配合随堂笔记一起查看,不懂重新来过。
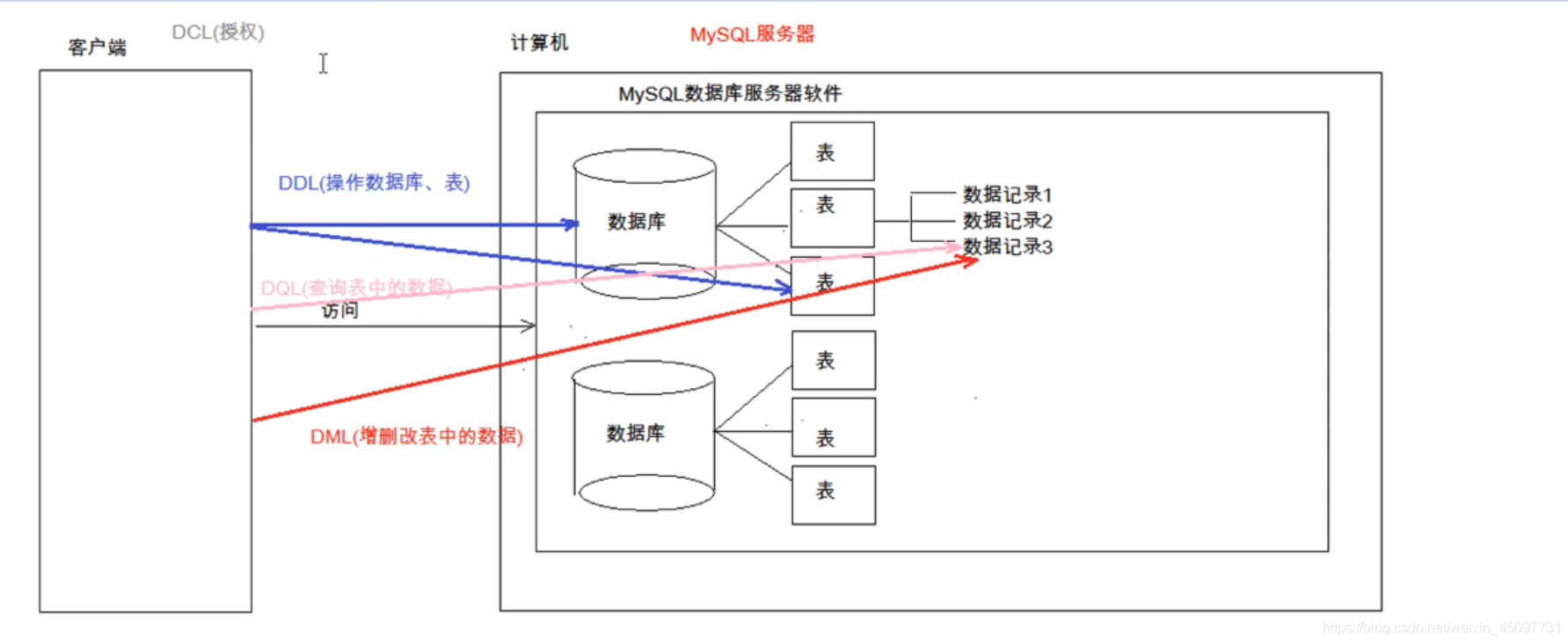
数据类型中:
varchar和char区别
varchar长度是可变地,char是固定的。比如,varchar(10)的value是"abc",那么varchar长度是3;char(10)的value是“abc”,那么长度还是10。
英文是占有1个字节;中文是2个字节。
1- truncasr table :先删除表,再创建个空表
2-select from 表明 order by 列名1 asc ,列名2 asc:
先执行最第一个排序命令,如果前面的属性有一样的时候,再执行第二个
3-count*主要有一行不是为空,都算null
count count(ifnull 列名,0)把那个列名为null值改为0
用count计算非空列(主建)
4-分组的查询语句中,只能出现被分组的字段(列名)和聚合函数
5-where和having区别。前者是对分组前进行筛选,满足才参与分组;后者是对分组后的结果进行筛选。
where后面不能跟聚合函数判断,having可以。
而且having可以使用查询聚合函数命令的别名来简化代码。
select sex,count(id),avg(math) 人数 from student where math >70 group by sex having 人数>=2
6-limit 从哪开始显示,每页显条数 --第1页
其中,"从哪开始显示"=(当时页数-1)×每页显示条数
7-对于非空约束,一般分2种方式来添加:
one.创建表的时候,加非空约束
two.创建完表再用alter修改约束
8-唯一约束不能使用alter modify来删除(添加可以),要使用alter …drop index 列名
9-主键=非空+唯一。删除主键:alter table 表名 drop primary key
自动增长
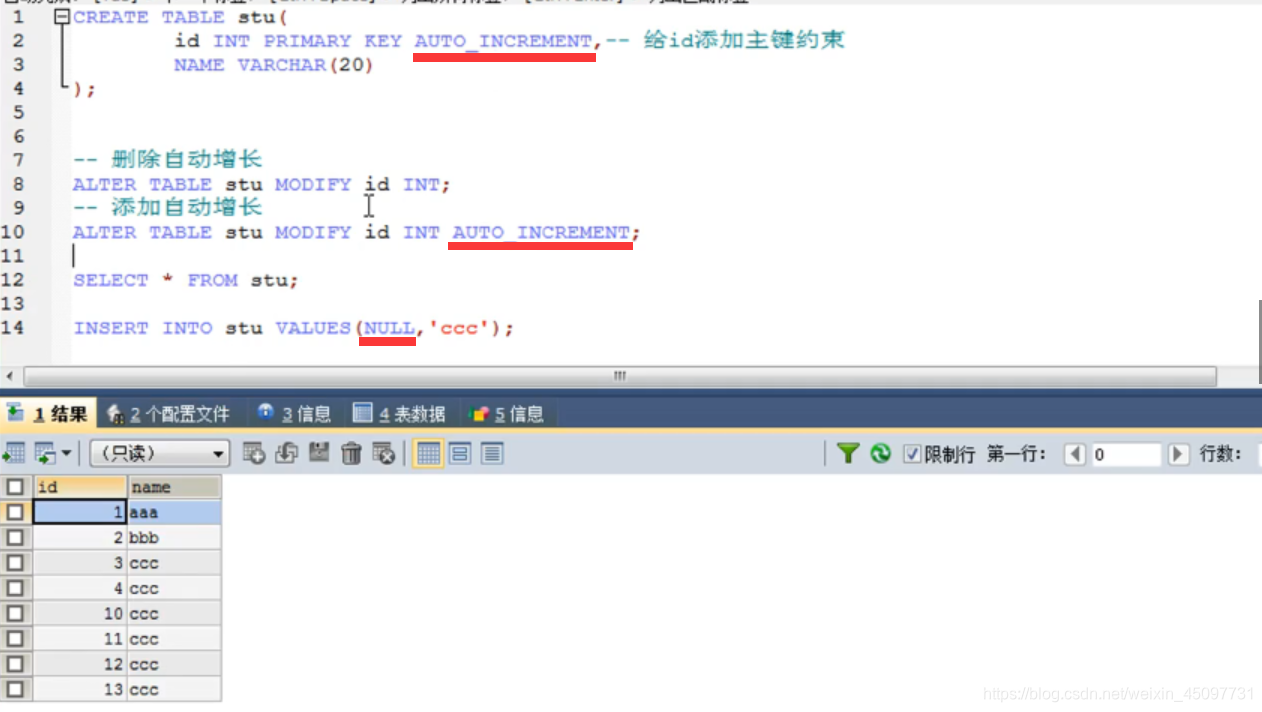
自动增长是什么?
答:如果某一列是数值类型的,使用auto_increment 可以来完成值得自动增长
注意:当设置了自动增长,我insert inito value时是可以设置null的,但是设置null不是null,而是根据表的列中最后一位进行自动增长。
为什么用自动增长?
答:一般id是连续的数值,如果没有设置,自己要一个一个地加,那是不是很麻烦?
外键


