Chapter07 | 抽取数据之正则表达式
在说正则表达式之前,先说以以下网页结构
根据网站的组成结构,网站可以分为以下两种
一、网页介绍
1、网站
- 静态网站:
纯粹采用HTML语言编写,内容不变 - 动态网站:
①服务器段动态生成:使用ASP、PHP等语言进行编写,在服务器端运行,根据浏览器请求的地址及参数,动态从数据库中读取数据,并填入预先写好的模板中,实时生成所需要的HTML网页,返回给浏览器,在浏览器看来跟静态网站没有区别
②浏览器端动态加载:随时能实现更新,使用Javascript,AJAX渲染加载内容
对于爬虫而言:
- 服务器端动态生成的网页,因为使用了模板,可以较方便地从大量非常相似的网页中抽取感兴趣的内容和数据,相当于还原了服务器的后台数据库
- 使用正则表达式等工具,直接从HTML页面匹配内嵌的内容
- 通过分析AJAX,以及Javascript等脚本,匹配动态加载的内容
不论静态还是动态网站,HTML页面"隐藏"有价值的数据信息
- 动态网站的部分数据由脚本动态加载
使用网络爬虫提取信息,需要了解页面的HTML标签使用和分布情况
2、HTML语言
- HTML(超文本标记语言,Hypertext Markup Language)是制作网页内容的一种标签语言
- HTML通过在内容上附加各种标签,在浏览器中正确展示内容
- HTML描述网页格式设计,与其它网页的连接信息
- HTML不需要编译,直接由浏览器执行
