python的特性
Python是动态类型的,这意味着你不需要在声明变量时指定类型。你可以先定义x=111,然后 x=”I’m a string”,一点问题也不会有。
Python是面向对象语言,所有允许定义类并且可以继承和组合。Python没有访问访问标识如在C++中的public, private, 这就非常信任程序员的素质,相信每个程序员都是“成人”了~
在Python中,函数是一等公民。这就意味着它们可以被赋值,从其他函数返回值,并且传递函数对象。类不是一等公民。
写Python代码很快,但是跑起来会比编译型语言慢。幸运的是,Python允许使用C扩展写程序,所以瓶颈可以得到处理。Numpy库就是一个很好例子,因为很多代码不是Python直接写的,所以运行很快。
Python使用场景很多 – web应用开发,自动化,科学建模,大数据应用,等等。它也经常被看做“胶水”语言,使得不同语言间可以衔接上。
Python能够简化工作 ,使得程序员能够关心如何重写代码而不是详细看一遍底层实现。
python线程
Python实际上不允许多线程。它有一个threading包但是如果你想加快代码运行速度,或者想并行运行,这不是一个好主意。Python有一个机制叫全局解释器锁(GIL)。GIL保证每次只有一个线程在解释器中跑。一个线程获得GIL,之后再交给下一个线程。所以,看起来是多个线程在同时跑,但是实际上每个时刻只有CPU核在跑一个线程,没有真正利用多个CPU核跑多个线程。就是说,多个线程在抢着跑一个CPU核。
但是还是有使用threading包的情况的。比如你真的想跑一个可以线程间抢占的程序,看起来是并行的。或者有很长时间的IO等待线程,这个包就会有用。但是threading包不会使用多核去跑代码。
真正的多核多线程可以通过多进程,一些外部库如Spark和Hadoop,或者用Python代码去调用C方法等等来实现。
面向对象具体了解请点击
面向过程编程
面向过程的程序设计:核心是过程二字,过程指的是解决问题的步骤,即先干什么再干什么…面向过程的设计就好比精心设计好的一条流水线,是一种机械式的思维方式问题。
优点是:复杂度的问题流程化,进而简单化(一个复杂的问题,分成一个个小的步骤去实现,实现小的步骤将会非常简单)
缺点是:一套流水线或者流程就是用来解决一个问题,生产汽水的流水线无法生产汽车,即便是能,也得是大改,改一个组件,牵一发而动全身。
应用场景:一旦完成基本很少改变的场景,著名的例子有:Linux内核,git,以及Apache HTTP Server等。
面向对象编程
面向对象的程序设计:核心是对象二字,(要理解对象为何物,必须把自己当成上帝,上帝眼里世间存在的万物皆为对象,不存在的也可以创造出来。面向对象的程序设计好比如来设计西游记,如来要解决的问题是把经书传给东土大唐,如来想了想解决这个问题需要四个人:唐僧,沙和尚,猪八戒,孙悟空,每个人都有各自的特征和技能(这就是对象的概念,特征和技能分别对应对象的数据属性和方法属性),然而这并不好玩,于是如来又安排了一群妖魔鬼怪,为了防止师徒四人在取经路上被搞死,又安排了一群神仙保驾护航,这些都是对象。然后取经开始,师徒四人与妖魔鬼怪神仙交互着直到最后取得真经。如来根本不会管师徒四人按照什么流程去取),对象是特征与技能的结合体,基于面向对象设计程序就好比在创造一个世界,你就是这个世界的上帝,存在的皆为对象,不存在的也可以创造出来,与面向过程机械式的思维方式形成鲜明对比,面向对象更加注重对现实世界的模拟,是一种“上帝式”的思维方式。
面向对象编程的优点:
优点是:解决了程序的扩展性。对某一个对象单独修改,会立即反映到整个体系中,如对游戏中一个人物参数的特征和技能修改都很容易。
面向对象编程的缺点:
缺点:
1、编程的复杂度远高于面向过程,不了解面向对象而立即上手基于它设计程序,极容易出现过度设计的问题。一些扩展性要求低的场景使用面向对象会徒增编程的难度,比如管理Linux系统的shell脚本
就不适合面向对象去设计,面向过程反而更加适合。
2、无法面向过程的程序设计流水式的可以很精准的预测问题的处理流程与结果,面向对象的程序一旦开始就由对象之间的交互解决问题,即便是上帝也无法精准地预测最终结果。于是我们经常看到对战类
的游戏,新增一个游戏人物,在对战的过程中极容易出现阴霸的技能,一刀砍死3个人,这种情况是无法准确预知的,只有对象之间交互才能准确地直到最终的结果。
面向对象编程的应用场景:
