new CyclicBarrier(4, this);
// 假设只有4个算式,所以启动4个线程
private final Executor executor = Executors.newFixedThreadPool(4);
// 保存算式的计算结果
private final ArrayList<Integer> list = new ArrayList<>();
private void count() {
for (int i = 0; i < 4; i++) {
executor.execute(new Runnable(){
@Override
public void run() {
// 假设 1 为算式的计算结果
list.add(1);
// 计算完成,出入一个屏障
try {
barrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}
});
}
}
@Override
public void run() {
int sum = 0;
// 汇总结果
for (Integer num :
list) {
sum += num;
}
System.out.println(sum);
}
public static void main(String[] args) {
Holder holder = new Holder();
holder.count();
}
}
2.3 CyclicBarrier 原理
CyclicBarrier 并没有自己去实现AQS框架,而是利用了ReentrantLock和Condition,这也就简化了代码复杂度,CyclicBarrier 源码也是非常简单。
重要成员变量:
/** The lock for guarding barrier entry */
private final ReentrantLock lock = new ReentrantLock();
/** Condition to wait on until tripped */
private final Condition trip = lock.newCondition();
/** The number of parties 创建屏障时限制线程数量 */
private final int parties;
// 记录还有多少个线程未到达屏障,count=0表示都到达了屏障
private int count;
/** The current generation 当前这轮的CyclicBarrier的运行状况 */
private Generation generation = new Generation();
调用await方法时会使用trip.wait方法使当前线程加入等待队列:
for (;;) {
try {
if (!timed)
trip.await();
else if (nanos > 0L)
nanos = trip.awaitNanos(nanos);
}
}
如果到达屏障的线程数量等于了parties,即count=0,执行指定的方法(null就不执行),然后调用nextGeneration();开始新的一轮,没有任务就结束:
int index = --count;
if (index == 0) { // tripped
boolean ranAction = false;
try {
final Runnable command = barrierCommand;
if (command != null)
command.run();
ranAction = true;
// 该方法重置parties,定义新一轮的Generation
nextGeneration();
return 0;
} finally {
if (!ranAction)
breakBarrier();
}
}
在nextGeneration唤醒等待队列上的所有线程:
private void nextGeneration() {
// signal completion of last generation
trip.signalAll();
// set up next generation
count = parties;
generation = new Generation();
}
2.4 CyclicBarrier 异常处理
CyclicBarrier放行的条件是等待的线程数达到指定数目,如果线程被中断导致最终的等待线程数达不到栅栏的要求怎么办?
CyclicBarrier 基本在线程操作的方法中都有对异常的判断和处理,在await方法上抛出了两种异常:
public int await() throws InterruptedException, BrokenBarrierException
InterruptedException:对线程中断的异常
BrokenBarrierException:屏障被破坏可能等不到所有线程到达,等待线程没有必要继续等待。这个异常是因为出现别的异常(InterruptedException)或错误,从而调用breakBarrier方法将generation.broken置为true:
private void breakBarrier() {
generation.broken = true;
count = parties;
// 唤醒等待队列所有线程
trip.signalAll();
}
3.控制并发线程数的 Semaphore
Semaphore(信号量)是用来控制同时访问特定资源的线程数量,它通过协调各个线程,以保证合理的使用公共资源。
Semaphore 类似于电影院的门票一样,数量有限。
3.1 Semaphore 简介
这个类的作用有点类似于“许可证”。有时,我们因为一些原因需要控制同时访问共享资源的最大线程数量,比如出于系统性能的考虑需要限流,或者共享资源是稀缺资源,我们需要有一种办法能够协调各个线程,以保证合理的使用公共资源。
Semaphore维护了一个许可集,其实就是一定数量的“许可证”。
当有线程想要访问共享资源时,需要先获取(acquire)的许可;如果许可不够了,线程需要一直等待,直到许可可用。当线程使用完共享资源后,可以归还(release)许可,以供其它需要的线程使用。
3.2 Semaphore 应用场景
Semaphore 可以用于做流量控制,特别是公用资源有限的应用场景,比如数据库连接。
