回归与梯度下降:
- 回归(回归和分类)
在数学上来说是给定一个点集,能够用一条曲线去拟合之,如果这个曲线是一条直线,那就被称为线性回归,如果曲线是一条二次曲线,就被称为二次回归,回归还有很多的变种,如locally
weighted回归,logistic回归,等等
- 梯度下降
图中给出了训练集,拟合函数,输出数据,输入数据的维度(特征的个数,features),n
我们用X1,X2…Xn
去描述feature里面的分量,比如x1=房间的面积,x2=房间的朝向,等等,我们可以做出一个估计函数:(相当于对于每一个特征都置一个权重最终的得到一个权重集合,梯度下降要做的事情就是不断优化该参数θ,使得最终预测值与实际值的误差降低到最小)
输出值
矩阵形式
误差函数
从误差函数讲起,我的理解就是此时要求的θ应该是使得J(θ)最小,那不妨把J(θ)直接看成关于θ的一个函数(其实本来就是 手动狗头),然后J和θ就分别对应了我们中学学的xy轴(其实是多维的为了方便理解暂定二维)这是要想求得的最佳θ(x)值,正是J(y)为0的点,该点的特征是梯度为0(y对x求导导数为0)——梯度下降目的达成
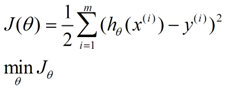
- 什么是梯度
:在数学上,对于一个可微分的函数f(x,y,z),向量grad称为f(x,y,z)的梯度。
- 为什么要求梯度向量(求最小化的)
因为沿梯度方向时,方向导数取得最大值,计算速度最快。因此,在求解损失函数的最小值时,可以通过梯度下降法来一步步的迭代求解,得到最小化的损失函数和模型参数值。梯度下降法的计算过程就是沿梯度下降的方向求解极小值。当梯度向量为零,说明到达一个极值点,这也是梯度下降算法迭代计算的终止条件。
在大多数神经网络深度学习算法中都会涉及到某种形式的优化,而目前深度学习优化中运用最多的就是随机梯度下降法。因此,梯度下降法作为一个最优化算法,常用于机器学习和人工智能当中用来递归性地逼近最小偏差模型。
我们可以通过下面两份图直观理解。
当我们初始点在A点时,根据梯度下降法,会从点A开始,沿下降最快的方向,即梯度方向寻找到附近的最低点C。但是,我们知道D点才是整个图像的最低点。但是,从A沿梯度方向时寻找不到D,只有从B点开始才能找到D。也就是说,初始点不同,沿梯度方向寻找的最小点是不同的。因此,梯度下降法只能达到局部最优,而不能达到全局最优。只有当函数为凸函数时,才是全局最优。
在实际使用梯度下降时,我们还需要对算法参数进行调优,以避免一些不必要的错误。首先,数据归一化处理。不仅在梯度下降算法需要对数据归一化处理,在许多算法使用之前都需要对数据归一化处理。这是因为样本不同特征的量纲不一样,取值范围不一样,会导致计算量很多,从而导致计算速度很慢。这是我们首先要避免的。
首先,数据归一化处理。不仅在梯度下降算法需要对数据归一化处理,在许多算法使用之前都需要对数据归一化处理。这是因为样本不同特征的量纲不一样,取值范围不一样,会导致计算量很多,从而导致计算速度很慢。这是我们首先要避免的。
归一化 是深度学习模型输入数据之前要进行一项很重要的操作。在不同的评价指标中,量纲单位往往不同,变化区间处于不同的数量级,若不进行归一化,会导致某些指标被忽视,从而影响到数据分析的结果。归一化本身就是把你需要的数据经过一定的处理限制在一定的范围内。在统计学上,归一化的具体作用是归纳统一样本的统计分布性。归一化在0-1之间是统计的概率分布,归一化在-1,1之间是统计的坐标分布最后,参数初始值的选择。上面我们说过对于非凸函数,梯度下降法只能达到局部最优。因此,初始值不同,获得的最优解也有所不同,所以需要多次用不同初始值运行算法,得到损失函数的局部最小值,选择使得损失函数全局最小化的初值。
此部分转载自 https://baijiahao.baidu.com/s?id=1612925424330804001&wfr=spider&for=pc
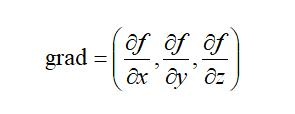


简介梯度消失与梯度爆炸
层数比较多的神经网络模型在训练的时候会出现梯度消失和梯度爆炸问题。梯度消失问题和梯度爆炸问题一般会随着网络层数的增加变得越来越明显。
梯度不稳定问题
在深度神经网络中的梯度是不稳定的,在靠近输入层的隐藏层中或会消失,或会爆炸。这种不稳定性才是深度神经网络中基于梯度学习的根本问题。
梯度不稳定的原因:前面层上的梯度是来自后面层上梯度的乘积。当存在过多的层时,就会出现梯度不稳定场景,比如梯度消失和梯度爆炸。
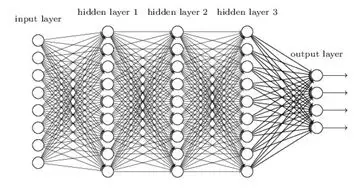