应用场景:需求经常变化的软件,一般需求的变化都集中在用户层,互联网应用,企业内部软件,游戏等都是面向对象的程序设计大显身手的好地方。
python3面向对象技术简介
类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
方法:类中定义的函数。
类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
数据成员:类变量或者实例变量用于处理类及其实例对象的相关的数据。
方法重写:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
局部变量:定义在方法中的变量,只作用于当前实例的类。
实例变量:在类的声明中,属性是用变量来表示的,这种变量就称为实例变量,实例变量就是一个用 self 修饰的变量。
继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类,这是模拟"是一个(is-a)"关系(例图,Dog是一个Animal)。
实例化:创建一个类的实例,类的具体对象。
对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
闭包
在一个外函数中定义了一个内函数,内函数里运用了外函数的临时变量,并且外函数的返回值是内函数的引用。这样就构成了一个闭包。
一般情况下,在我们认知当中,如果一个函数结束,函数的内部所有东西都会释放掉,还给内存,局部变量都会消失。但是闭包是一种特殊情况,如果外函数在结束的时候发现有自己的临时变量将来会在内部函数中用到,就把这个临时变量绑定给了内部函数,然后自己再结束。
外函数返回了内函数的引用:
**引用是什么?**在python中一切都是对象,包括整型数据1,函数,其实是对象。
当我们进行a=1的时候,实际上在内存当中有一个地方存了值1,然后用a这个变量名存了1所在内存位置的引用。引用就好像c语言里的指针,大家可以把引用理解成地址。a只不过是一个变量名字,a里面存的是1这个数值所在的地址,就是a里面存了数值1的引用。
#闭包函数的实例
2 # outer是外部函数 a和b都是外函数的临时变量
3 def outer( a ):
4 b = 10
5 # inner是内函数
6 def inner():
7 #在内函数中 用到了外函数的临时变量
8 print(a+b)
9 # 外函数的返回值是内函数的引用
10 return inner
11
12 if __name__ == '__main__':
13 # 在这里我们调用外函数传入参数5
14 #此时外函数两个临时变量 a是5 b是10 ,并创建了内函数,然后把内函数的引用返回存给了demo
15 # 外函数结束的时候发现内部函数将会用到自己的临时变量,这两个临时变量就不会释放,会绑定给这个内部函数
16 demo = outer(5)
17 # 我们调用内部函数,看一看内部函数是不是能使用外部函数的临时变量
18 # demo存了外函数的返回值,也就是inner函数的引用,这里相当于执行inner函数
19 demo() # 15
20
21 demo2 = outer(7)
22 demo2()#17
函数式编程
函数式编程是种编程方式,它将电脑运算视为函数的计算。函数编程语言最重要的基础是λ演算(lambda calculus),而且λ演算的函数可以接受函数当作输入(参数)和输出(返回值)。 和指令式编程相比,函数式编程强调函数的计算比指令的执行重要。和过程化编程相比,函数式编程里函数的计算可随时调用。其特性主要有:
闭包和高阶函数
函数编程支持函数作为第一类对象,有时称为闭包或者仿函数(functor)对象。实质上,闭包是起函数的作用并可以像对象一样操作的对象。与此类似,FP 语言支持高阶函数。高阶函数可以用另一个函数(间接地,用一个表达式) 作为其输入参数,在某些情况下,它甚至返回一个函数作为其输出参数。这两种结构结合在一起使得可以用优雅的方式进行模块化编程,这是使用 FP 的最大好处。 [4]
惰性计算
除了高阶函数和仿函数(或闭包)的概念,FP 还引入了惰性计算的概念。在惰性计算中,表达式不是在绑定到变量时立即计算,而是在求值程序需要产生表达式的值时进行计算。延迟的计算使您可以编写可能潜在地生成无穷输出的函数。因为不会计算多于程序的其余部分所需要的值,所以不需要担心由无穷计算所导致的 out-of-memory 错误。一个惰性计算的例子是生成无穷 Fibonacci 列表的函数,但是对第n个Fibonacci 数的计算相当于只是从可能的无穷列表中提取一项。