假设有一个需求:要读取几万个文件的数据,因为都是IO密集的任务。我们可以启动几十个线程并发地读取,但是如果读到内存后,还需要存储到数据库中,而数据库的连接数只有10个,这是我们必须控制只有10个线程同时获取数据库连接。这个时候,就可以利用Semaphore 来对线程进行控制。
public class Holder {
private static final int THREAD_COUNT = 30;
private static ExecutorService threadPool = Executors.newFixedThreadPool(THREAD_COUNT);
private static Semaphore s = new Semaphore(10);
public static void main(String[] args) {
for (int i = 0; i < THREAD_COUNT; i++) {
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
// 获取许可
s.acquire();
System.out.println("sava data");
Thread.sleep(3000);
// 释放许可
s.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
threadPool.shutdown();
}
}
其他方法:
int availablePermits():返回此信号量中当前可用的许可证数。
int getQueueLength():返回正在等待获取许可证的线程数。
boolean hasQueueThreads():是否有线程正在等待获取许可证。
void reducePermits(int reduction):减少reduction个许可证,是个 protected 方法。
Collection getQueueThread():返回所有等待获取许可证的线程集合,个 protected 方法。
3.3 Semaphore 原理
Semaphore 和 CountDownLatch 非常相似在内部类实现了AQS的共享方法,在 Semaphore 中状态变量 state 用来记录许可证的剩余数量。剩余许可数 < 0表示资源不可用,所有线程需要等待; 许可剩余数 ≥ 0表示资源可用,所有线程可以同时访问。
Semaphore 的公平策略也与 ReentrantLock 相似,公平锁会先判断同步队列中是否存在线程结点,而非公平锁会直接CAS。
调用acquire方法获取许可证,一个线程也可以调用acquire(int permits)获取多个许可证。
public void acquire() throws InterruptedException {
sync.acquireSharedInterruptibly(1);
}
public void acquire(int permits) throws InterruptedException {
// 只是多了对permits数量的判断
if (permits < 0) throw new IllegalArgumentException();
sync.acquireSharedInterruptibly(permits);
}
调用AQS的acquireSharedInterruptibly方法,共享式获取:
// arg表示获取的许可证数量
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
// 返回负数表示获取失败
if (tryAcquireShared(arg) < 0)
// 进入同步队列阻塞,与CountDownLatch一样
doAcquireSharedInterruptibly(arg);
}
在内部类 FairSync 中实现tryAcquireShared(int acquires)共享式获取acquires个许可证:
protected int tryAcquireShared(int acquires) {
for (;;) {
// 判断当前线程是否需要排队,需要就会返回-1
if (hasQueuedPredecessors())
return -1;
// 剩余许可证
int available = getState();
// 剩余许可证-所需许可证
int remaining = available - acquires;
// remaining 小于0表示获取失败
if (remaining < 0 ||
compareAndSetState(available, remaining))
return remaining;
}
}
非公平类 NonfairSync 的tryAcquireShared(int acquires)方法:
// 不需要判断是否需要排队直接CAS
protected int tryAcquireShared(int acquires) {
return nonfairTryAcquireShared(acquires);
}
final int nonfairTryAcquireShared(int acquires) {
for (;;) {
int available = getState();
int remaining = available - acquires;
if (remaining < 0 ||
compareAndSetState(available, remaining))
return remaining;
}
}
调用release方法释放许可证,或者调用release(int permits)释放多个许可证:
public void release() {
sync.releaseShared(1);
}
public void release(int permits) {
if (permits < 0) throw new IllegalArgumentException();
sync.releaseShared(permits);
}
调用AQS的releaseShared,共享式释放:
public final boolean releaseShared(int arg) {
// 当前线程释放arg个许可证,如果成功
if (tryReleaseShared(arg)) {
