- 1:Flink table以及SQL的基本介绍
- Apache Flink 具有两个关系型API:Table API 和SQL,用于统一流和批处理。
- Table API 是用于 Scala 和 Java 语言的查询API,允许以非常直观的方式组合关系运算符的查询,例如 select,filter 和 join。Flink SQL 的支持是基于实现了SQL标准的 Apache Calcite。无论输入是批输入(DataSet)还是流输入(DataStream),任一接口中指定的查询都具有相同的语义并指定相同的结果。
- Table API和SQL接口彼此集成,Flink的DataStream和DataSet API亦是如此。我们可以轻松地在基于API构建的所有API和库之间切换。
- 注意,到目前最新版本为止,Table API和SQL还有很多功能正在开发中。 并非[Table API,SQL]和[stream,batch]输入的每种组合都支持所有操
- 2:为什么需要SQL
- Table API 是一种关系型API,类 SQL 的API,用户可以像操作表一样地操作数据, 非常的直观和方便。
- SQL 作为一个"人所皆知"的语言,如果一个引擎提供 SQL,它将很容易被人们接受。这已经是业界很常见的现象了
- Table & SQL API 还有另一个职责,就是流处理和批处理统一的API层。
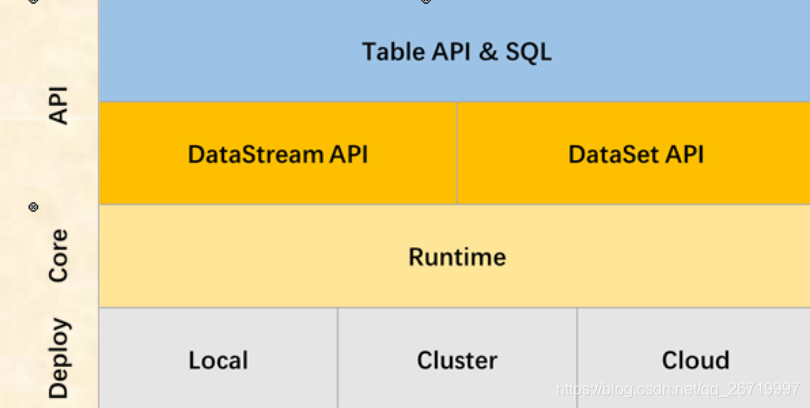
- 3:Flink Table & SQL编程开发
-
官网介绍:https://ci.apache.org/projects/flink/flink-docs-release-1.8/dev/table/
-
Flink的tableAPI允许我们对流式处理以及批量处理都使用sql语句的方式来进行开发。只要我们知道了dataStream或者dataSet可以转换成为Table,那么我们就可以方便的从各个地方获取数据,然后转换成为Table,通过TableAPI或者SQL来实现我们的数据的处理等
-
Flink的表API和SQL程序可以连接到其他外部系统来读写批处理表和流表。Table source提供对存储在外部 系统(如数据库、键值存储、消息队列或文件系统)中的数据的访问。Table Sink将表发送到外部存储系统。
-
3.1 :1、使用FlinkSQL实现读取CSV文件数据,并进行查询
- 第一步:导入jar包
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-planner_2.11</artifactId> <version>1.8.1</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-api-scala-bridge_2.11</artifactId> <version>1.8.1</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-api-scala_2.11</artifactId> <version>1.8.1</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-common</artifactId> <version>1.8.1</version> </dependency>- 第二步:开发代码读取csv文件并进行查询
import org.apache.flink.core.fs.FileSystem.WriteMode import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment} import org.apache.flink.table.api.{Table, Types} import org.apache.flink.table.api.scala.StreamTableEnvironment import org.apache.flink.table.sinks.{CsvTableSink} import org.apache.flink.table.sources.CsvTableSource object FlinkStreamSQL { def main(args: Array[String]): Unit = { //流式sql,获取运行环境 val streamEnvironment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment //流式table处理环境 val tableEnvironment: StreamTableEnvironment = StreamTableEnvironment.create(streamEnvironment) //注册我们的tableSource val source: CsvTableSource = CsvTableSource.builder() .field("id", Types.INT) .field("name", Types.STRING) .field("age", Types.INT) .fieldDelimiter(",") .ignoreFirstLine() .ignoreParseErrors() .lineDelimiter("\r\n") .path("D:\\flinksql.csv") .build() //将tableSource注册成为我们的表 tableEnvironment.registerTableSource("user",source) //查询年龄大于20岁的人 val result: Table = tableEnvironment.scan("user").filter("age >20") //打印我们表的元数据信息===》也就是字段信息 //将查询出来的结果,保存到我们的csv文件里面去 val sink = new CsvTableSink("D:\\sink.csv","===",1,WriteMode.OVERWRITE) result.writeToSink(sink) streamEnvironment.execute() } } -
3.2:DataStream与Table的互相转换操作
- DataStream转换成为Table说明:
- 我们也可以将dataStream,流式处理的数据处理成为一张表,然后通过sql语句进行查询数据,读取socket当中的数据,然后进行数据统计,并将结果保存到本地文件。
- 将DataStream转换成为Table,我们需要用到StreamExecutionEnvironment和StreamTableEnvironment这两个对象获取StreamTableEnvironment 对象,然后调用fromDataStream或者registerDataStream就可以将我们的DataStream转换成为Table
- Table转换成为DataStream说明
- 我们也可以将我们处理完成之后的Table转换成为DataStream,将Table转换成为DataStream可以有两种模式
- 第一种方式:AppendMode
- 将表附加到流数据,表当中只能有查询或者添加操作,如果有update或者delete操作,那么就会失败
- 只有在动态Table仅通过INSERT更改修改时才能使用此模式,即它仅附加,并且以前发出的结果永远不会更新。如果更新或删除操作使用追加模式会失败报错
- 第二种模式:RetraceMode
- 始终可以使用此模式。返回值是boolean类型。它用true或false来标记数据的插入和撤回,返回true代表数据插入,false代表数据的撤回
- 第一种方式:AppendMode
- 我们也可以将我们处理完成之后的Table转换成为DataStream,将Table转换成为DataStream可以有两种模式
- 第一步:代码开发