递归
FP 还有一个特点是用递归做为控制流程的机制。例如,Lisp 处理的列表定义为在头元素后面有子列表,这种表示法使得它自己自然地对更小的子列表不断递归。
函数式编程具有五个鲜明的特点。
函数是"第一等公民"
所谓"第一等公民"(first class),指的是函数与其他数据类型一样,处于平等地位,可以赋值给其他变量,也可以作为参数,传入另一个函数,或者作为别的函数的返回值。
猴子补丁
猴子补丁是在一个函数或者对象已经存在的基础上,改变它的行为。在动态语言中,不去改变源码而对功能进行追加和变更。大多数时候这不是一个好主意 – 如果早就设计好,不是更好?一个可以使用猴子补丁的地方是做测试,著名的包mock,就是一个很好的例子。
鸭子类型
动态类型的一种风格。在这种风格中,一个对象有效的语义,不是由继承自特定的类或实现特定的接口,而是由"当前方法"方法 (计算机科学)")和属性的集合"决定。这个概念的名字来源于由James Whitcomb Riley提出的鸭子测试,“鸭子测试”可以这样表述:“当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。” 在鸭子类型中,关注点在于对象的行为,能作什么;而不是关注对象所属的类型。
*args, **kwargs
我们用 args 当我们不知道要有多少个参数传给函数,或者我们想把一个列表或者tuple存起来以后传给函数。
我们用**kwargs当我们不知道有多少个关键字参数要传给函数,或者我们想把字典存起来以后传给函数。
args 和 kwargs的名字是以前遗留下来的,你用bob 和**billy也没关系但是这样不太好,嘿嘿。有时我们需要传参数给函数,但是有时候我们希望把参数都存起来,以后传给函数,有时,这只是一个节省时间的方法。

def f(*args,**kwargs): print(args, kwargs)
l = [1,2,3]
t = (4,5,6)
d = {'a':7,'b':8,'c':9}
f()
f(1,2,3) # (1, 2, 3) {}
f(1,2,3,"groovy") # (1, 2, 3, 'groovy') {}
f(a=1,b=2,c=3) # () {'a': 1, 'c': 3, 'b': 2}
f(a=1,b=2,c=3,zzz="hi") # () {'a': 1, 'c': 3, 'b': 2, 'zzz': 'hi'}
f(1,2,3,a=1,b=2,c=3) # (1, 2, 3) {'a': 1, 'c': 3, 'b': 2}
f(*l,**d) # (1, 2, 3) {'a': 7, 'c': 9, 'b': 8}
f(*t,**d) # (4, 5, 6) {'a': 7, 'c': 9, 'b': 8}
f(1,2,*t) # (1, 2, 4, 5, 6) {}
f(q="winning",**d) # () {'a': 7, 'q': 'winning', 'c': 9, 'b': 8}
f(1,2,*t,q="winning",**d) # (1, 2, 4, 5, 6) {'a': 7, 'q': 'winning', 'c': 9, 'b': 8}
def f2(arg1,arg2,*args,**kwargs): print(arg1,arg2, args, kwargs)
f2(1,2,3) # 1 2 (3,) {}
f2(1,2,3,"groovy") # 1 2 (3, 'groovy') {}
f2(arg1=1,arg2=2,c=3) # 1 2 () {'c': 3}
f2(arg1=1,arg2=2,c=3,zzz="hi") # 1 2 () {'c': 3, 'zzz': 'hi'}
f2(1,2,3,a=1,b=2,c=3) # 1 2 (3,) {'a': 1, 'c': 3, 'b': 2}
f2(*l,**d) # 1 2 (3,) {'a': 7, 'c': 9, 'b': 8}
f2(*t,**d) # 4 5 (6,) {'a': 7, 'c': 9, 'b': 8}
f2(1,2,*t) # 1 2 (4, 5, 6) {}
f2(1,1,q="winning",**d) # 1 1 () {'a': 7, 'q': 'winning', 'c': 9, 'b': 8}