// 唤醒等待队列的线程
doReleaseShared();
return true;
}
return false;
}
内部类 Sync 中实现的释放许可证tryReleaseShared(int releases)方法:
protected final boolean tryReleaseShared(int releases) {
for (;;) {
int current = getState();
// 将释放的许可证个数加到 state 上
int next = current + releases;
if (next < current) // overflow
throw new Error("Maximum permit count exceeded");
if (compareAndSetState(current, next))
return true;
}
}
Semaphore 其他源码逻辑基本类似都非常简单易懂,这里就不在赘述。
4.线程间交换数据的 Exchanger
Exchanger(交换者)是一个用于线程间协作的工具类。Exchanger 用于进行线程间的数据交换。它提供了一个同步点,在这个同步点,两个线程可以交换彼此的数据。
4.1 Exchanger 简介
两个线程通过 Exchanger 的 exchange 方法交换数据,如果第一个线程先执行 exchange() 方法,它会一直等待第二个线程也执行 exchange 方法,当两个线程都到达同步点,这两个线程就可以交换数据,将本线程生产出来的数据传递给对方。
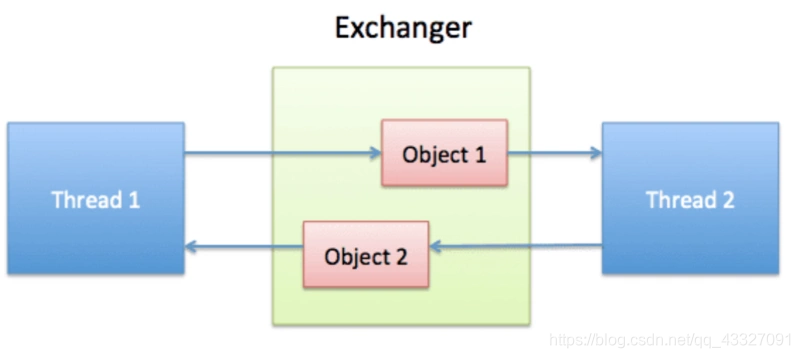
4.2 Exchanger 应用场景
Exchanger 可以用于遗传算法,遗传算法里需要选出两个人作为交配对象,这时候会交换两个人的数据,并使用交叉规则得出2个交配结果。
Exchanger 也可以用于校对工作,比如需要将纸质银行流水通过人工的方式录入成电子银行流水,为了避免错误,采用 A、B 两人进行录入,录入之后系统进行校对,看是否一致。
public class Holder {
private static final Exchanger<String> exge = new Exchanger<>();
private static ExecutorService threadPool = Executors.newFixedThreadPool(2);
public static void main(String[] args) {
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
// A 录入银行流水数据
String A = "银行流水A";
exge.exchange(A);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
// B 录入银行流水数据
String B = "银行流水B";
String r = exge.exchange(B);
System.out.println("A、B是否一致:" + r.equals(B));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
threadPool.shutdown();
}
}
4.3 Exchanger 原理
在 Exchanger 有内部类 Participant (继承ThreadLocal)存储着线程本地变量Node。
/** The corresponding thread local class */
static final class Participant extends ThreadLocal<Node> {
public Node initialValue() { return new Node(); }
}
内部类 Node 保存这每个线程自身携带的交换对象:
@sun.misc.Contended static final class Node {
/**
* 以下变量,多槽交换时使用
*/
int index; // Arena多槽数组的索引
int bound; // 上次记录的Exchanger.bound值
int collides; // 当前bound下CAS失败次数
/**
* 以下变量,单槽交换时使用
*/
int hash; // 线程伪随机数 - 自旋优化
Object item; // 当前线程携带的数据
volatile Object match; // 配对线程携带的数据(后到达的线程会将携带的值设置到配对线程的该字段上)
volatile Thread parked; // 此结点上的阻塞线程(先到达并阻塞的线程会设置为自身)
}
Exchanger 存在两种数据交换的方式,首先后直接调用单槽交换方法,在单槽交换中出现了线程竞争会初始化多槽数组 arena 返回null,然后调用多槽交换方法。
/**
/**
* Elimination array; null until enabled (within slotExchange).
* Element accesses use emulation of volatile gets and CAS.
* 多槽交换的数组
*/
private volatile Node[] arena;
/**
* Slot used until contention detected.
* 单槽交换结点
*/
private volatile Node slot;
线程调用exchange(V x)方法将携带数据传入方法中,并运行不同的交换方式:
public V exchange(V x) throws InterruptedException {
Object v;
// 获取当前线程的携带数据,为空置为NULL_ITEM(new Object())
Object item = (x == null) ? NULL_ITEM : x; // translate null args
/**
* 1.判断多槽交换数组是否为空
* 是:3.线程是否被中断
* 是:抛出异常
* 否:多槽交换 arenaExchange
* 否:2.单槽交换 slotExchange
*/
if ((arena != null ||
(v = slotExchange(item, false, 0L)) == null) &&
