- 在不同的存储引擎中使用
在MySQL中,日常开发中比较常用的有MyISAM和InnoDB两种存储引擎。两者之间的其中一个区别是使用count(*)函数计算表的具体行数。
因为MyISAM会保存表的具体行数,因此这段代码在MyISAM存储引擎中执行,MyISAM只要简单地读出保存好的行数即可。因此,如果表中没有使用事务之类的操作,这是最好的优化方案。然而,InnoDB存储引擎不会保存表的具体行数,因此,在InnoDB存储引擎中执行这段代码,InnoDB要扫描一遍整个表来计算有多少行。
- count(*)函数执行原理
在不同的存储引擎中,count(*)函数的执行是不同的。在MyISAM存储引擎中,count(*)函数是直接读取数据表保存的行记录数并返回,而在InnoDB存储引擎中,count(*)函数是先从内存中读取表中的数据到内存缓冲区,然后扫描全表获得行记录数的。
在使用count函数中加上where条件时,在两个存储引擎中的效果是一样的,都会扫描全表计算某字段有值项的次数。当统计带有WHERE子句的结果集行数时,可以是统计某个列值的数量时,MyISAM的COUNT()和其他存储引擎没有任何不同,也就不再是神话般的速度了。
- 使用近似值
有些时候并不需要完全精确的COUNT的值,此时可以用近似值来代替。EXPLAIN出来的优化器估算的行数就是一个不错的近似值,执行EXPLAIN并不需要真正去执行查询,所以成本很低。
explain 命令速度很快,因为 explain 用并不真正执行查询,而是查询优化器【估算】的行数。
- 区分(不同的count使用方式)
count(主键 id)
InnoDB 引擎会遍历整张表,把每一行的 id 值都取出来,返回给 server 层。server 层拿到 id 后,判断是不可能为空的,就按行累加。
count(1)
InnoDB 引擎遍历整张表,但不取值。server 层对于返回的每一行,放一个数字“1”进去,判断是不可能为空的,按行累加。
count(1) 执行得要比 count(主键 id) 快。因为从引擎返回 id 会涉及到解析数据行,以及拷贝字段值的操作。
count(字段)
如果这个“字段”是定义为 not null 的话,一行行地从记录里面读出这个字段,判断不能为 null,按行累加;
如果这个“字段”定义允许为 null,那么执行的时候,判断到有可能是 null,还要把值取出来再判断一下,不是 null 才累加。
但是 count(*) 是例外
并不会把全部字段取出来,而是专门做了优化,不取值。count(*) 肯定不是 null,按行累加。
所以结论是:按照效率排序的话,count(字段)<count(主键 id)<count(1)≈count(*),建议尽量使用 count(*)或count(1)。
下面做个count优化例子:
1.首先我们创建一直innodb表,并包含大字段(或包含较多字段):
CREATE TABLE `qstardbcontent` (
`id` BIGINT(20) NOT NULL DEFAULT '0',
`content` MEDIUMTEXT,
`length` INT(11) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8
2.插入50万条数据,每条数据 5K
3.执行select count(*) from qstardbcontent

可以看到,近50万条内容较多的数据执行一个count(*) 就需要耗时 13分28秒
下面我们做个优化,在length字段上加个索引, 执行sql: ALTER TABLE qstardbcontent ADD KEY(LENGTH);
索引建完成后,再执行 select count(*) from qstardbcontent;
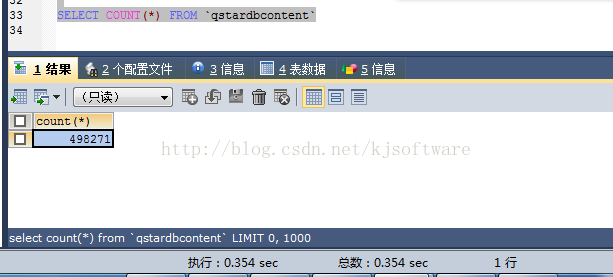
可以看到,整个统计查询非常快,仅用了 354毫秒就完成了查询。