f2(1,2,*t,q="winning",**d) # 1 2 (4, 5, 6) {'a': 7, 'q': 'winning', 'c': 9, 'b': 8}
装饰器
@classmethod, @staticmethod, @property
@my_decorator
def my_func(stuff):
do_things
以上代码相当于:
def my_func(stuff):
do_things
my_func = my_decorator(my_func)
import time
2 def showtime(func):
3 def wrapper(a, b):
4 start_time = time.time()
5 func(a,b)
6 end_time = time.time()
7 print('spend is {}'.format(end_time - start_time))
8
9 return wrapper
10
11 @showtime #add = showtime(add)
12 def add(a, b):
13 print(a+b)
14 time.sleep(1)
15
16 @showtime #sub = showtime(sub)
17 def sub(a,b):
18 print(a-b)
19 time.sleep(1)
20
21 add(5,4)
22 sub(3,2)
垃圾回收机制
Python在内存中维护对象的引用次数。如果一个对象的引用次数变为0,垃圾回收机制会回收这个对象作为他用。
有时候会有“引用循环”的事情发生。垃圾回收器定期检查回收内存。一个例子是,如果你有两个对象 o1 和 o2,并且o1.x == o2 and o2.x == o1. 如果 o1 和 o2 都没有被其他对象使用,那么它们都不应该存在。但是它们的应用次数都是1,垃圾回收不会起作用。
一些启发算法可以用来加速垃圾回收。比如,最近创建的对象更可能是无用的。用创建时间来度量对象的生命时长,生命越长,越可能是更有用的对象。
CPython的说明文档中有相关解释。
内存管理机制
一、对象的引用计数机制
Python内部使用引用计数,来保持追踪内存中的对象,所有对象都有引用计数。
引用计数增加的情况:
1,一个对象分配一个新名称
2,将其放入一个容器中(如列表、元组或字典)
引用计数减少的情况:
1,使用del语句对对象别名显示的销毁
2,引用超出作用域或被重新赋值
sys.getrefcount( )函数可以获得对象的当前引用计数
多数情况下,引用计数比你猜测得要大得多。对于不可变数据(如数字和字符串),解释器会在程序的不同部分共享内存,以便节约内存。
二、垃圾回收
1,当一个对象的引用计数归零时,它将被垃圾收集机制处理掉。
2,当两个对象a和b相互引用时,del语句可以减少a和b的引用计数,并销毁用于引用底层对象的名称。然而由于每个对象都包含一个对其他对象的应用,因此引用计数不会归零,对象也不会销毁。(从而导致内存泄露)。为解决这一问题,解释器会定期执行一个循环检测器,搜索不可访问对象的循环并删除它们。
三、内存池机制
Python提供了对内存的垃圾收集机制,但是它将不用的内存放到内存池而不是返回给操作系统。
1,Pymalloc机制。为了加速Python的执行效率,Python引入了一个内存池机制,用于管理对小块内存的申请和释放。
2,Python中所有小于256个字节的对象都使用pymalloc实现的分配器,而大的对象则使用系统的malloc。
3,对于Python对象,如整数,浮点数和List,都有其独立的私有内存池,对象间不共享他们的内存池。也就是说如果你分配又释放了大量的整数,用于缓存这些整数的内存就不能再分配给浮点数。
迭代对象、迭代器、生成器
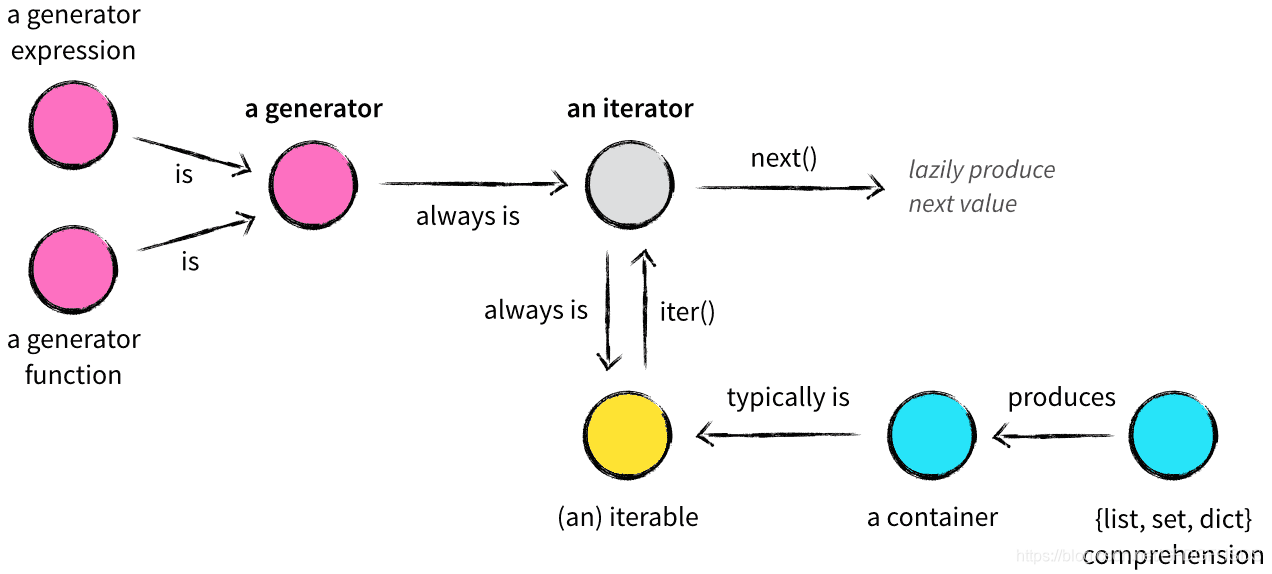
容器(container)
容器是一种把多个元素组织在一起的数据结构,容器中的元素可以逐个地迭代获取,可以用 in , not in 关键字判断元素是否包含在容器中。通常这类数据结构把所有的元素存储在内存中(也有一些特列并不是所有的元素都放在内存)在Python中,常见的容器对象有:
'''
list, deque, ....
set, frozensets, ....
dict, defaultdict, OrderedDict, Counter, ....