import org.apache.flink.core.fs.FileSystem.WriteMode import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment} import org.apache.flink.table.api._ import org.apache.flink.api.scala._ import org.apache.flink.table.api.scala.StreamTableEnvironment import org.apache.flink.table.sinks.CsvTableSink object FlinkStreamSQL { def main(args: Array[String]): Unit = { val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment val streamSQLEnvironment: StreamTableEnvironment = StreamTableEnvironment.create(environment) val socketStream: DataStream[String] = environment.socketTextStream("node01",8000) //101,zhangsan,18 //102,lisi,20 //103,wangwu,25 //104,zhaoliu,8 val userStream: DataStream[User] = socketStream.map(x =>User(x.split(",")(0).toInt,x.split(",")(1),x.split(",")(2).toInt) ) //将我们的流注册成为一张表 streamSQLEnvironment.registerDataStream("userTable",userStream) //通过sql语句的方式来进行查询 //通过表达式来进行查询 //使用tableAPI来进行查询 // val table: Table = streamSQLEnvironment.scan("userTable").filter("age > 10") //使用sql方式来进行查询 val table: Table = streamSQLEnvironment.sqlQuery("select * from userTable") val sink3 = new CsvTableSink("D:\\sink3.csv","===",1,WriteMode.OVERWRITE) table.writeToSink(sink3) //使用append模式将Table转换成为dataStream,不能用于sum,count,avg等操作,只能用于添加数据操作 val appendStream: DataStream[User] = streamSQLEnvironment.toAppendStream[User](table) //使用retract模式将Table转换成为DataStream val retractStream: DataStream[(Boolean, User)] = streamSQLEnvironment.toRetractStream[User](table) environment.execute() } } case class User(id:Int,name:String,age:Int) - 第二步:socket发送数据
101,zhangsan,18 102,lisi,20 103,wangwu,25 104,zhaoliu,8
- DataStream转换成为Table说明:
-
3.3:DataSet与Table的互相转换操作
- 我们也可以将我们的DataSet注册成为一张表Table,然后进行查询数据,同时我们也可以将Table转换成为DataSet
import org.apache.flink.api.scala._ import org.apache.flink.api.scala.ExecutionEnvironment import org.apache.flink.core.fs.FileSystem.WriteMode import org.apache.flink.table.api.scala.BatchTableEnvironment import org.apache.flink.table.sinks.CsvTableSink object FlinkBatchSQL { def main(args: Array[String]): Unit = { val environment: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment val batchSQL: BatchTableEnvironment = BatchTableEnvironment.create(environment) val sourceSet: DataSet[String] = environment.readTextFile("D:\\dataSet.csv") val userSet: DataSet[User2] = sourceSet.map(x => { println(x) val line: Array[String] = x.split(",") User2(line(0).toInt, line(1), line(2).toInt) }) import org.apache.flink.table.api._ batchSQL.registerDataSet("user",userSet) //val table: Table = batchSQL.scan("user").filter("age > 18") //注意:user关键字是flink当中的保留字段,如果用到了这些保留字段,需要转译 val table: Table = batchSQL.sqlQuery("select id,name,age from `user` ") val sink = new CsvTableSink("D:\\batchSink.csv","===",1,WriteMode.OVERWRITE) table.writeToSink(sink) //将Table转换成为DataSet val tableSet: DataSet[User2] = batchSQL.toDataSet[User2](table) tableSet.map(x =>x.age).print() environment.execute() } } case class User2(id:Int,name:String,age:Int)- 注意事项
//flink代码开发需要导入隐式转换包 import org.apache.flink.api.scala._ //对于flink tableAPI或者SQL的开发,则需要导入隐式转换包 import org.apache.flink.table.api._ // 如果用到了flink当中的保留字段,需要转译 val table: Table = batchSQL.sqlQuery("select id,name,age from `user` ")
-
- 3.4 :小案例:FlinkSQL处理kafka的json格式数据
- Flink的SQL功能也可以让我们直接读取kafka当中的数据,然后将kafka当中的数据作为我们的数据源,直接将kafka当中的数据注册成为一张表,然后通过sql来查询kafka当中的数据即可,如果kafka当中出现的是json格式的数据,那么也没关系flink也可以与json进行集成,直接解析json格式的数据
- https://ci.apache.org/projects/flink/flink-docs-release-1.8/dev/table/connect.html
- 第一步:导入jar包
