引言
step, iteration, epoch, batchsize, learning rate都是针对模型训练而言的,是模型训练中设置的超参数。
样本
在机器学习中,样本是指数据集中的一部分完整的数据个体。例如学生成绩表中学生A的所有科目的成绩,手写数字数据集中的某一幅数字图片。
什么是正样本?
所谓正样本是指希望正确分类出的类别多对应的样本。例如判断一张人物头像照片是否为男性。那么在数据训练的时候,男性图片就是正样本,负样本就是女性照片了。
step, 也称为iteration
通常被译为迭代,每次迭代会更新模型的参数
epoch
通常被译为轮数,是指训练数据集中的所有样本(数据)输入模型被“轮”(即训练)的次数。
为什么需要多个epoch?
模型训练需要将训练集数据在模型中训练多次,通过梯度下降的方式优化模型参数,获得最优的模型(Optimum)。epoch太小会导致欠拟合(underfitting),epoch太大会导致过拟合(overfitting)。
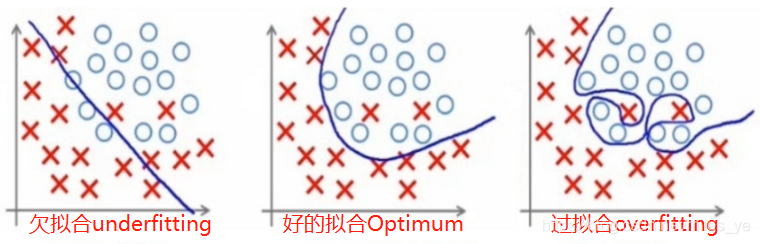
多少个epoch才合适?
这个问题没有正确的答案。需要根据不同的应用和训练集给出比较合适的epoch值。这也就是超参数的优选设置问题。
两个epoch之间有什么关系?
上一个epoch会将模型参数(例如:神经网络的w和b)传递给下一个epoch。
注意:每次epoch之后,需要对训练数据集进行shuffle,再进入下一轮训练。
batchsize
batch
通常被译为批,是指从训练集中抽取一个子集(是训练数据集的一部分)进行模型的训练,就算一次损失函数(Loss Function)。
为什么需要batch?
为了在内存效率和内存容量之间寻找最佳平衡
batchsize
通常被译为批大小,是指一次模型训练所需的样本数量,也就是一个batch(批)中的样本(数据)数量。
如何设置batchsize?
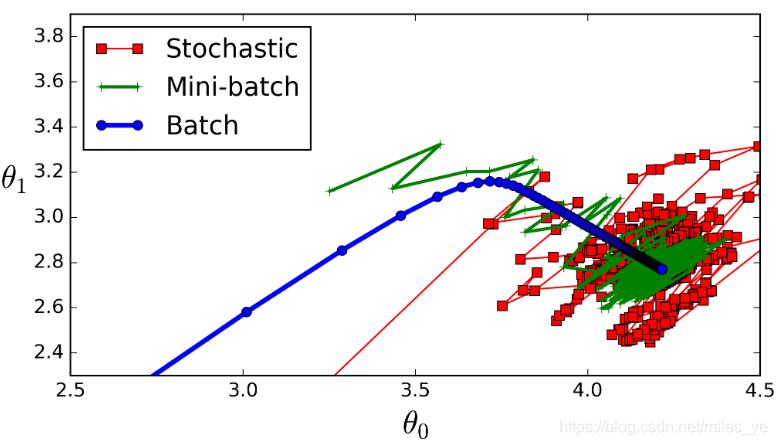
- 上图红色为Stochastic (随机),指batchsize=1,用一个样本进行一次模型训练,更新一次下降的梯度。使用这种模型训练的方式称为随机梯度下降(SGD,Stochastic Gradient Descent)。这种方式训练速度较快,但收敛性不好。从图中可以看到这种方式收敛速度慢,往往难以达到收敛。
- 上图绿色为Mini-batch(迷你),也就是通常所说的batchsize,其值介于Stochastic(上图红色)和Batch(上图蓝色)之间。将batchsize个样本输入模型,计算所有样本产生的平均损失值。使用这种模型训练的方式称为Mini-Batch Gradient Descent
- 上图蓝色为Batch(全批次),指batchsize为全部训练集中的样本,使用了全部训练数据集进行一次训练。使用这种模型训练的方式称为批梯度下降(BGD,Batch Gradient Descent)。当数据集较小时,全批次可以很好地表示总体样本,更准确地朝向梯度下降中极值。但是,计算量大,计算速度慢,不支持在线学习。当数据集较大时,更不能使用这种方式,效果更差。