“主表名称”一般为主键。
(外键)级联操作:
什么是级联?
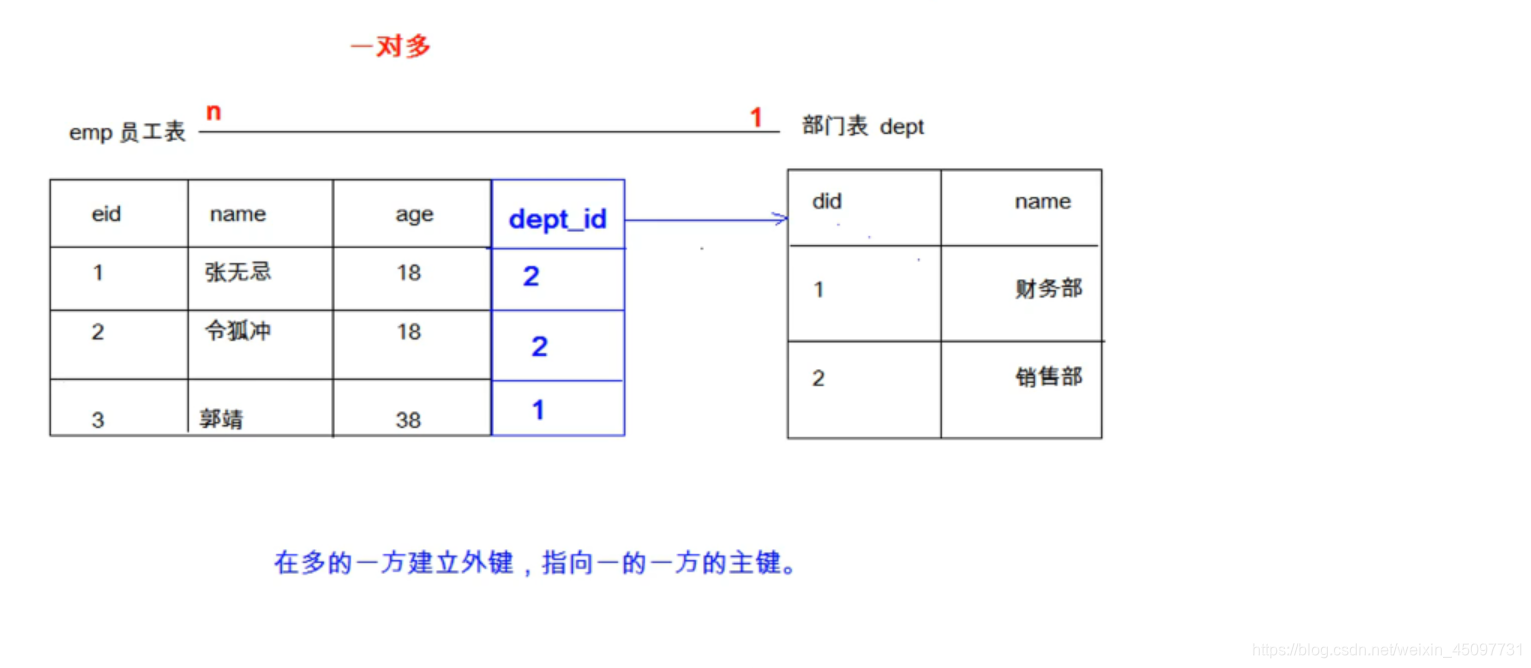
用来设计“一对多”关系。多要关联一,一什么它们就是什么。
为什么要设置关联?
比如:有1张员工表(姓名、年龄、部门),另一张表部门表(部门ID)
如果员工表没有设置级联操作,那么它设置“部门”的时候,要一个一个打自己打。那表中数据多了,是不是很蛋疼?所以,当我设置了级联操作之后,“员工表”中的“部门”关联了“部门表中“的”部门ID”,”员工表“中的”部门“就自动填补了关联的数据。
如图,不使用级联的情况。先把dep_id设置为空(它 是表中外键,里面的值除非是关联表中的主键值or NULL,其他值不行。)

怎么设置联动操作?
在设置外键的时候设置,如图

级联更新
当设置了级联更新的时候,如果主键的值修改了,那么外键的值也对应修改。
级联删除 —【谨慎】
当设置了级联删除,如果主键的值删除了,那么对应的外键的信息全部删除。
多表关系