((Thread.interrupted() || // disambiguates null return
(v = arenaExchange(item, false, 0L)) == null)))
throw new InterruptedException();
// 返回当前线程的交换数据,空则为null
return (v == NULL_ITEM) ? null : (V)v;
}
Exchanger 单槽交换
单槽位交换示意图:
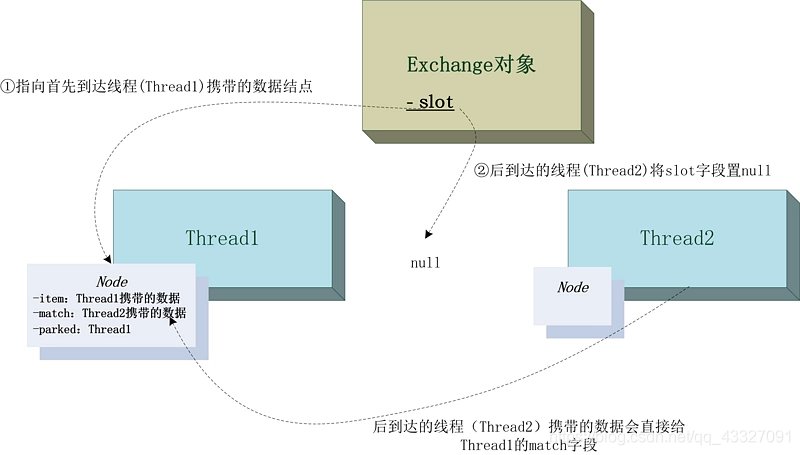
单槽交换调用slotExchange(Object item, boolean timed, long ns):
private final Object slotExchange(Object item, boolean timed, long ns) {
// 获取当前线程的数据结点p
Node p = participant.get();
Thread t = Thread.currentThread();
if (t.isInterrupted()) // preserve interrupt status so caller can recheck
return null;
for (Node q;;) {
// slot不为空,表示已经有线程先到达b并占有slot
if ((q = slot) != null) {
// 后来的匹配线程进入到该判断,会将slot置为null
if (U.compareAndSwapObject(this, SLOT, q, null)) {
// 获取先到线程的携带数据,作为后到的匹配线程的交换数据
Object v = q.item;
// 后到的匹配线程的携带数据存储到先到线程的match字段,作为先到线程的交换数据
q.match = item;
// 获取先到线程
Thread w = q.parked;
if (w != null)
// 唤醒先到线程
U.unpark(w);
// 当前后到匹配线程返回交换数据
return v;
}
// 出现线程竞争,创建多槽交换数组
if (NCPU > 1 && bound == 0 &&
/**
* SEQ = MMASK + 1:bound高8位为1,低8位为0
*
*/
U.compareAndSwapInt(this, BOUND, 0, SEQ))
arena = new Node[(FULL + 2) << ASHIFT];
}
// 多槽数组被初始化,返回null,调用多槽交换方法
else if (arena != null)
return null; // caller must reroute to arenaExchange
// slot还未被占用,CAS占用slot结点
else {
// 记录先到线程的携带数据
p.item = item;
// 先到线程占用slot结点
if (U.compareAndSwapObject(this, SLOT, null, p))
break;
// 占用失败,重新循环
p.item = null;
}
}
// 执行到此,当前线程先到达并且占有了slot结点,等待后到的匹配线程
int h = p.hash;
long end = timed ? System.nanoTime() + ns : 0L;
// 自旋等待匹配线程次数
int spins = (NCPU > 1) ? SPINS : 1;
Object v;
// 如果先到线程的match字段没有后到匹配线程的携带数据就一直循环
while ((v = p.match) == null) {
// 自旋过程中,随机释放当前线程占有的CPU资源
if (spins > 0) {
h ^= h << 1; h ^= h >>> 3; h ^= h << 10;
if (h == 0)
h = SPINS | (int)t.getId();
else if (h < 0 && (--spins & ((SPINS >>> 1) - 1)) == 0)
Thread.yield();
}
// 匹配线程已经到达,可能还未准备完成(还未设置match字段),所以再自旋一会
else if (slot != p)
spins = SPINS;
// 默认传入time=false 即end=0L
// 未指定超时或者超时时间未到期,会将当前线程阻塞,等待匹配线程唤醒
else if (!t.isInterrupted() && arena == null &&
(!timed || (ns = end - System.nanoTime()) > 0L)) {
// 当前线程状态置为阻塞
U.putObject(t, BLOCKER, this);
// 记录park线程为先到线程即当前线程 t
p.parked = t;
// 如果slot==p,匹配线程未到就会park当前线程
if (slot == p)
U.park(false, ns);
// 这里匹配线程到了,先到线程被唤醒,也可能是上面判断不成立
// 阻塞线程置为null
p.parked = null;
// 阻塞状态取消
U.putObject(t, BLOCKER, null);
}
// 超时或被取消,取消先到线程对slot的占有
else if (U.compareAndSwapObject(this, SLOT, p, null)) {
v = timed && ns <= 0L && !t.isInterrupted() ? TIMED_OUT : null;
break;
}
}
// match字段置为null
U.putOrderedObject(p, MATCH, null);
p.item = null;
p.hash = h;
// 返回之前记录的交换数据
return v;
}
单槽交换流程图:
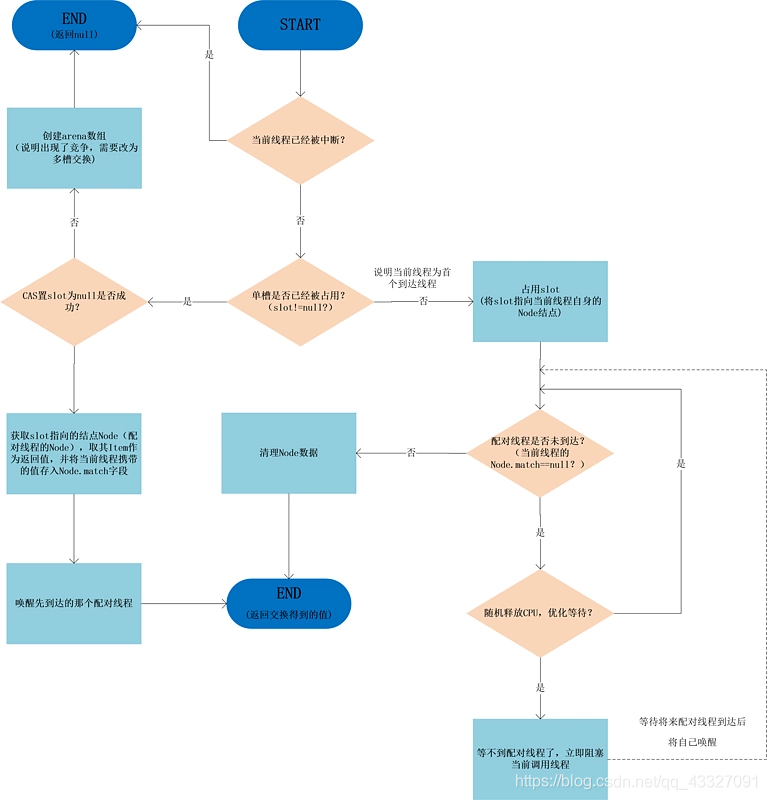
Exchanger 多槽交换
当单槽交换方法中出现线程竞争时,就会初始化 arena 数组,返回方法并调用多槽交换arenaExchange(Object item, boolean timed, long ns)方法:
private final Object arenaExchange(Object item, boolean timed, long ns) {