一个完整的HTML文件包括:
- 文件内容(文字链接等)
- HTML标签
一般HTML文件的书写遵循以下格式:
- <标签名>文件内容(受标签影响的文本)</标签名>

HTML的标签数:
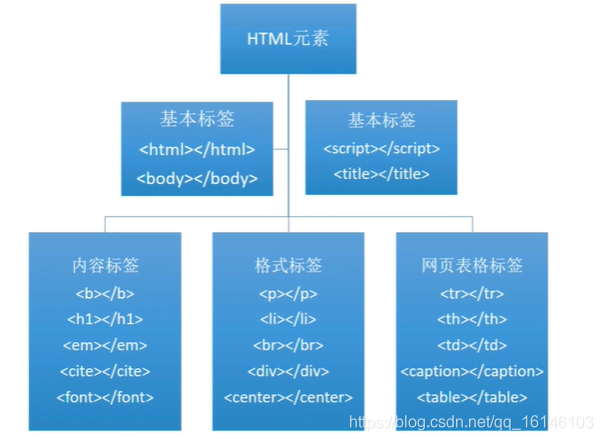
HTML文件的内容均包含在标签中: - 嵌入标签的内容作为HTML的头
- 嵌入标签的内容为文件的内容主题

3、从网页中提取数据
借助Python网络库,构建的爬虫可以抓取HTML页面的数据
从抓取的页面数据中提取有价值的数据,有以下方式:
- 正则表达式
- lxml
- BeautifulSoup
二、正则表达式
面对复杂的HTML页面,经常需要从中抽取需要的信息,比如身份证号等
使用简介的字符串表达式,来去匹配这些信息:
- 匹配居民身份证
(^\d{15}$)|)^\d{17}([0-9]|X)$)
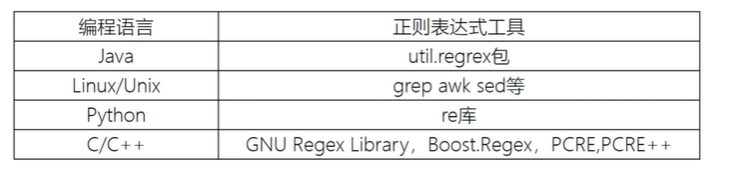
正则表达式有独立的语法以及处理引擎,在支持正则表达式的语言中,正则表达式的语法一致
不同的编程语言实现支持的语法数量不同:
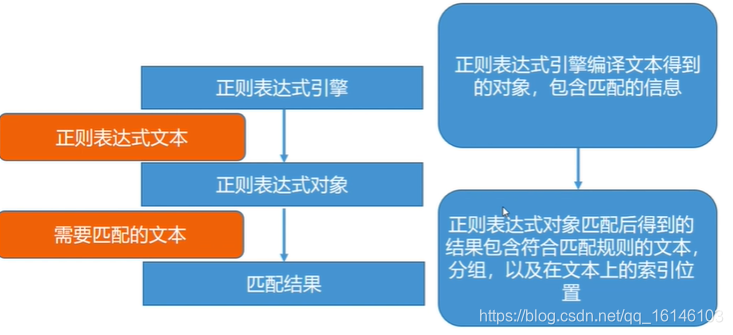
1、正则表达式的工作流程
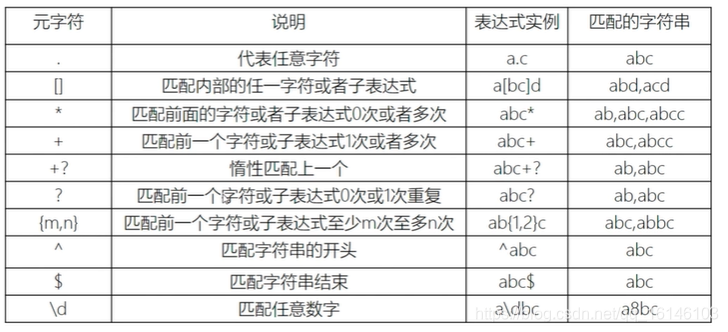
2、正则表达式的语言
正则表达式语言由两种基本字符类型组成
- 原生(正常)文本字符
