一般情况下,数据库去重复有以下那么三种方法:
第一种:
两条记录或者多条记录的每一个字段值完全相同,这种情况去重复最简单,用关键字distinct就可以去掉。例:
SELECT DISTINCT * FROM TABLE
使用 distinct:
使用distinct去重,只能去掉重复记录,有些场景也并不是很适用,分场景而异
第二种:
两条记录之间之后只有部分字段的值是有重复的,但是表存在主键或者唯一性ID。如果是这种情况的话用DISTINCT是过滤不了的,这就要用到主键id的唯一性特点及group by分组。例:
SELECT * FROM TABLE
WHERE ID
IN
(SELECT MAX(ID) FROM TABLE GROUP BY [去除重复的字段名列表,....])
第三种:
两条记录之间之后只有部分字段的值是有重复的,但是表不存在主键或者唯一性ID。这种情况可以使用临时表,讲数据复制到临时表并添加一个自增长的ID,在删除重复数据之后再删除临时表。例:
//创建临时表,并将数据写入到临时表
SELECT IDENTITY(INT1,1) AS ID,* INTO NEWTABLE(临时表) FROM TABLE
//查询不重复的数据
SELECT * FROM NEWTABLE WHERE ID IN (SELECT MAX(ID) FROM NEWTABLE GROUP BY [去除重复的字段名列表,....])
//删除临时表
DROP TABLE NEWTABLE
几个简单的小案例分享一下:
案例1:
需求:去重重复数据,值保留一条数据(重复数据完全相同,表并未设置主键)
第一步:先找出表中重复的数据:
SELECT
CODE,
NAME,
PCODE,
count(*) AS count
FROM
lp_area_code_new_bak
GROUP BY
`CODE`
HAVING
count > 1

重复数据共12条:
第二步:查出不重复的数据:

数据一共:
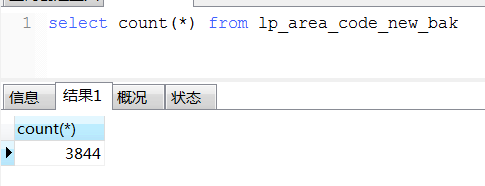
去掉重复数据12条:3844-12=3832条
建个临时表,然后数据覆盖就解决问题了!
(有时脑袋就是转不过弯来,拍一下就出来了 哈哈)
案例2:
需求分析
数据库中存在重复记录,删除保留其中一条(是否重复判断基准为多个字段)
大概也分为3步来理解:
第一步:
查询出重复记录形成一个集合(临时表t2),集合里是每种重复记录的最小ID
(
SELECT
min(id) id,
user_id,
monetary,
consume_time
FROM
consum_record
GROUP BY
user_id,
monetary,
consume_time
HAVING
count(*) > 1
) t2
第二步:
关联 判断重复基准的字段
consum_record.user_id = t2.user_id
AND consum_record.monetary = t2.monetary
AND consum_record.consume_time = t2.consume_time
第三步:
根据条件,删除原表中id大于t2中id的记录
最后SQL合并一下为:
DELETE consum_record
FROM
consum_record,
(
SELECT
min(id) id,
user_id,
monetary,
consume_time
FROM
consum_record
GROUP BY
user_id,
monetary,
consume_time
HAVING
count(*) > 1
) t2
WHERE
consum_record.user_id = t2.user_id
and consum_record.monetary = t2.monetary
and consum_record.consume_time = t2.consume_time
AND consum_record.id > t2.id;