tuple, namedtuple, …
str
'''
容器比较容易理解,因为你就可以把它看作是一个盒子、一栋房子、一个柜子,里面可以塞任何东西。从技术角度来说,当它可以用来询问某个元素是否包含在其中时,那么这个对象就可以认为是一个容器,比如 list,set,tuples都是容器对象:
>>> assert 1 in [1, 2, 3] # lists
>>> assert 4 not in [1, 2, 3]
>>> assert 1 in {1, 2, 3} # sets
>>> assert 4 not in {1, 2, 3}
>>> assert 1 in (1, 2, 3) # tuples
>>> assert 4 not in (1, 2, 3)
询问某元素是否在dict中用dict的中key:
>>> d = {1: 'foo', 2: 'bar', 3: 'qux'}
>>> assert 1 in d
>>> assert 'foo' not in d # 'foo' 不是dict中的元素
询问某substring是否在string中:
>>> s = 'foobar'
>>> assert 'b' in s
>>> assert 'x' not in s
>>> assert 'foo' in s
尽管绝大多数容器都提供了某种方式来获取其中的每一个元素,但这并不是容器本身提供的能力,而是 可迭代对象 赋予了容器这种能力,当然并不是所有的容器都是可迭代的,比如: Bloom filter ,虽然Bloom filter可以用来检测某个元素是否包含在容器中,但是并不能从容器中获取其中的每一个值,因为Bloom filter压根就没把元素存储在容器中,而是通过一个散列函数映射成一个值保存在数组中。
可迭代对象(iterable)
刚才说过,很多容器都是可迭代对象,此外还有更多的对象同样也是可迭代对象,比如处于打开状态的files,sockets等等。但凡是可以返回一个 迭代器 的对象都可称之为可迭代对象,听起来可能有点困惑,没关系,可迭代对象与迭代器有一个非常重要的区别。先看一个例子:
>>> x = [1, 2, 3]
>>> y = iter(x)
>>> z = iter(x)
>>> next(y)
1
>>> next(y)
2
>>> next(z)
1
>>> type(x)
<class 'list'>
>>> type(y)
<class 'list_iterator'>
这里 x 是一个可迭代对象,可迭代对象和容器一样是一种通俗的叫法,并不是指某种具体的数据类型,list是可迭代对象,dict是可迭代对象,set也是可迭代对象。 y 和 z 是两个独立的迭代器,迭代器内部持有一个状态,该状态用于记录当前迭代所在的位置,以方便下次迭代的时候获取正确的元素。迭代器有一种具体的迭代器类型,比如 list_iterator , set_iterator 。可迭代对象实现了 iter 和 next 方法(python2中是 next 方法,python3是 next 方法),这两个方法对应内置函数 iter() 和 next() 。 iter 方法返回可迭代对象本身,这使得他既是一个可迭代对象同时也是一个迭代器。
当运行代码:
x = [1, 2, 3]
for elem in x:
...
实际执行情况是:
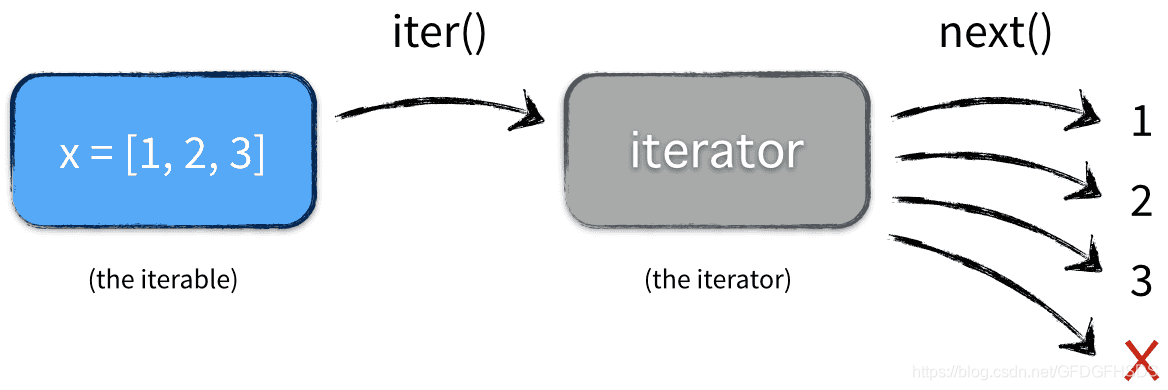
反编译该段代码,你可以看到解释器显示地调用 GET_ITER 指令,相当于调用 iter(x) , FOR_ITER 指令就是调用 next() 方法,不断地获取迭代器中的下一个元素,但是你没法直接从指令中看出来,因为他被解释器优化过了。
>>> import dis
>>> x = [1, 2, 3]
>>> dis.dis('for _ in x: pass')
1 0 SETUP_LOOP 14 (to 17)