一对多
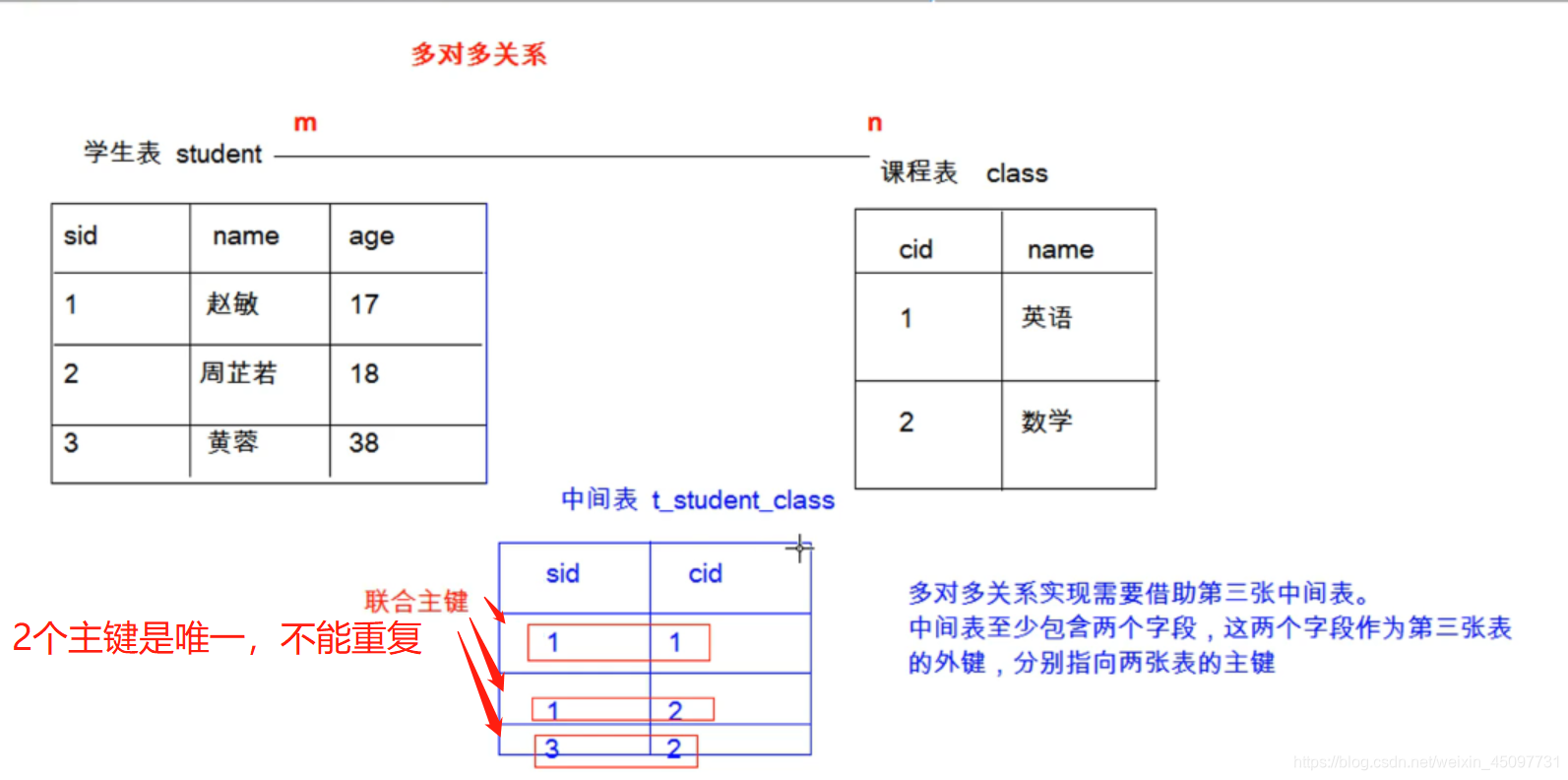
多对多
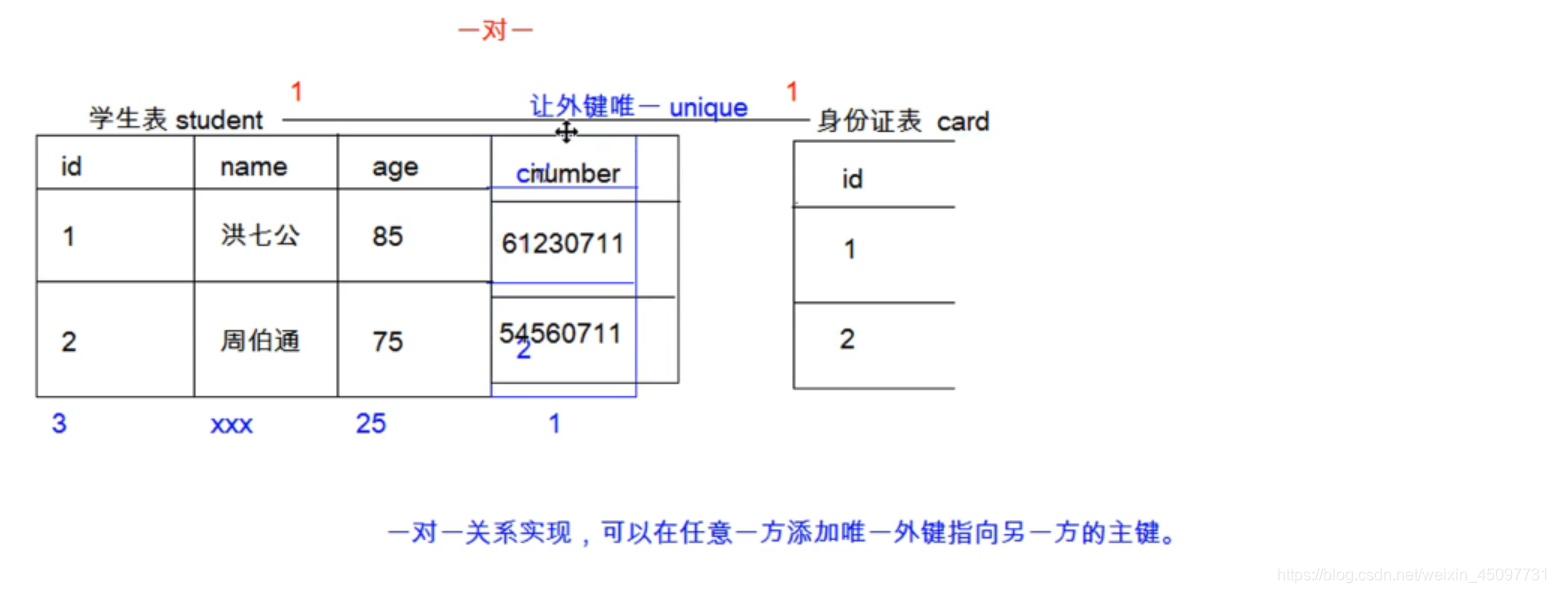
一对一