Node[] a = arena;
Node p = participant.get();
for (int i = p.index;;) { // access slot at i
int b, m, c; long j; // j is raw array offset
// 从arena数组选出偏移量为j的元素,作为slot(和单槽交换类似)
Node q = (Node)U.getObjectVolatile(a, j = (i << ASHIFT) + ABASE);
// 先到线程已经占有,后来的匹配线程进入判断
if (q != null && U.compareAndSwapObject(a, j, q, null)) {
// 下面操作与单槽交换相同
Object v = q.item; // release
q.match = item;
Thread w = q.parked;
if (w != null)
U.unpark(w);
return v;
}
/**
* 如果槽位为空,且i并没有越界
* bound:高8位存储版本号;低8位存储数组大小
* (b = bound) & MMASK:获取数组大小赋值给m
* m:表示线程可以访问数组的最大小标
*/
else if (i <= (m = (b = bound) & MMASK) && q == null) {
p.item = item; // offer
// 先到线程占有slot成功
if (U.compareAndSwapObject(a, j, null, p)) {
long end = (timed && m == 0) ? System.nanoTime() + ns : 0L;
Thread t = Thread.currentThread(); // wait
// 开始自旋等待匹配线程
for (int h = p.hash, spins = SPINS;;) {
Object v = p.match;
// 匹配线程将先到线程的match字段设置完成
// 清理结点信息,返回交换数据
if (v != null) {
U.putOrderedObject(p, MATCH, null);
p.item = null; // clear for next use
p.hash = h;
return v;
}
// 自旋,让出CPU
else if (spins > 0) {
h ^= h << 1; h ^= h >>> 3; h ^= h << 10; // xorshift
if (h == 0) // initialize hash
h = SPINS | (int)t.getId();
else if (h < 0 && // approx 50% true
(--spins & ((SPINS >>> 1) - 1)) == 0)
Thread.yield(); // two yields per wait
}
// 匹配线程来了,但未准备完成,需要再自旋一会
else if (U.getObjectVolatile(a, j) != p)
spins = SPINS; // releaser hasn't set match yet
// 未指定超时或者超时时间未到期,会将当前线程阻塞,等待匹配线程唤醒
else if (!t.isInterrupted() && m == 0 &&
(!timed ||
(ns = end - System.nanoTime()) > 0L)) {
U.putObject(t, BLOCKER, this); // emulate LockSupport
p.parked = t; // minimize window
if (U.getObjectVolatile(a, j) == p)
U.park(false, ns);
p.parked = null;
U.putObject(t, BLOCKER, null);
}
// 执行到这里,已经超时,清理arena数组当前的slot结点
else if (U.getObjectVolatile(a, j) == p &&
U.compareAndSwapObject(a, j, p, null)) {
// m:表示线程可以访问arena数组的最大下标
// arena数组不为空
if (m != 0) // try to shrink
// 低8位:m下标减少一位
// 高8位:版本号+1
U.compareAndSwapInt(this, BOUND, b, b + SEQ - 1);
p.item = null;
p.hash = h;
// 索引减半
i = p.index >>>= 1; // descend
if (Thread.interrupted())
return null;
if (timed && m == 0 && ns <= 0L)
return TIMED_OUT;
break; // expired; restart
}
}
}
// slot更新失败,清除结点信息
else
p.item = null; // clear offer
}
// i超出范围,需要重新设置i的值
else {
// bound被改变,更新最新的bound,collides重置
if (p.bound != b) { // stale; reset
p.bound = b;
p.collides = 0;
// i向左查找,当前线程换一个slot,避免竞争
i = (i != m || m == 0) ? m : m - 1;
}
/**
* 1.(c = p.collides) < m:说明还有槽位未访问(遍历m以前的所有槽位)
* 向左访问slot槽位,直到访问完毕
* 2.扩容m:已经遍历完了槽位且m达到最大数组下标
*/
else if ((c = p.collides) < m || m == FULL ||
!U.compareAndSwapInt(this, BOUND, b, b + SEQ + 1)) {
p.collides = c + 1;
i = (i == 0) ? m : i - 1; // cyclically traverse
}
// 如果扩容成功,index直接拿到新的槽位
else
i = m + 1; // grow
p.index = i;
}
}
}
提出一个问题:
1.先看为什么ASHIFT设置成7?