3 LOAD_NAME 0 (x)
6 GET_ITER
>> 7 FOR_ITER 6 (to 16)
10 STORE_NAME 1 (_)
13 JUMP_ABSOLUTE 7
>> 16 POP_BLOCK
>> 17 LOAD_CONST 0 (None)
20 RETURN_VALUE
迭代器(iterator)
那么什么迭代器呢?它是一个带状态的对象,他能在你调用 next() 方法的时候返回容器中的下一个值,任何实现了 next() (python2中实现 next() )方法的对象都是迭代器,至于它是如何实现的这并不重要。
所以,迭代器就是实现了工厂模式的对象,它在你每次你询问要下一个值的时候给你返回。有很多关于迭代器的例子,比如 itertools 函数返回的都是迭代器对象。迭代器是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
迭代器有两个基本的方法:iter() 和 next()。
字符串,列表或元组对象都可用于创建迭代器:
生成无限序列:
>>> from itertools import count
>>> counter = count(start=13)
>>> next(counter)
13
>>> next(counter)
14
从一个有限序列中生成无限序列:
>>> from itertools import cycle
>>> colors = cycle(['red', 'white', 'blue'])
>>> next(colors)
'red'
>>> next(colors)
'white'
>>> next(colors)
'blue'
>>> next(colors)
'red'
从无限的序列中生成有限序列:
>>> from itertools import islice
>>> colors = cycle(['red', 'white', 'blue']) # infinite
>>> limited = islice(colors, 0, 4) # finite
>>> for x in limited:
... print(x)
red
white
blue
red
为了更直观地感受迭代器内部的执行过程,我们自定义一个迭代器,以斐波那契数列为例:
class Fib:
def __init__(self):
self.prev = 0
self.curr = 1
def __iter__(self):
return self
def __next__(self):
value = self.curr
self.curr += self.prev
self.prev = value
return value
>>> f = Fib()
>>> list(islice(f, 0, 10))
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
Fib既是一个可迭代对象(因为它实现了 iter 方法),又是一个迭代器(因为实现了 next 方法)。实例变量 prev 和 curr 用户维护迭代器内部的状态。每次调用 next() 方法的时候做两件事:
为下一次调用 next() 方法修改状态
为当前这次调用生成返回结果
迭代器就像一个懒加载的工厂,等到有人需要的时候才给它生成值返回,没调用的时候就处于休眠状态等待下一次调用。
生成器(generator)
生成器算得上是Python语言中最吸引人的特性之一,生成器其实是一种特殊的迭代器,不过这种迭代器更加优雅。它不需要再像上面的类一样写 iter() 和 next() 方法了,只需要一个 yiled 关键字。 生成器有如下特征是它一定也是迭代器(反之不成立),因此任何生成器也是以一种懒加载的模式生成值。
在 Python 中,使用了 yield 的函数被称为生成器(generator)。
