1、背景知识
一个优秀的软件需要具备的特点:
1: 软件的实用性
软件的诞生就是为了解决特定的问题,比如现在流行的 MVC 框架,早期没有 MVC 开发的时候,耦合度很大,后期维护更新成本搞,难度大,这样 MVC 框架就孕育而生;比如 OA 系统为了解决公司协同的问题 ;比如 微信 QQ 等,即时聊天 为了解决人们远程沟通的问题。
2:软件的稳定性
软件的实用性问题解决后,急需要解决的问题就是软件的稳定性。一般线上系统都会承载企业的某项业务,系统的稳定性直接影响了业务是否能够正常运行。
3:代码的规范性
铁打的营盘流水的兵,一款优秀的软件不仅仅是功能的实现。整体架构、功能某块、代码注释、扩展性等问题也需要考虑,毕竟在一个软件的生命周期中,参与的人实在太多、主创人员也可能随时六十。所以代码的规范性就难能可贵。
4:升级保持向前兼容性
如果一个软件平时使用挺好,但是升级却越来越非晶,或者升级后稳定性大打折扣,也能以成得上一个好的软件。
5:基本的使用手册
文档,一个简单有效的使用手册,才是程序的王道。能让用户一目了然,功能、架构、设计思路、代码等等。
2、需求分析:
随着公司业务发展,支撑公司业务的各种系统越来越多,为了凹征公司的业务正常进行,急需要对这些现上系统的运行进行监控,做到问题的即使发现和处理,最大程度减少对业务的影响。
目前的系统分类有:
1)有基于 Tomcat 的 web 应用
2)有独立的 java Application 应用
3)有运行在 linux 上的脚本程序
4)有大规模的集群框架(zookeeper、Hadoop、Storm、SRP.....)
5)有操作系统的运行日志 (top)
主要功能需求分为: 监控系统日志中的内容,按照一定规则进行过滤 、发现问题之后通过短信和邮件进行告警。
3、功能分析 :
数据输入:
日志数据:使用 flume 客户端获取各个系统的数据;
规则数据:用户通过页面输入系统名称/负责人出发规则等信息;
数据储存:
使用 flume 采集数据并存放在 kafka 集群中
数据计算:
使用 storm 编写程序对日志进行过来,将满足过滤规则的信息,通过邮件短信 告警并保存到数据库中。
数据展示:
管理页面可以查看出发规则的信息。系统负责人,联系方式,触发信息明细等
4、整体架构设计
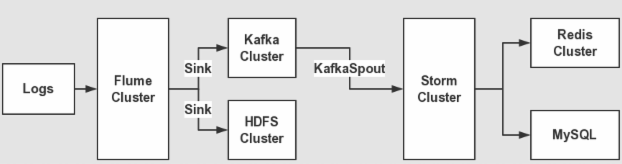
主要的架构应用 : flume + kafka +storm + mysql + java web 数据流程如下:
1:应用程序使用 log4j 产生日志
2:部署 flume 客户端监控应用产生的日志信息,并发送到 kafka 集群中
3:storm spout 拉取 kafka 数据进行消费,逐条过滤每条日志进行规则判断,对符合规则的日志进行邮件告警。
4:最后将警告的信息保存到 mysql 数据库中,用来进行管理。
Flume 设计
flume 是一个分布式、可靠的、可用的服务,用来收集、聚合、传输日志数据。
它是一个基于流式数据的架构,简单而灵活。具有健壮性。容错机制、故障转移、恢复机制。提供一个简单的可扩展的数据库模型,允许在线分析程序
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /export/data/flume_source/click_log/info.log
a1.sources.r1.channels = c1
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = cn.itcast.flume.AppInterceptor$AppInterceptorBuilder
# 用来标识 日志所属系统
a1.sources.r1.interceptors.i1.appId = 1
a1.channels.c1.type=memory
a1.channels.c1.capacity=10000
a1.channels.c1.transactionCapacity=100
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = log_monitor
a1.sinks.k1.brokerList = HADOOP01:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
a1.sinks.k1.channel = c1拦截器
package cn.itcast.flume;
import org.apache.commons.lang.StringUtils;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.List;
/**
* 1、实现一个InterceptorBuilder接口
* 2、InterceptorBuilder中有个configuref方法,通过configure获取配置文件中的相应key。
* 3、InterceptorBuilder中有个builder方法,通过builder创建一个自定义的MyAppInterceptor
* 4、AppInterceptor中有两个方法,一个是批处理,一个单条处理,将批处理的逻辑转换为单条处理
* 5、需要在单条数据中添加 appid,由于appid是变量。需要在AppInterceptor的构造器中传入一些参数。
* 6、为自定义的AppInterceptor创建有参构造器,将需要的参数传入进来。
*/
public class AppInterceptor implements Interceptor {
//4、定义成员变量appId,用来接收从配置文件中读取的信息
private String appId;
public AppInterceptor(String appId) {
this.appId = appId;
}
/**
* 单条数据进行处理
* @param event
* @return
*/
public Event intercept(Event event) {
String message = null;
try {
message = new String(event.getBody(), "utf-8");
} catch (UnsupportedEncodingException e) {
message = new String(event.getBody());
}
//处理逻辑
if (StringUtils.isNotBlank(message)) {
message = "aid:"+appId+"||msg:" +message;
event.setBody(message.getBytes());
//正常逻辑应该执行到这里
return event;
}
//如果执行以下代码,表示拦截失效了。
return event;
}
/**
* 批量数据数据进行处理
* @param list
* @return
*/
public List<Event> intercept(List<Event> list) {
List<Event> resultList = new ArrayList<Event>();
for (Event event : list) {
Event r = intercept(event);
if (r != null) {
resultList.add(r);
}
}
return resultList;
}
public void close() {
}
public void initialize() {
}
public static class AppInterceptorBuilder implements Interceptor.Builder{
//1、获取配置文件的appId
private String appId;
public Interceptor build() {
//3、构造拦截器
return new AppInterceptor(appId);
}
public void configure(Context context) {
//2、当出现default之后,就是点击流告警系统
this.appId = context.getString("appId","default");
System.out.println("appId:"+appId);
}
}
}
Kakfa 设计
kafka是一个分布式消息队列:生产者、消费者的功能
分片以及副本数 定义:
1)创建一个 topic all_app_log
2) 指定分片数据,指定副本数(假设 实际日志有 3T 规模)需要 10 个分片 3个 副本
3T 的日志数据
平均每秒数据量:3T / 24H = 0.125T=125G / 60 M = 20G / 60S = 20000M / 60S = 333M
峰值的数据量:333M * 3
考虑活动峰值:333M * 3 * 3
结论:每秒需要处理 3G 的数据 ;kafka 理论值数据量是 600m / S ,实际折算 300M/S
3G / 300M = 10 分片
3)如何计算副本数
broker 数量大于 10 ,只需要副本数为 2
broker 数量小于 10 ,需要副本数为 3
4)kafka 保存数据策略 168 小时,存储数据3 * 3T * 7D = 63T
kafka-topics.sh --create --zookeeper hadoop01:2181 --replication-factor 3 --partitions 10 --topic all_app_log