一对一关系的表很少很少这样,如果有我们为什么不把它拼在一起。
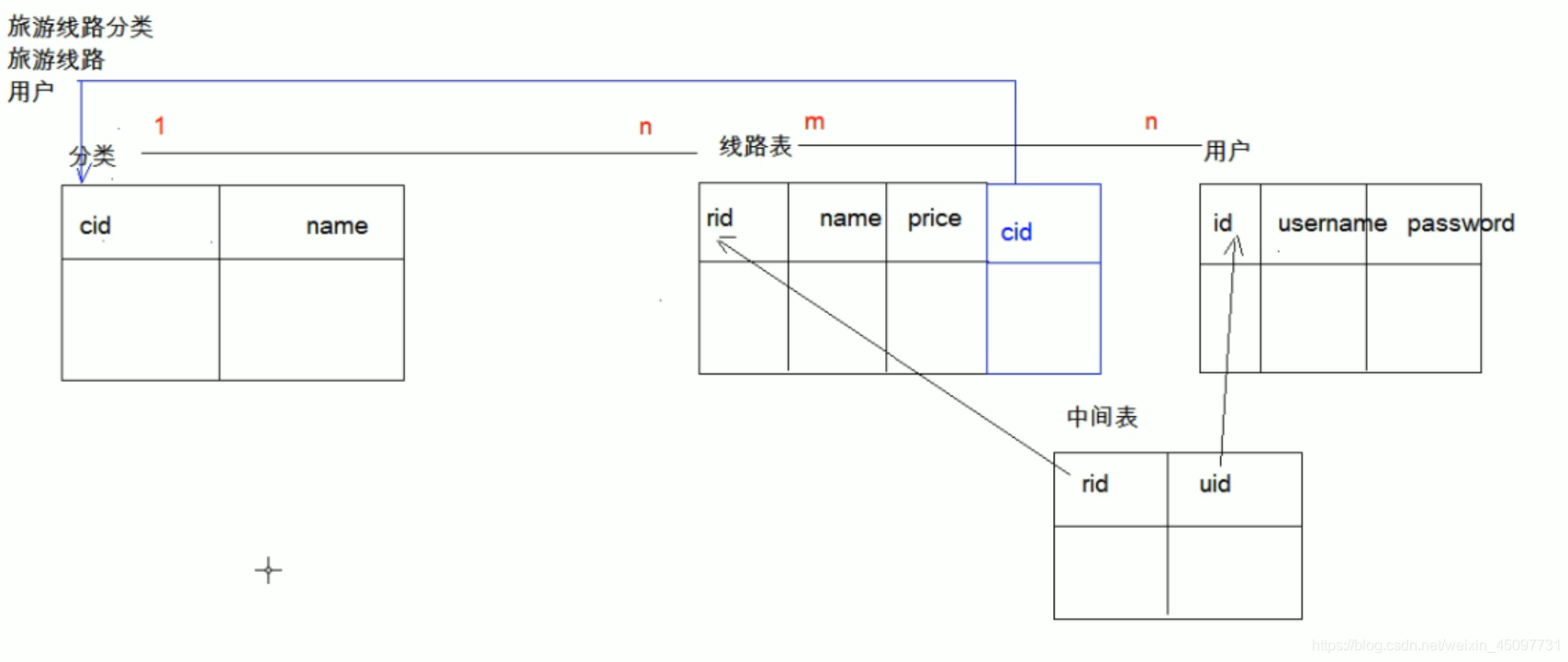
案列
主要是:
- 知道【实体】就是一个表
- 找到表与表之间的关系(一对一,一对多,多对多)
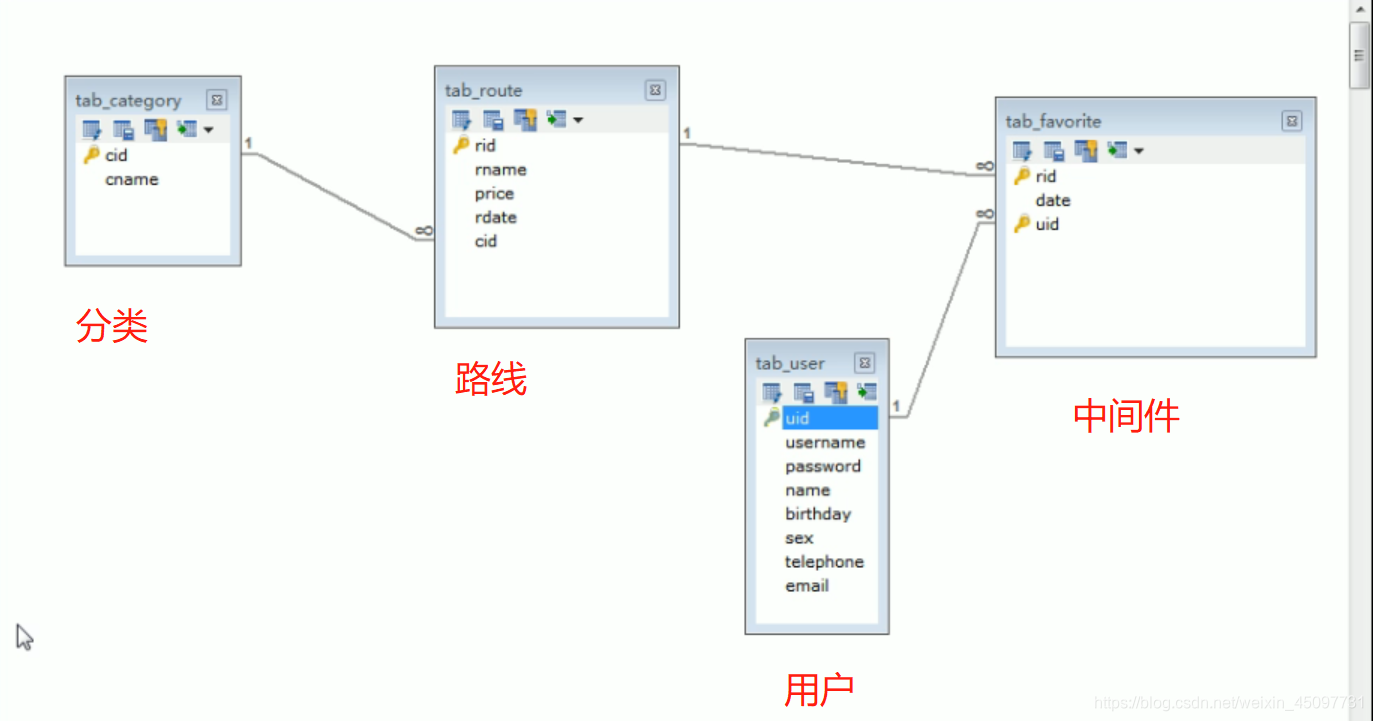
中间件的联合主键