这是为了尽量避免slot数组中不同的元素在同一个缓存行上,<< ASHIFT 左移7位,
表示至少移动了128地址位,而我们主流的缓存行大小一般为32字节到256字节,
所以128个地址位基本覆盖到了常见的处理器平台。arena数组中元素的分布如图,
它们之间间隔128个整数倍地址位,也就是说最小相差128个地址位。
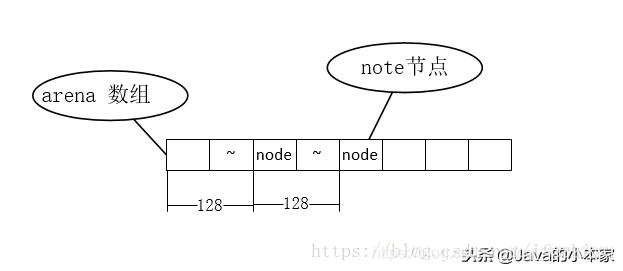
在多槽交换中定位槽位时,考虑到了缓存行的影响。由于高速缓存与内存之间是以缓存行为单位交换数据的,根据局部性原理,相邻地址空间的数据会被加载到高速缓存的同一个数据块上(缓存行),而数组是连续的(逻辑,涉及到虚拟内存)内存地址空间,因此,多个slot会被加载到同一个缓存行上,当一个slot改变时,会导致这个slot所在的缓存行上所有的数据(包括其他的slot)无效,需要从内存重新加载,影响性能。
5.分阶段处理任务的 Phaser
Phaser 与 CountDownLatch、CyclicBarrier 相似,这里就不在详细介绍,推荐两篇博客可以参考:
J.U.C之synchronizer框架:Phaser
死磕 java同步系列之Phaser源码解析
四、Executor 框架
Java线程的创建与销毁需要一定的开销,如果我们每一个任务创建一个新线程来执行,这些线程的创建与销毁将消耗大量的计算资源。每次为一个任务创建一个新线程来执行,这种策略可能会使处于高负荷状态的应用最终崩溃。
在JDK5开始,把工作单元与执行机制分离开来。工作单元包括 Runnable 和 Callable,而执行机制由 Executor 框架提供。
1.1 Executor 框架简介
1.1.1 二级调度模型
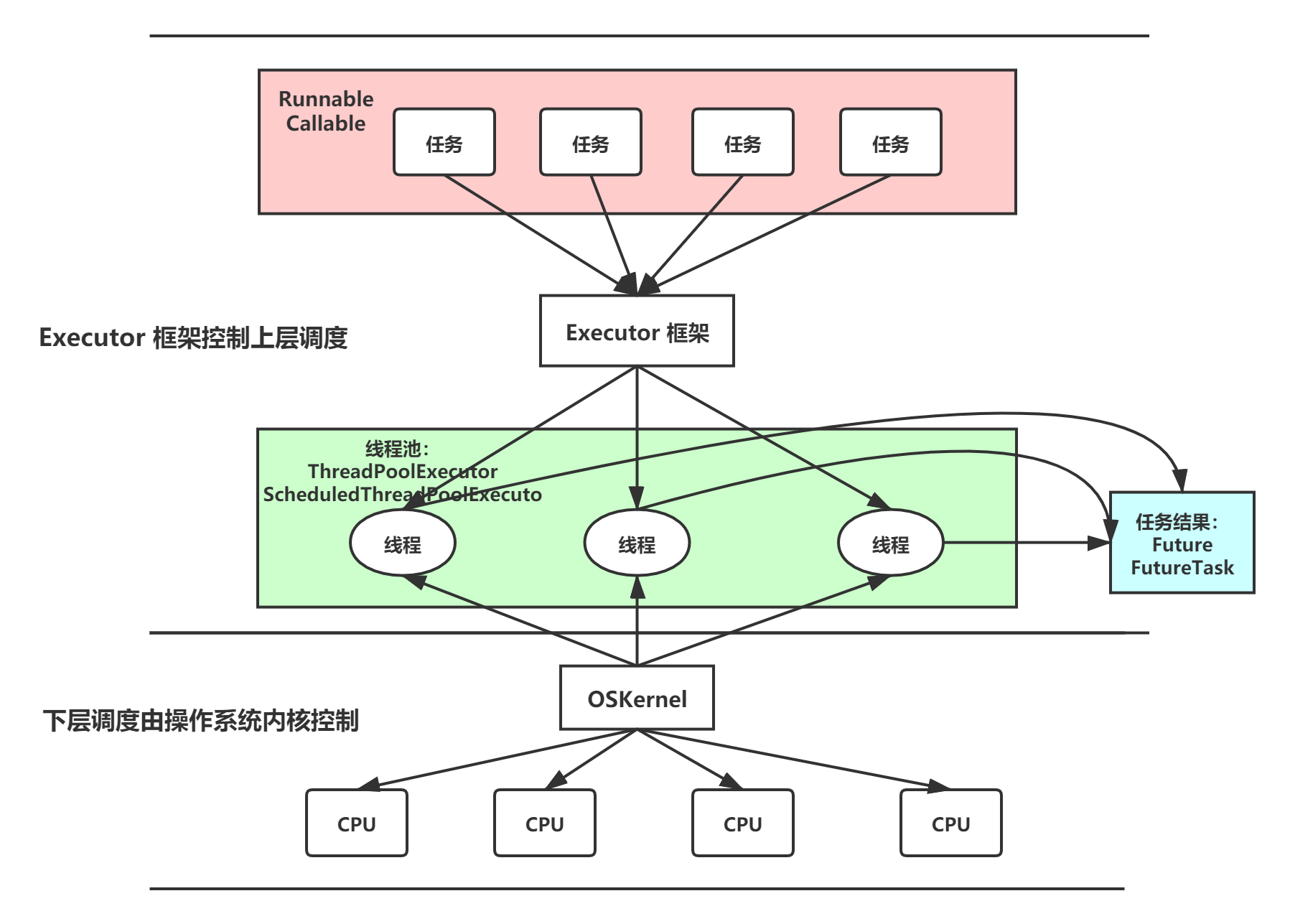
从图中可以看出,应用程序通过 Executor 框架控制上层的调度;而下层的调度由操作系统内核控制,下层的调度不受应用程序的控制。
1.1.2 Executor 结构与成员
1. Executor 框架的结构
从上面的二级调度模型也可以看出 Executor 框架主要由3大部分组成如下。
- 任务:也就是工作单元,包括被执行任务需要实现的接口:Runnable接口或者Callable接口;
- 任务的执行:也就是把任务分派给多个线程的执行机制,包括Executor接口及继承自Executor接口的ExecutorService接口。