- 元字符
3、正则表达式的分组
- 使用正则表达式匹配重复字符串,只需在字符后面加上相应的元字符
如果要匹配重复的字符串,使用小括号()把目标字符串包裹起来
- (abc)?可以匹配0个或者多个字符串abc
分组可以分为两种形式:
- 捕获组和非捕获组
4、正则表达式的捕获
- 小括号包裹起来的表达式去匹配字符串,匹配的结果可以在后续的匹配过程中使用
- 把表达式中的括号进行编号,从左到右,以左括号出现的前后顺序为准,第一个出现的分组,组号即为1.
- 组号0代表正则表达式整体
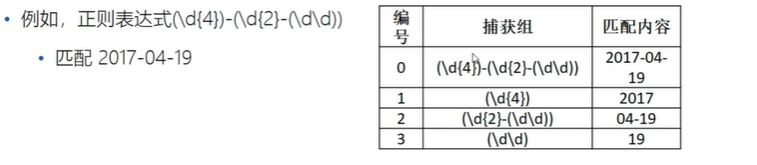
5、非捕获组和捕获组
- 非捕获组是指以(?)开头的分组组,它不捕获文本,没有分组编号,也不针对组合计进行计数
- 捕获组会默认把括号里的文本捕获过来以供下次使用。如果只是需要正则匹配,没有额外需求,使用非捕获组可以完成任务,降低资源消耗
eg:匹配0到100范围内的整数

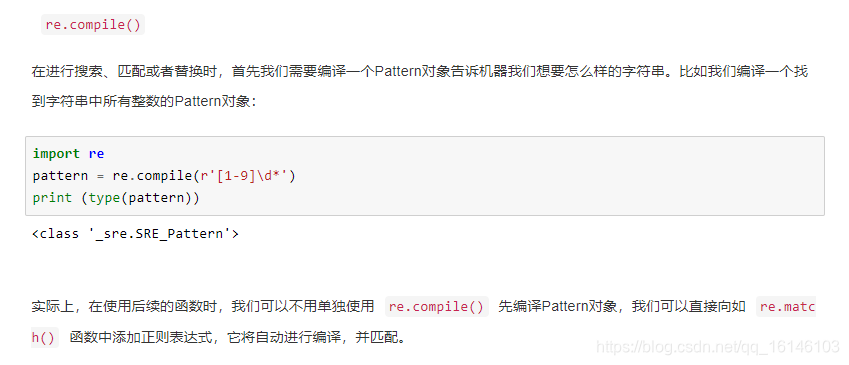
三、re库
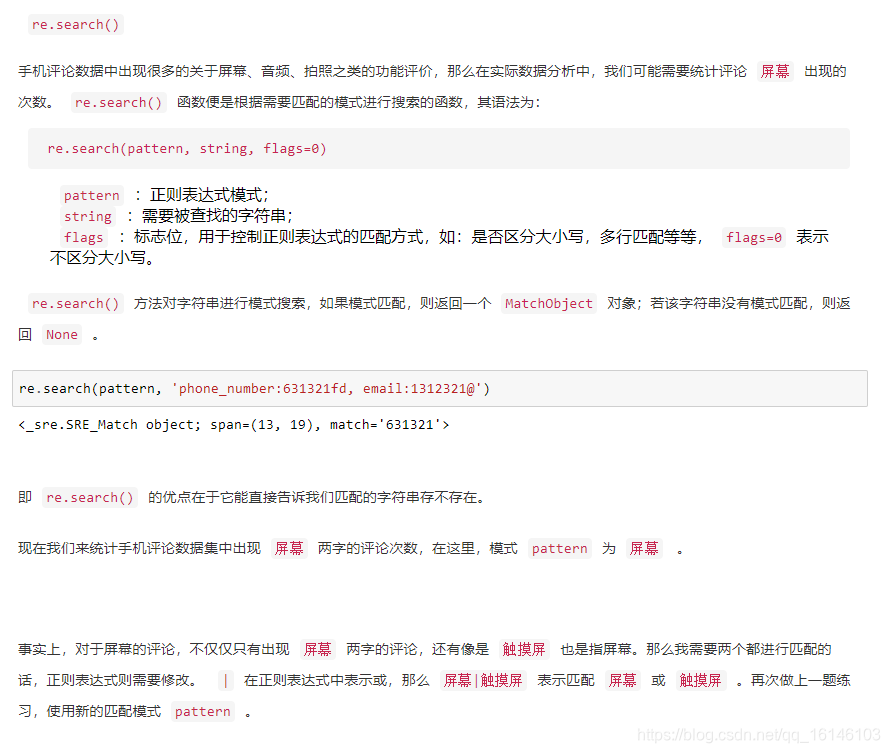
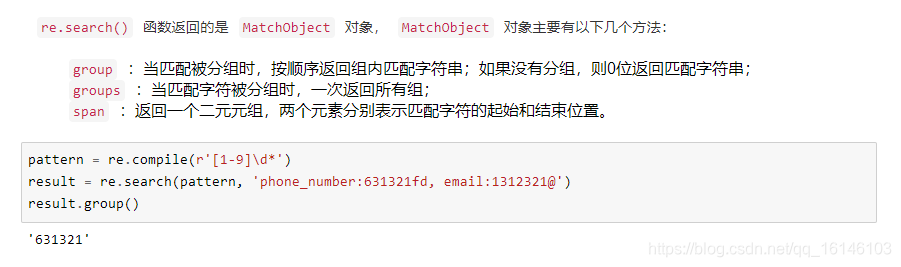
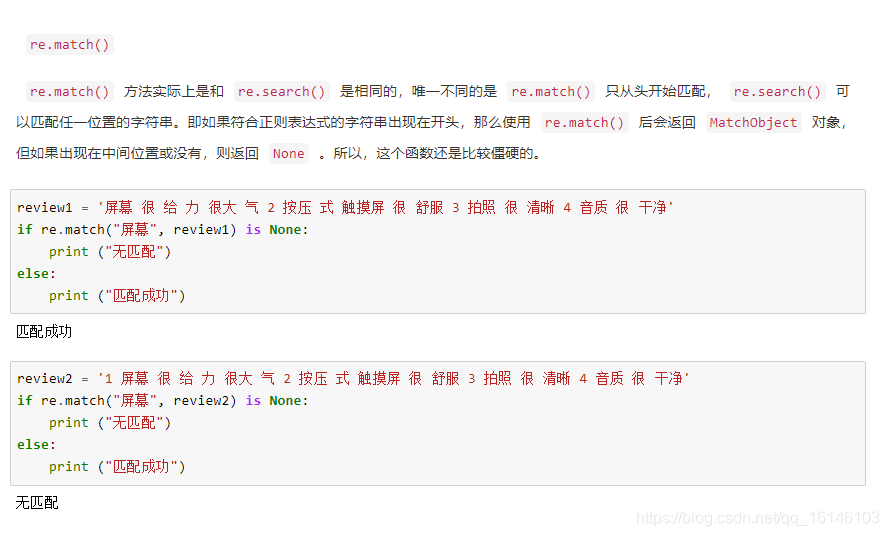
re是专门用于处理正则表达式的Python模块,通常有以下几个函数:

下面依次进行说明