三大范式

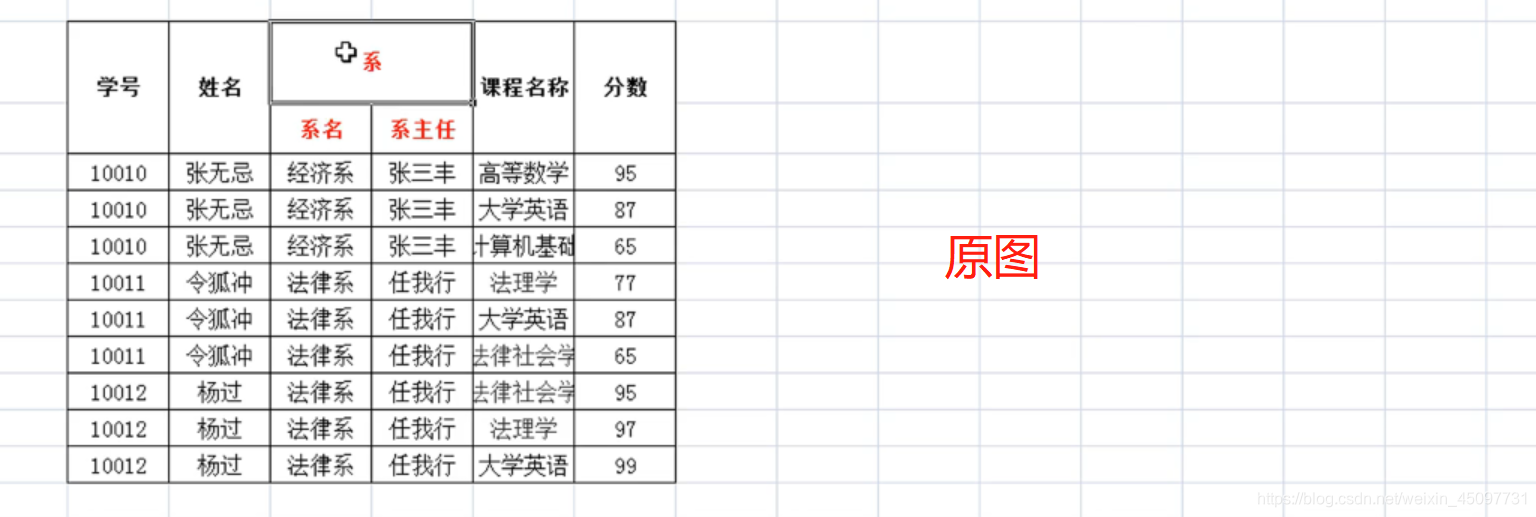
第一范式:要求每一组数据要有独立的列名。(原子:不可分割)
第二范式:在第一范式的基础上消除非主属性对码的部分依赖。
第三范式:在第二范式的基础上小出传递依赖。
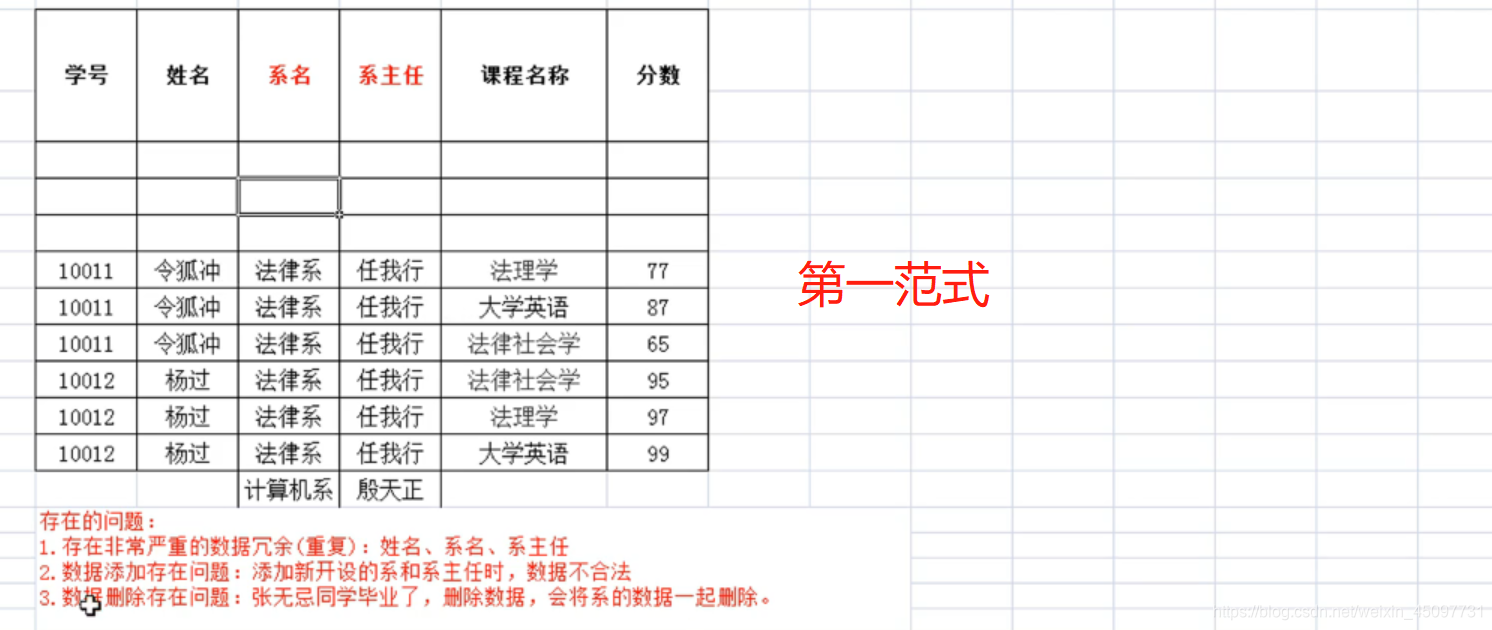
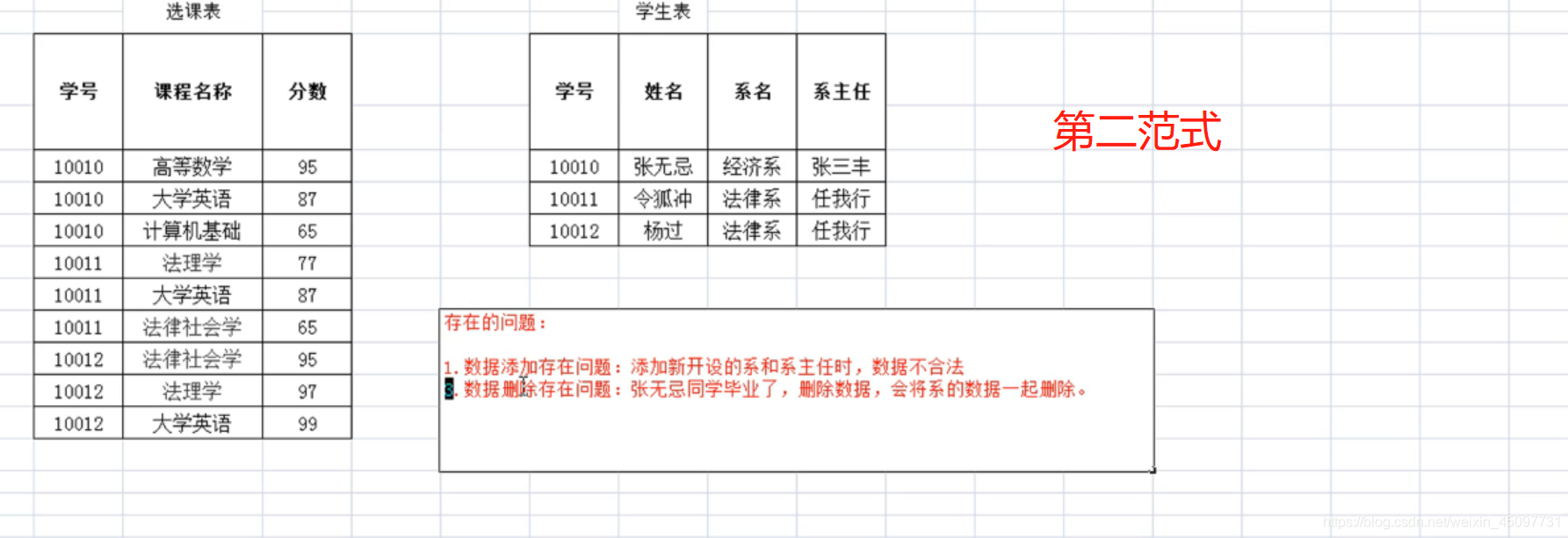
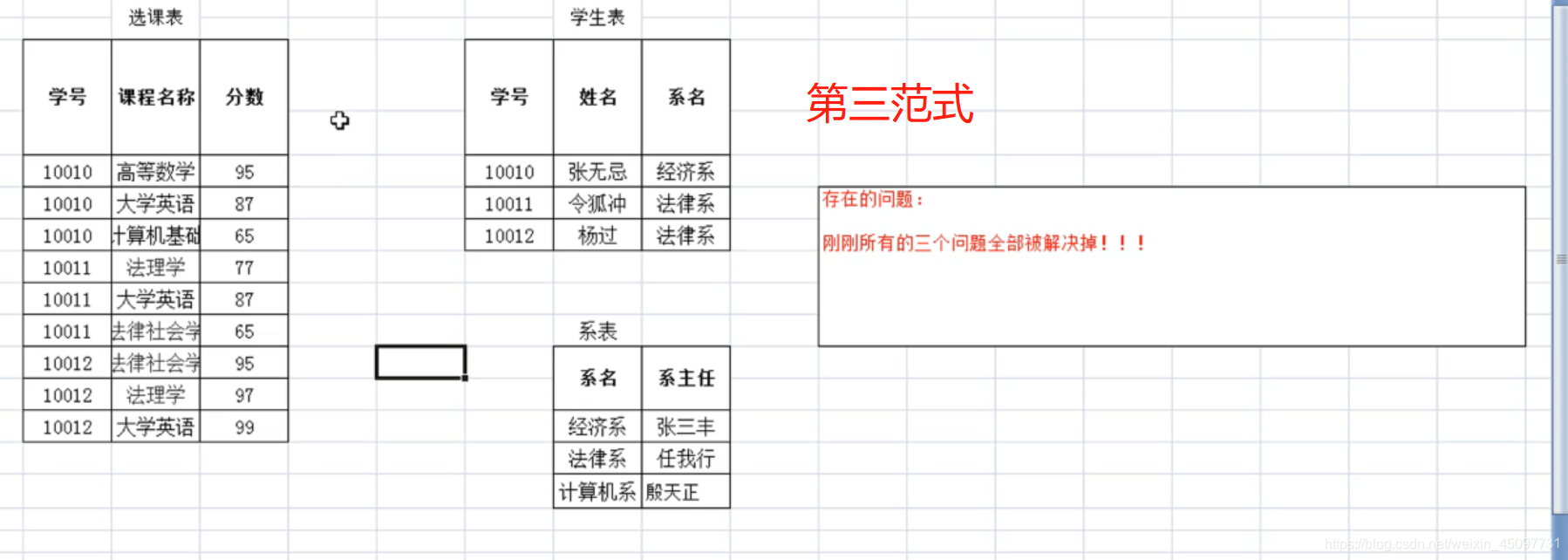
数据库备份与恢复