- 异步计算的结果:包括Future接口及实现了Future接口的FutureTask类。
Executor 框架类与接口:
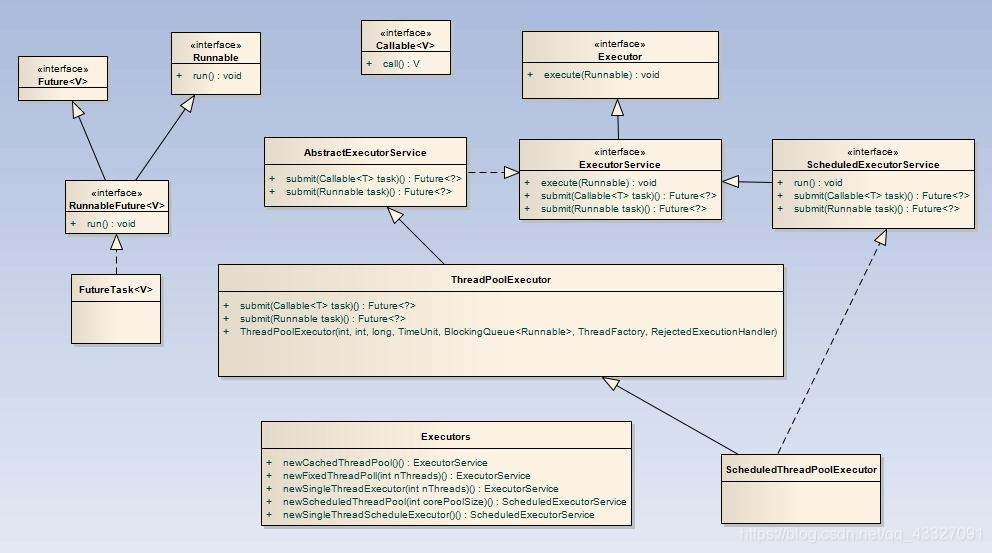
Executor 框架的使用示意图:
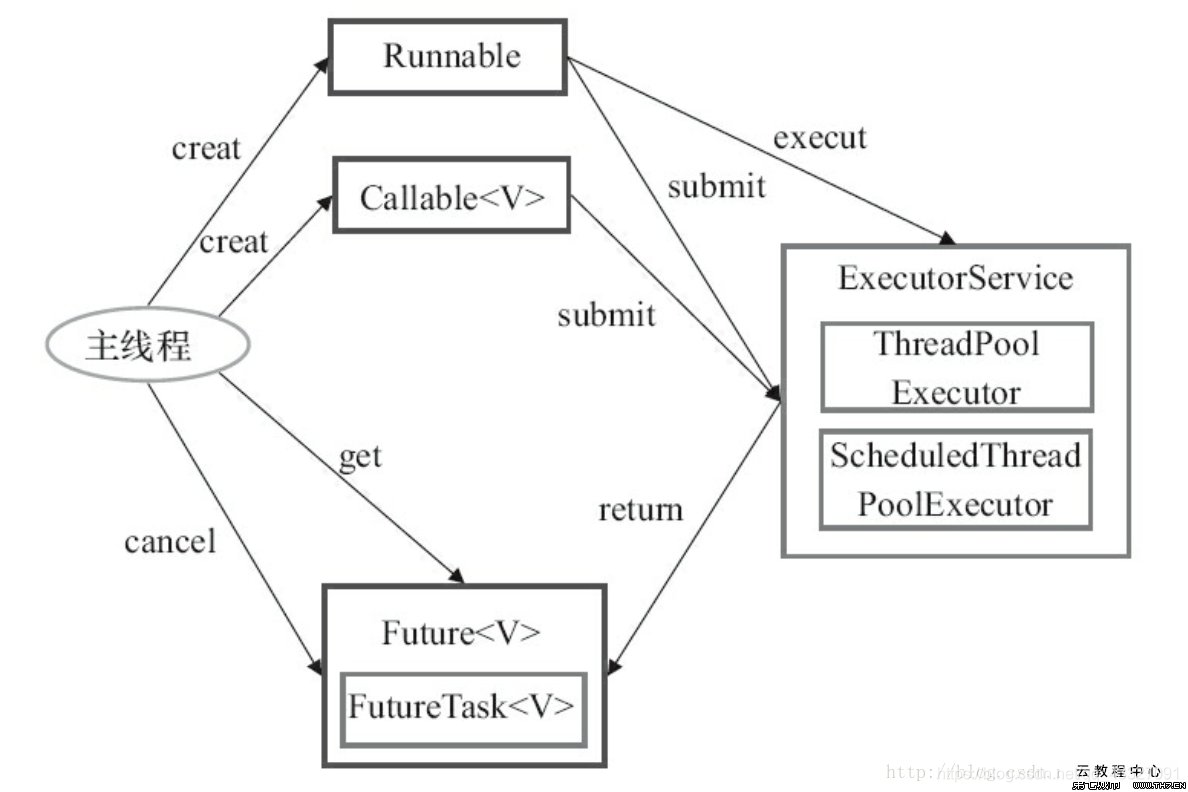
2. Executor 框架的成员
Executor 框架的主要成员:ThreadPoolExecutor、ScheduledThreadPoolExecutor、Future 接口、Runnable 接口、Callable 接口和 Executors。
-
ThreadPoolExecutor
ThreadPoolExecutor 通常使用工厂类 Executors 来创建。Executors 可以创建3种类型 ThreadPoolExecutor:SingleThreadExecutor、FixedThreadPool、CacheThreadPoolpublic static ExecutorService newXxxx(..) (直接调用 Executors.newXxx() 即可)1)FixedThreadPool:适用于为了满足资源管理的需求,而需要限制当前线程数量的应用场景,它适用于负载比较重的服务器。
2)SingleThreadExecutor:创建单个线程,适用于需要保证顺序地执行各个任务;并且在任意时间点,不会有多个线程是活动的应用场景。
3)CacheThreadPool:大小无界的线程池,适用于执行很多的短期异步任务的小程序,或者是负载较轻的服务器。 -
ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor 通常使用工厂类 Executors 来创建。Executors 可以创建2种类型的 ScheduledThreadPoolExecutor:ScheduledThreadPoolExecutor、SingleThreadScheduledExecutorpublic static ScheduledExecutorService newXxxx(..)1)ScheduledThreadPoolExecutor:适用于需要多个后台线程执行周期任务,同时为了满足资源管理的需求而需要限制后台线程的数量的应用场景。
2)SingleThreadScheduledExecutor:创建单个线程,适用于需要单个后台线程执行周期任务,同时需要保证顺序执行各个任务的应用场景。 -