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。
调用一个生成器函数,返回的是一个迭代器对象。用生成器来实现斐波那契数列的例子是:
def fib():
prev, curr = 0, 1
while True:
yield curr
prev, curr = curr, curr + prev
>>> f = fib()
>>> list(islice(f, 0, 10))
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
fib 就是一个普通的python函数,它特需的地方在于函数体中没有 return 关键字,函数的返回值是一个生成器对象。当执行 f=fib() 返回的是一个生成器对象,此时函数体中的代码并不会执行,只有显示或隐示地调用next的时候才会真正执行里面的代码。
生成器在Python中是一个非常强大的编程结构,可以用更少地中间变量些流式代码,此外,相比其它容器对象它更能节省内存和CPU,当然它可以用更少的代码来实现相似的功能。现在就可以动手重构你的代码了,但凡看到类似:
def something():
result = []
for ... in ...:
result.append(x)
return result
都可以用生成器函数来替换:
def iter_something():
for ... in ...:
yield x
标准数据类型
Python3 中有六个标准的数据类型:
Number(数字): int、float、bool、complex(复数)。
String(字符串)
List(列表)
Tuple(元组)
Set(集合)
Dictionary(字典)
Python3 的六个标准数据类型中:
不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
运算符
算术运算符、比较(关系)运算符、赋值运算符、逻辑运算符、位运算符、成员运算符、身份运算符
重点介绍位运算符
a = 0011 1100
b = 0000 1101
-----------------
a&b = 0000 1100
a|b = 0011 1101
a^b = 0011 0001
~a = 1100 0011

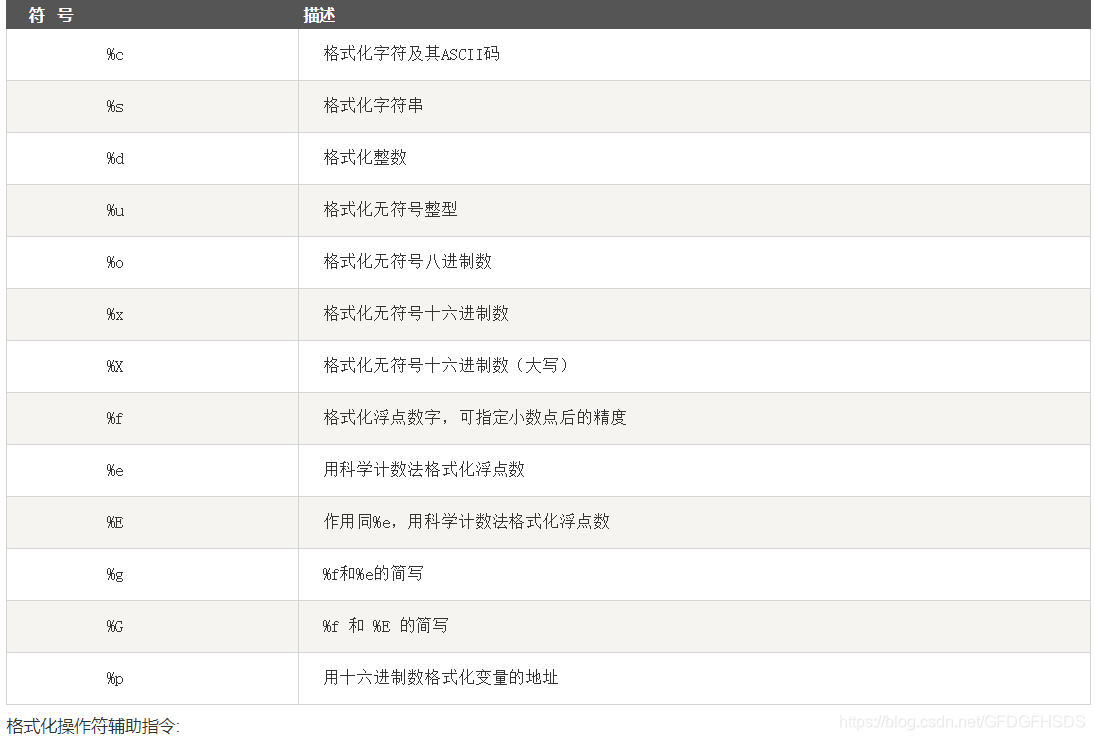
字符串格式化
列表内置函数

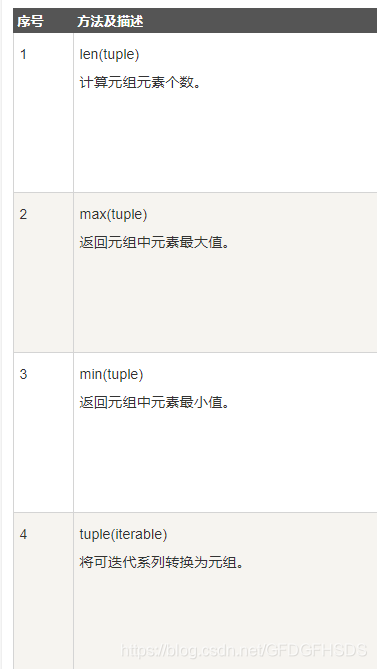
元组内置函数
数据结构
将列表当做堆栈使用
>>> stack = [3, 4, 5]
>>> stack.append(6)
>>> stack.append(7)
>>> stack
[3, 4, 5, 6, 7]
>>> stack.pop()
7
>>> stack
[3, 4, 5, 6]
>>> stack.pop()
6
>>> stack.pop()
5
>>> stack
[3, 4]
将列表当作队列使用
>>> from collections import deque
>>> queue = deque(["Eric", "John", "Michael"])
>>> queue.append("Terry") # Terry arrives
>>> queue.append("Graham") # Graham arrives
>>> queue.popleft() # The first to arrive now leaves
'Eric'
>>> queue.popleft() # The second to arrive now leaves
'John'
>>> queue # Remaining queue in order of arrival
deque(['Michael', 'Terry', 'Graham'])