多表查询
笛卡儿积
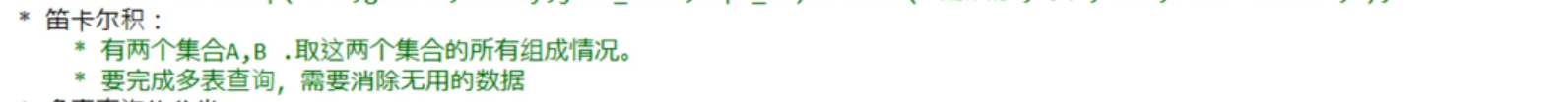
A与B的笛卡儿积的表列数=A表列书*B表列数
使用笛卡儿积,会存在无用的数据,所以下面要进行消除无用的数据。
内连接
- 隐式内连接:
语句:
select * from 表1,表2 where 表1.字段 = 表2.字段
常用格式:
select
别名.列名表, ----注释这是什么东东
from 表1 as 别名 ,表2 as 别名
where
别名1.字段 = 别名2.字段
- 显示内连接:
select 字段名 from 表1 [inner] join 表2 on 表1.字段 = 表2.字段
- 注意:
1、从哪2个表中查询
2、连接条件式是什么?(等值连接)
3、查询哪些字段?(一般不会全部列属性都查询)