Future 接口
Future 接口和实现 Future 接口的 FutureTask 类用来表示异步计算结果。当我们把Runnable接口或Callable接口的实现类提交(submit)给 ThreadPoolExecutor 或 ScheduledThreadPoolExecutor 时,它们会返回一个 FutureTask 对象(JDK8)。<T> Future<T> submit(Callable<T> task) <T> Future<T> submit(Runnable<T> task, T result) Future<?> submit(Runnable task) -
Runnable 接口和 Callable 接口
Runnable接口和Callable接口的实现类,都可以被 ThreadPoolExecutor 或 ScheduledThreadPoolExecutor 执行。它们之间的区别是 Runnable 不会返回结果,而Callable 可以返回结果。// 使用工厂类 Executors 来把一个Runnable包装成一个Callable public static Callable<Object> callable(Runnable task) // 将Runnable和待返回结果包装为一个Callable public static <T> Callable<T> callable(Runnable task, T result)使用
FutureTask.get()将返回该任务的结果。Callable1返回结果为null,Callable2返回结果为result 对象。
1.2 ThreadPoolExecutor 原理分析
JUC Executor-ThreadPoolExecutor(线程池) 源码解析
1.3 ScheduledThreadPoolExecutor、FutureTask
ScheduledThreadPoolExecutor 与 ThreadPoolExecutor 类似,只不过增加了对时间的控制以及在ScheduledThreadPoolExecutor 类中自定义了任务队列 DelayedWorkQueue(采用堆的方式)。
FutureTask 底层采用AQS来实现了任务结果的获取。
可以参考下面博客,进一步了解:
深入理解Java线程池:ScheduledThreadPoolExecutor
FutureTask源码解析