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-json</artifactId> <version>1.8.1</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka-0.11_2.11</artifactId> <version>1.8.1</version> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>1.1.0</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>1.7.25</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.25</version> </dependency>- 第二步:创建kafka的topic
cd /opt/install/kafka_2.11-1.1.0 bin/kafka-topics.sh --create --topic kafka_source_table --partitions 3 --replication-factor 1 --zookeeper node01:2181,node02:2181,node03:2181- 第三步:使用flink查询kafka当中的数据
import org.apache.flink.api.common.typeinfo.TypeInformation import org.apache.flink.core.fs.FileSystem.WriteMode import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.table.api.{Table, _} import org.apache.flink.table.api.scala.StreamTableEnvironment import org.apache.flink.table.descriptors.{Json, Kafka, Schema} import org.apache.flink.table.sinks.CsvTableSink object KafkaJsonSource { def main(args: Array[String]): Unit = { val streamEnvironment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment //隐式转换 //checkpoint配置 streamEnvironment.enableCheckpointing(100); streamEnvironment.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); streamEnvironment.getCheckpointConfig.setMinPauseBetweenCheckpoints(500); streamEnvironment.getCheckpointConfig.setCheckpointTimeout(60000); streamEnvironment.getCheckpointConfig.setMaxConcurrentCheckpoints(1); streamEnvironment.getCheckpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); val tableEnvironment: StreamTableEnvironment = StreamTableEnvironment.create(streamEnvironment) val kafka: Kafka = new Kafka() .version("0.11") .topic("kafka_source_table") .startFromLatest() .property("group.id", "test_group") .property("bootstrap.servers", "node01:9092,node02:9092,node03:9092") val json: Json = new Json().failOnMissingField(false).deriveSchema() //{"userId":1119,"day":"2017-03-02","begintime":1488326400000,"endtime":1488327000000,"data":[{"package":"com.browser","activetime":120000}]} val schema: Schema = new Schema() .field("userId", Types.INT) .field("day", Types.STRING) .field("begintime", Types.LONG) .field("endtime", Types.LONG) tableEnvironment .connect(kafka) .withFormat(json) .withSchema(schema) .inAppendMode() .registerTableSource("user_log") //使用sql来查询数据 val table: Table = tableEnvironment.sqlQuery("select userId,`day` ,begintime,endtime from user_log") table.printSchema() //定义sink,输出数据到哪里 val sink = new CsvTableSink("D:\\flink_kafka.csv","====",1,WriteMode.OVERWRITE) //注册数据输出目的地 tableEnvironment.registerTableSink("csvSink", Array[String]("f0","f1","f2","f3"), Array[TypeInformation[_]](Types.INT, Types.STRING, Types.LONG, Types.LONG),sink) //将数据插入到数据目的地 table.insertInto("csvSink") streamEnvironment.execute("kafkaSource") } } - 第四步:kafka当中发送数据
cd /opt/install/kafka_2.11-1.1.0 bin/kafka-console-producer.sh --topic kafka_source_table --broker-list node01:9092,node02:9092,node03:9092 # 发送数据格式如下 {"userId":19,"day":"2017-03-02","begintime":1585184021,"endtime":1585184041} {"userId":20,"day":"2017-03-02","begintime":1585184021,"endtime":1585184041} {"userId":21,"day":"2017-03-02","begintime":1585184021,"endtime":1585184041} {"userId":22,"day":"2017-03-02","begintime":1585184021,"endtime":1585184041} {"userId":23,"day":"2017-03-02","begintime":1585184021,"endtime":1585184041}
flink学习笔记-table与sql简介、编程开发及DataSet、DataStream与Table相互转换

猜你喜欢
转载自blog.csdn.net/qq_26719997/article/details/105109794
今日推荐
周排行