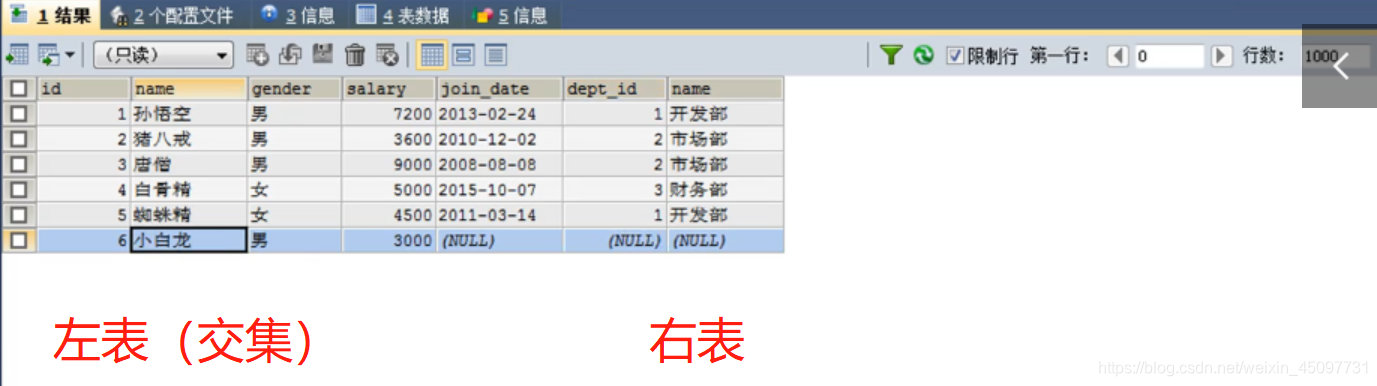
左外连接
查询的是左表已存在数据和右边合并的数据(左表数据全部保留),如果右表没有匹配的数据就显示null或者直接忽视掉。(左表向右表寻找匹配并且合并,如果没有匹配到就显示空值)
有外连接
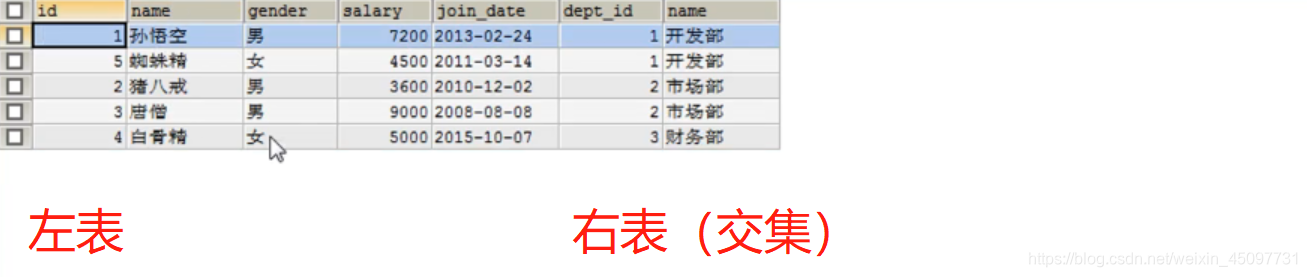
查询的是右表已存在数据和左边合并的数据(右表数据全部保留),如果右表没有匹配的数据就显示null或者直接忽视掉。(左表向右表寻找匹配并且合并,如果没有匹配到就显示空值)
子查询
子查询概述

使用子查询的几种情况
所谓的子查询结果,就是使用select后查询的表是单行单列,还是咋地。
- 子查询的结果是单行单列:
子查询可以作为条件,使用运算符去判断。(>,<,<=,<>…)

- 子查询的结果是多行单列
子查询可以作为条件,使用运算符in来判断

4. 子查询的结果是多行多列
子查询可以作为一张虚拟表参与查询

多表查询的注意事项:
- 先找需要查询的字段是在哪些表中,多个表用内连接
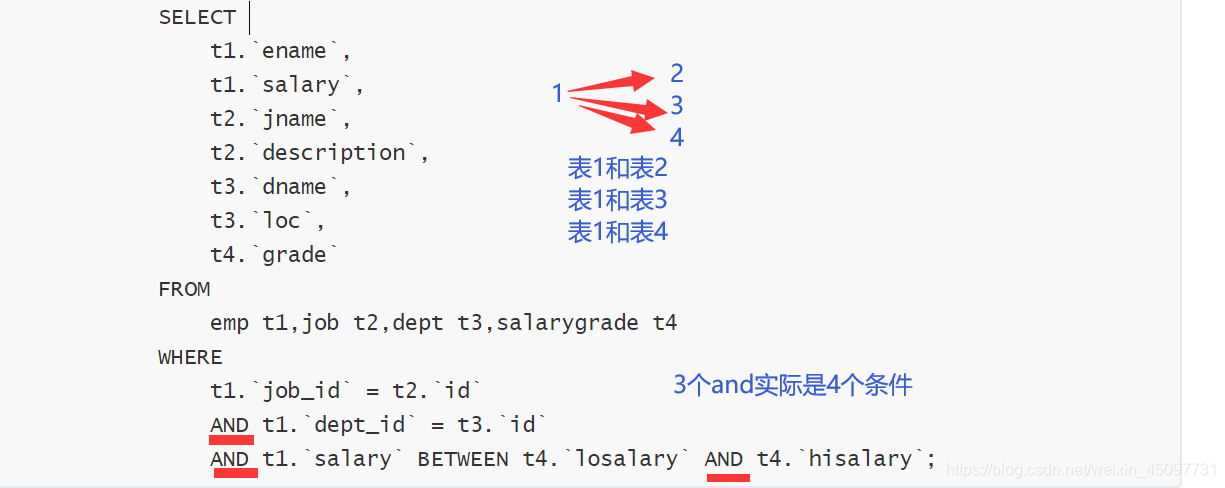
2.查询员工编号,员工姓名,工资,职务名称,职务描述,部门名称,部门位置
分析:
1. 员工编号,员工姓名,工资 emp 职务名称,职务描述 job 部门名称,部门位置 dept
2. 条件: emp.job_id = job.id and emp.dept_id = dept.id
*/
SELECT
t1.`id`, -- 员工编号
t1.`ename`, -- 员工姓名
t1.`salary`,-- 工资
t2.`jname`, -- 职务名称
t2.`description`, -- 职务描述
t3.`dname`, -- 部门名称
t3.`loc` -- 部门位置
FROM
emp t1, job t2,dept t3
WHERE
t1.`job_id` = t2.`id` AND t1.`dept_id` = t3.`id`;
多表查询练习
2个没有关联的表
当2个表没有关联的时候(主键与外键连接),条件不能够是等值连接
-- 3.查询员工姓名,工资,工资等级
分析:
1.员工姓名,工资 emp 工资等级 salarygrade
2.条件 emp.salary >= salarygrade.losalary and emp.salary <= salarygrade.hisalary
【emp.salary的值在salarygrade.losalary之间】
4个表查询
-- 4.查询员工姓名,工资,职务名称,职务描述,部门名称,部门位置,工资等级
分析:
1. 员工姓名,工资 emp , 职务名称,职务描述 job 部门名称,部门位置,dept 工资等级 salarygrade
2. 条件: emp.job_id = job.id and emp.dept_id = dept.id and emp.salary BETWEEN salarygrade.losalary and salarygrade.hisalary
【4个表4个条件】
-------------------------------------------------------------
子查询(虚拟表)+分组
-- 5.查询出部门编号、部门名称、部门位置、部门人数
分析:
1.部门编号、部门名称、部门位置 dept 表。 部门人数 emp表
2.使用分组查询。按照emp.dept_id完成分组,查询count(id)
3.使用子查询将第2步的查询结果和dept表进行关联查询
*/
SELECT
t1.`id`,t1.`dname`,t1.`loc` , t2.total
FROM
dept t1,(SELECT dept_id,COUNT(id) total FROM emp GROUP BY dept_id) t2
WHERE t1.`id` = t2.dept_id;
表的自关联映射关系
把一个表使用不同别名当成2个表。
-- 6.查询所有员工的姓名及其直接上级的姓名,没有领导的员工也需要查询
分析:
1.姓名 emp, 直接上级的姓名 emp
* emp表的id 和 mgr 是自关联
2.条件 emp.id = emp.mgr
3.查询左表的所有数据,和 交集数据
* 使用左外连接查询
*/
/*
select
t1.ename,
t1.mgr,
t2.`id`,
t2.ename
from emp t1, emp t2
where t1.mgr = t2.`id`;
*/
SELECT
t1.ename,
t1.mgr,
t2.`id`,
t2.`ename`
FROM emp t1
LEFT JOIN emp t2
ON t1.`mgr` = t2.`id`;
新理解:左外连接就是,左边表的部份要保持完整。
事务管理
- 事务的基本介绍
-
概念:
- 如果一个包含多个步骤的业务操作,被事务管理,那么这些操作要么同时成功,要么同时失败。
-
操作:
- 开启事务: start transaction; 【转账之前】
- 回滚:rollback; 【出现了问题之后,重新恢复到“开启事务”之前】
- 提交:commit; 【没有出现异常,那么就把事务管理后的数据上交】
-
案列简介:
张三给李四转账:
- 张三账户扣500
- 李四账户加三百
如果在张三李四的转账之间出现错误,那么可能导致张三账户扣了500,李四钱没到账。开启了事务管理之后,张三李四转账过程,不再看成2部分,看成一个整体,如果有出错,就在出错之后,设置回滚,数据就回到开启事务之前;如果没有出现错误,那么就提交数据才真真改变。
默认提交和自动提交
* 事务提交的两种方式:
* 自动提交:
* mysql就是自动提交的
* 一条DML(增删改)语句会自动提交一次事务。
* 手动提交:
* Oracle 数据库默认是手动提交事务
* 需要先开启事务,再提交
* 修改事务的默认提交方式:
* 查看事务的默认提交方式:SELECT @@autocommit; -- 1 代表自动提交 0 代表手动提交
* 修改默认提交方式: set @@autocommit = 0;
开启事务就相当于使用手动的提交事务。 也就是说,要commit提交
注意的是:
- Oracle是默认手动提交事务的
- 手动提交事务一定要commit才会生效【增删改等操作】,没提交数据都是临时的。
事务的四大特征:

其中,隔离性是事务之间相互独立的,但实际上是会互相影响的,所以我们要了解一下事务隔离级别。
隔离级别简介
MySQL不会出现幻读

案列设置:
打开2个数据库:1个是张三转账,1个是李四查账
脏读:
李四向张三借500,张三用脏读的方式借给李四,即开启事务进行转账操作,但是没有提交;然后,他叫李四去另外的数据库查看余额。李四看了余额觉都没问题就写了欠条。张三拿到借条后,又在那个没有提交的事务管理上使用回滚,把钱恢复到开启事务之前,结果李四钱没借着,反而还要还张三500。
-----------------提交和回滚可以看作某个事务管理的结束操作
出现脏读的时候,也会出现不可重复读的问题:(重复读不一样的数据)
比如,
张三在转账操作后的时候(没提交),李四查账是符合结果意愿的,即数据合理。
张三又把转账操作进行回滚,转账事务管理操作结束,李四查账的数据变动了,变得不合理。
而,李四在同一个事务操作的过程种,读取到了2次不同的数据。
可重复读
可重复读是解决不可重复的。
具体操作过程:
张三李四分别2个数据库运行并开启事务管理,张三进行了转账操作,而且没有提交;这时的李四不再是以前的李四了,查询余额,钱还在,大家都没变;张三,发现没得逞就提交算了,李四再次查询余额,钱还是没变。李四在一次事务中又2次读取余额是一样的(可重复),当李四提交事务管理后,转账才真真生效。
串行化
意思:当数据库设置了串行化的时候,一个数据库在开启事务进行操作的时候,其他数据库不能对该数据库进行操作、查询,其他数据库都被锁起来了,除了正在操作的数据库提交事务。
管理用户

一般管理用户不要在视图表中直接搞,要用语法。
主机名:
localhost:是指当前本地主机
% :是指所有主机,本地和远程
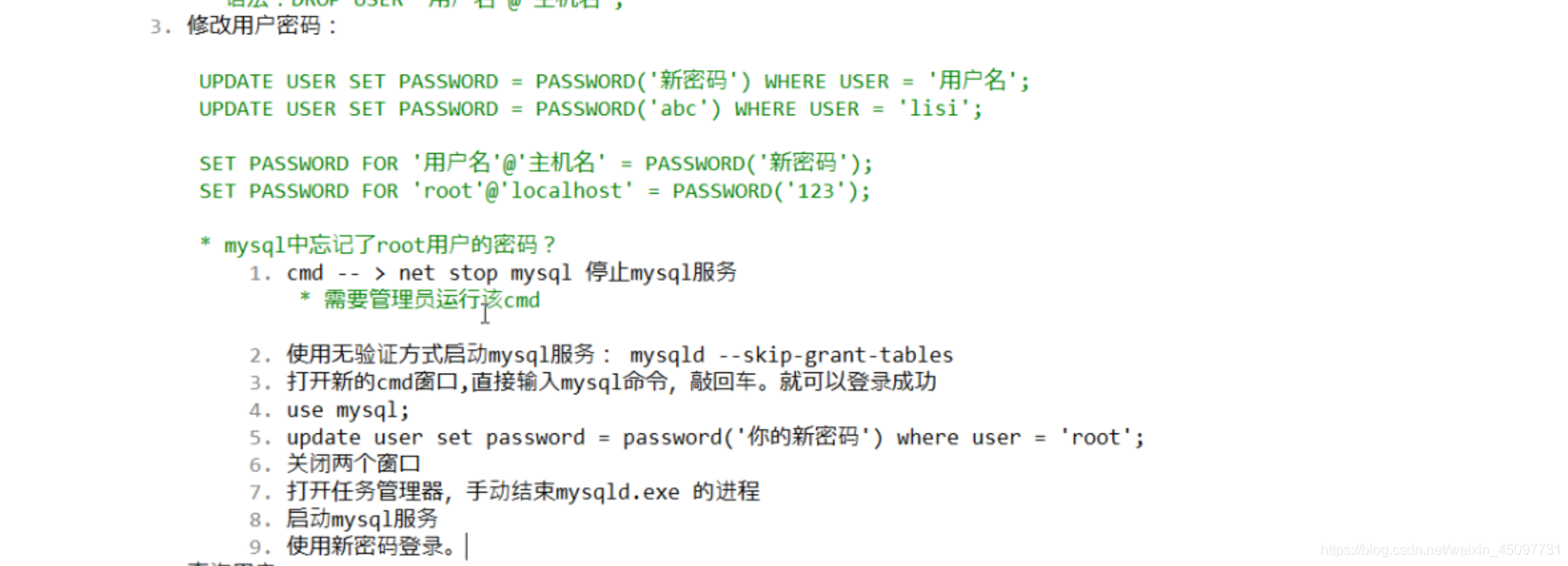
修改密码以及管理员root密码忘记的解决方案
授予权限