例如,对于图1所示的含有3个隐藏层的神经网络,梯度消失问题发生时,靠近输出层的hidden layer3的权值更新相对正常,但是靠近输入层的hidden layer1的权值更新会变得很慢,导致靠近输入层的隐藏层权值几乎不变,扔接近于初始化的权值。这就导致hidden layer 1 相当于只是一个映射层,对所有的输入做了一个函数映射,这时此深度神经网络的学习就等价于只有后几层的隐藏层网络在学习。
梯度爆炸的情况是:当初始的权值过大,靠近输入层的hidden layer 1的权值变化比靠近输出层的hidden layer 3的权值变化更快,就会引起梯度爆炸的问题。
梯度消失
定义
在神经网络中,当前面隐藏层的学习速率低于后面隐藏层的学习速率,即随着隐藏层数目的增加,分类准确率反而下降了。这种现象叫做消失的梯度问题
解决方法
1 预训练加微调:提出采取无监督逐层训练方法,其基本思想是每次训练一层隐节点,训练时将上一层隐节点的输出作为输入,而本层隐节点的输出作为下一层隐节点的输入,此过程就是逐层“预训练”(pre-training);在预训练完成后,再对整个网络进行“微调”此思想相当于是先寻找局部最优,然后整合起来寻找全局最优。
2 梯度剪切、正则:
梯度剪切这个方案主要是针对梯度爆炸提出的,其思想是设置一个梯度剪切阈值,然后更新梯度的时候,如果梯度超过这个阈值,那么就将其强制限制在这个范围之内。权重正则化(weithts
regularization)比较常见的是l1正则,和l2正则,在各个深度框架中都有相应的API可以使用正则化,比如在tensorflow中,若搭建网络的时候已经设置了正则化参数,则调用以下代码可以直接计算出正则损失:
regularization_loss=tf.add_n(tf.losses.get_regularization_losses(scope=‘my_resnet_50’))
如果没有设置初始化参数,也可以使用以下代码计算l2正则损失: l2_loss = tf.add_n([tf.nn.l2_loss(var)
for var in tf.trainable_variables() if ’ weights’ in var.name])
relu、leakrelu、elu等激活函数
Relu:如果激活函数的导数为1,那么就不存在梯度消失的问题了,每层的网络都可以得到相同的更新速度,relu就这样应运而生。
梯度爆炸
什么是梯度爆炸
误差梯度 是神经网络训练过程中计算的方向和数量,用于以正确的方向和合适的量 更新网络权重。 (依旧是自己的理解::在上文的梯度下降中已经提到我们的目得是根据J对θ的求导从而得到梯度下降的方向,进而调整θ的值,当产生误差梯度的时候,方向都错了,θ的取值也会发生很大的误差) 在深层网络或循环神经网络中,误差梯度可在更新中累积,变成非常大的梯度,然后导致网络权重的大幅更新,并因此使网络变得不稳定。在极端情况下,权重的值变得非常大,以至于溢出,导致NaN 值。 网络层之间的梯度(值大于 1.0)重复相乘导致的指数级增长会产生梯度爆炸。
梯度爆炸引发的问题
在深度多层感知机网络中,梯度爆炸会引起网络不稳定,最好的结果是无法从训练数据中学习,而最坏的结果是出现无法再更新的 NaN 权重值
-如何修复梯度爆炸问题
有很多方法可以解决梯度爆炸问题,本节列举了一些最佳实验方法。
1 重新设计网络模型 在深度神经网络中,梯度爆炸可以通过重新设计层数更少的网络来解决。 使用更小的批尺寸对网络训练也有好处。 在循环神经网络中,训练过程中在更少的先前时间步上进行更新(沿时间的截断反向传播,truncated Backpropagation
through time)可以缓解梯度爆炸问题。
2. 使用 ReLU 激活函数 在深度多层感知机神经网络中,梯度爆炸的发生可能是因为激活函数,如之前很流行的 Sigmoid 和 Tanh 函数。 使用 ReLU 激活函数可以减少梯度爆炸。采用 ReLU 激活函数是最适合隐藏层的新实践。
3. 使用长短期记忆网络 在循环神经网络中,梯度爆炸的发生可能是因为某种网络的训练本身就存在不稳定性,如随时间的反向传播本质上将循环网络转换成深度多层感知机神经网络。
使用长短期记忆(LSTM)单元和相关的门类型神经元结构可以减少梯度爆炸问题。 采用 LSTM单元是适合循环神经网络的序列预测的最新最好实践。
4. 使用梯度截断(Gradient Clipping) 在非常深且批尺寸较大的多层感知机网络和输入序列较长的 LSTM 中,仍然有可能出现梯度爆炸。 如果梯度爆炸仍然出现,你可以在训练过程中检查和限制梯度的大小。这就是梯度截断。
部分参考该文章http://baijiahao.baidu.com/s?id=1587462776558160221&wfr=spider&for=pc