__name__属性
一个模块被另一个程序第一次引入时,其主程序将运行。如果我们想在模块被引入时,模块中的某一程序块不执行,我们可以用__name__属性来使该程序块仅在该模块自身运行时执行。
#!/usr/bin/python3
# Filename: using_name.py
if __name__ == '__main__':
print('程序自身在运行')
else:
print('我来自另一模块')
$ python using_name.py
程序自身在运行
$ python
>>> import using_name
我来自另一模块
>>>
说明: 每个模块都有一个__name__属性,当其值是’main’时,表明该模块自身在运行,否则是被引入。
说明:name 与 main 底下是双下划线, _ _ 是这样去掉中间的那个空格。
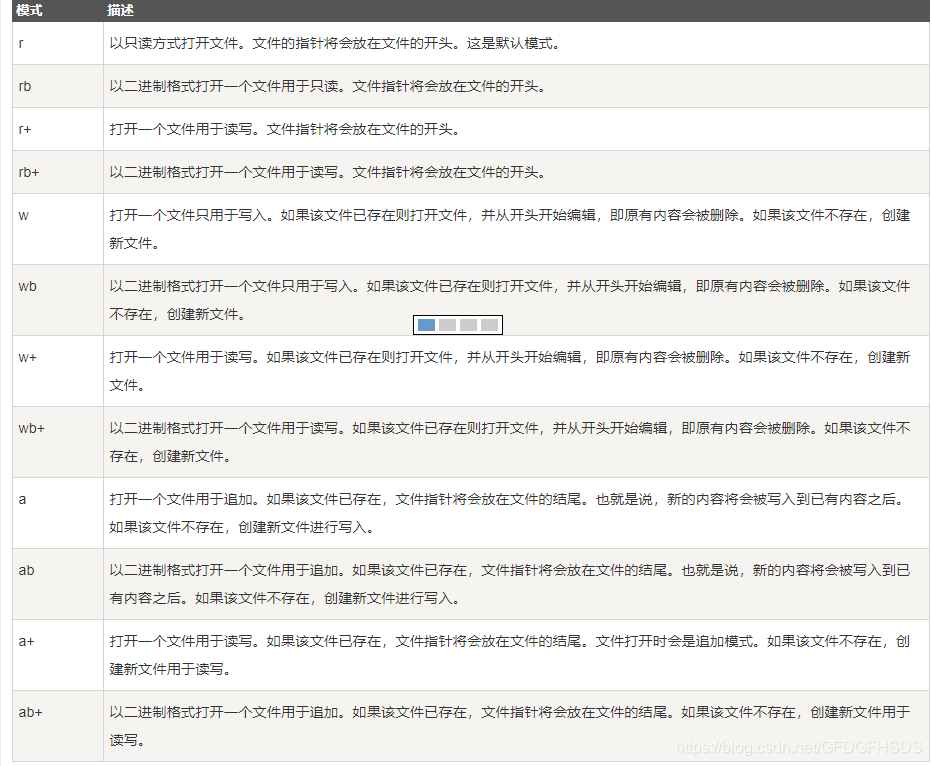
读写文件
标准异常类汇总
ArithmeticError 所有数值计算错误的基类
AssertionError 断言语句失败
AttributeError 对象没有这个属性
BaseException 所有异常的基类
DeprecationWarning 关于被弃用的特征的警告
EnvironmentError 操作系统错误的基类
EOFError 没有内建输入,到达EOF 标记
Exception 常规错误的基类
FloatingPointError 浮点计算错误
FutureWarning 关于构造将来语义会有改变的警告
GeneratorExit 生成器(generator)发生异常来通知退出
ImportError 导入模块/对象失败
IndentationError 缩进错误
IndexError 序列中没有没有此索引(index)
IOError 输入/输出操作失败
KeyboardInterrupt 用户中断执行(通常是输入^C)
KeyboardInterrupt 用户中断执行(通常是输入^C)
KeyError 映射中没有这个键
LookupError 无效数据查询的基类
MemoryError 内存溢出错误(对于Python 解释器不是致命的)
NameError 未声明/初始化对象 (没有属性)
NotImplementedError 尚未实现的方法
OSError 操作系统错误
OverflowError 数值运算超出最大限制
OverflowWarning 旧的关于自动提升为长整型(long)的警告
PendingDeprecationWarning 关于特性将会被废弃的警告
ReferenceError 弱引用(Weak reference)试图访问已经垃圾回收了的对象
RuntimeError 一般的运行时错误
RuntimeWarning 可疑的运行时行为(runtime behavior)的警告
StandardError 所有的内建标准异常的基类
StopIteration 迭代器没有更多的值
SyntaxError Python 语法错误
SyntaxWarning 可疑的语法的警告
SystemError 一般的解释器系统错误
SystemExit 解释器请求退出
SystemExit Python 解释器请求退出
TabError Tab 和空格混用
TypeError 对类型无效的操作
UnboundLocalError 访问未初始化的本地变量
UnicodeDecodeError Unicode 解码时的错误
UnicodeEncodeError Unicode 编码时错误
UnicodeError Unicode 相关的错误
UnicodeTranslateError Unicode 转换时错误
UserWarning 用户代码生成的警告
ValueError 传入无效的参数
Warning 警告的基类
WindowsError 系统调用失败
ZeroDivisionError 除(或取模)零 (所有数据类型)
