一、技术栈介绍
前端
我们所制作的产品是一款Android APP,一切开发基于Google的Android SDK进行制作。我们使用Android Studio进行开发,开发语言为Java。
Android Studio基于IntelliJ IDEA,是Google为开发者提供的安卓开发工具,也是如今市面上使用最广泛的安卓开发IDE。在该软件的框架下开发,我们能使用强大且方便的布局编辑器,拖拉UI控件并且进行效果预览。
虽然我们的目标用户是所有北航学生,也考虑到了不少北航同学使用iOS系统,但由于人数和时间的限制,我们暂无iOS前端的开发计划,力求尽快在安卓平台交付成品。如果Alpha版本的设计得到好评,我们会考虑开发iOS前端。
后端
后端使用Django作为框架,MySQL作为数据库,基于Python语言实现。
Django本身是一款前后端可以兼顾的框架,也能够做全栈开发,不过我们只使用其后端的相关功能。Django具有基础的MVC设计模式,提供了大量的基础功能,能够满足我们前后端交互的需求。我们可能会考虑使用Django REST Framework作为后端的实现框架,体现RESTful开发。
数据库
数据库使用MySQL。MySQL数据库是我们最熟悉也是使用人数较多的一款数据库,较为稳定,且相关技术较为成熟,和Django的相性也很好。
Django自带的SQLite数据库较为轻便,可以作为本地调试使用,但不适合部署在服务器上供应较多的人使用,性能可能会受限。
爬虫
目前由于安全原因,学校并没有向学生直接开放数据库的读取接口,我们也无法用常规方式获取教务网站上的数据。但是我们依然想要制作这样一款软件,所以不得已选取了爬虫来获取数据
由于北航教务的session验证较为复杂,且教务系统中有iframe之类的较为复杂的结构,使用一般的爬虫框架较为困难,所以我们选择简单易用的无头浏览器Selenium作为从学校获取数据的工具。
我们会控制爬取的频率和数据,也会保证不会进行越界操作,极大程度上保护用户的安全。
同时,数据库中的静态数据采用加密存储方式,解密密钥由用户生成,掌握在用户手中,使得开发人员无法通过简单的查询数据库的方式来获取到大家的统一认证账户。
云环境
我们暂定使用课程组提供的华为云资源,为1核1G的服务器。
考虑到实际情况,1核1G太少,未必能够满足我们的需求,在爬虫进行较高频率的爬取时,可能会导致内存不足,以及服务器最重要的带宽多多少少会影响到我们的响应速度。如果在实践过程中发现不足,可能会考虑自费更换更高配置的服务器。
二、前后端接口设计
前后端的对接使用HTTPS请求来完成。同时,我们的设计思路遵循RESTful原则,前端只需要调用接口即可获得数据,不需要思考内部细节。架构设计如图:
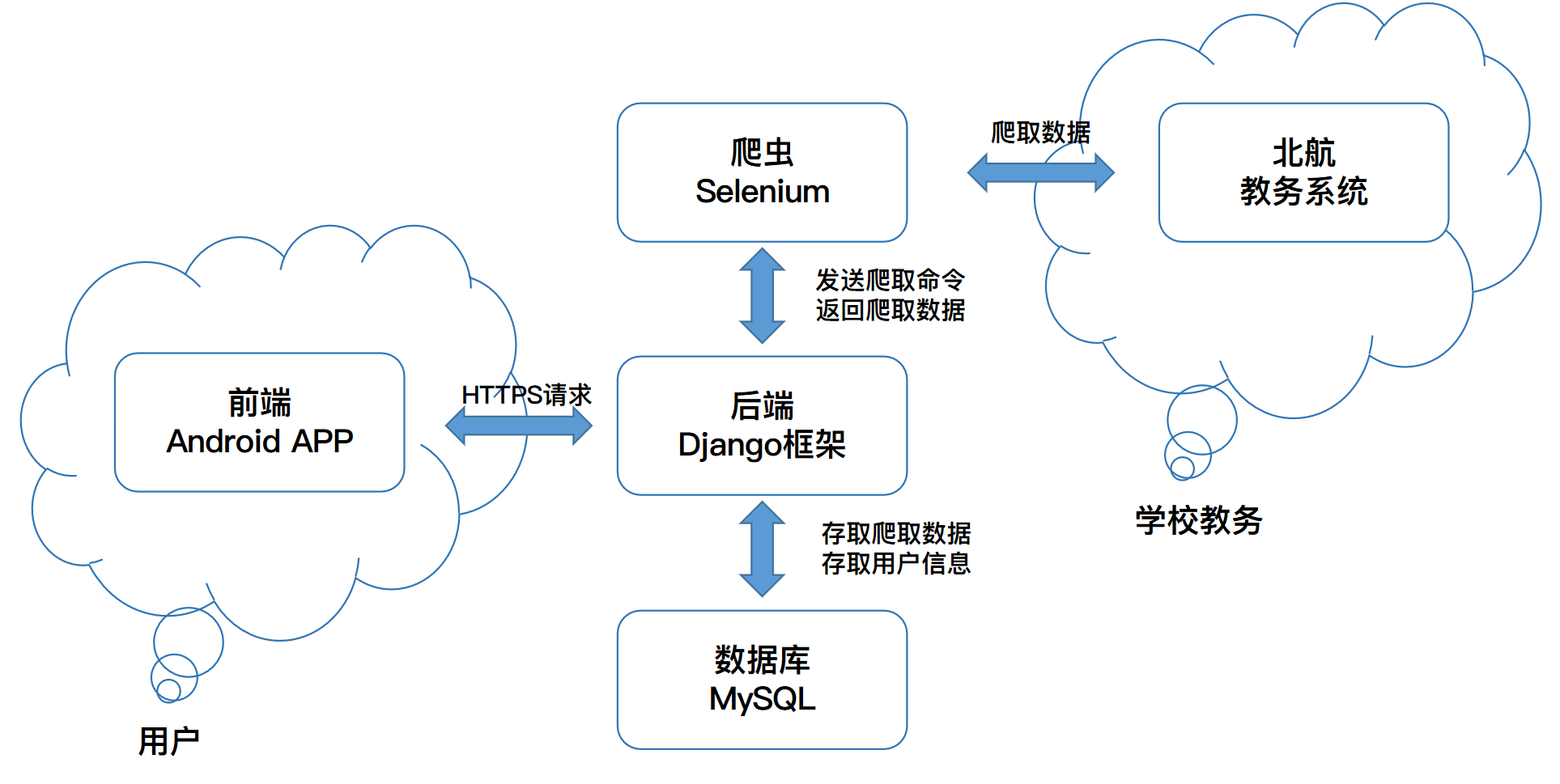
下面是暂定的接口规则,有待进一步细化。
| # | 请求方法 | 请求路径 | 用途 |
|---|---|---|---|
| 1 | POST |
/api/users/phone_num/verify/code |
手机验证发送验证码 |
| 2 | POST |
/api/users/phone_num/verify |
验证验证码是否正确 |
| 3 | POST |
/api/users/email/verify |
验证邮箱,给邮箱寄信 |
| 4 | GET |
/api/users/email/verify/:uid/:hash_code |
验证邮箱,邮箱点击链接返回 |
| 5 | POST |
/api/users/forgetpassword/email |
忘记密码,绑定的邮箱 |
| 6 | GET |
/api/users/forgetpassword/email/verify/:uid/:hash_code |
忘记密码,邮箱转跳 |
| 7 | POST |
/api/users/forgetpassword/phone_num/send |
忘记密码,手机 |
| 8 | POST |
/api/users/forgetpassword/phone_num/verify |
忘记密码,手机验证 |
| 9 | GET |
/api/users/:uid/get_class |
获取课表 |
| 10 | GET |
/api/users/:uid/update_class |
更新课表 |
| 11 | GET |
/api/users/:uid/todolist |
课程中心ddl查询 |
| 12 | GET |
/api/empty_room |
空教室查询 |
| 13 | GET |
/api/users/:uid/get_score |
成绩查询 |
三、设计原则
-
抽象
-
行为抽象
行为的抽象主要体现在前端与后端、后端与爬虫的交互上。我们对实现特定功能的接口均进行了明确的定义,其中具体的操作不需要调用者去操心。
-
数据抽象
我们将所有数据存在数据库中,数据库设计在models.py中,将每个表封装成了对象,方便增删读写的操作。同时将结构的变动维护为迁移记录,方便日后的开发维护。
-
-
内聚/耦合/模块化
主要体现在后端的设计上。后端使用的Django框架本身支持较为方便的MVC模式,每个不同的功能可以设计进不同的djangoapp,每个djangoapp都有独立的方法进行管理,它们之间不会在数据和功能上相互影响。
前端APP也分为不同的页面,其每个页面有自己独立的功能,它们之间不会相互影响,每个页面各司其职,完成它们自己的功能,这也是分工开发的必然。
-
信息隐藏和封装、界面和实现的分离
信息的隐藏封装,也是前后端分离架构的一大原则。我们没有把所有的查询功能放在用户程序中去实现,而是经历用户-服务器-教务的过程,之间用尽可能少的信息来进行交互隐藏,仅仅通过API交流,互相不暴露内部细节。
而用户手中的前端Android APP,本身就具有较好的封装性,解包和非法读取数据有一定的难度,也对信息的隐藏封装、界面和实现的分离有较好的帮助。
-
如何处理错误情况
作为一款Android APP,前端留给用户犯错的机会十分有限,若出现输入非法之类的简单错误,则会在前端检出,不会将请求发送给后端。
大多数错误会在后端被检出。一旦检出错误,或者后端内部的爬虫出现爬取错误,则会返回相应的HTTP Status Code,来判断发生了什么样的错误。前端将Code转译为文字,告诉用户具体发生的错误是什么,给予用户详细的操作指导。
-
程序模板对于运行环境、相关模板、输入输出参数有什么假设?这些假设和相关的人员验证过么?
前端的运行环境和模板基于Android平台,其上本身具有大量应用可供参考,且我们的产品并没有性能和网络需求,所以不会有太大的问题。
后端可能对于高并发爬虫处理存在着一些问题,主要是服务器资源占用过大,导致性能跟不上,如果后续实践中出现相关问题,我们会立即更换云端环境。
前后端交互依赖HTTPS请求,其输入输出参数本身就有很严格的标准限制,且我们有充分的错误处理设计,在交互上不会出现很大的问题。
-
应对变化的灵活性
灵活性建立在模块化和低耦合之上。我们对前后端尽可能的分离、后端尽可能的模块化也是基于这一点。如果出现新的需求,或者教务网站出现意外情况,我们能在修改尽可能少的代码的情况下,完成我们的工作,能够体现出高度的灵活性。
-
对大量数据的处理能力
后端对于大量来源于前端的请求处理能力,建立在Django框架的合理性和服务器本身的性能之上,这两者都已经在其他大型项目中得到过验证。而在接口设计方面,我们已经尽可能将API和数据传输内容进行简化,不会因为接口问题而导致处理出线难度。
爬虫对于来自于后端的大量命令处理可能是一个难点。服务器本身的带宽和资源不支持多开chrome进行高并发查询,所以我们的解决办法是尽量减少爬取次数。能够通过缓存机制解决,能够确定短时间内不会变化的数据,我们不会进行重复爬取,尽可能减小服务器压力。