某个应用的CPU使用率达到100%,该怎么办?
一般用来描述系统的CPU性能指标:平均负载、CPU上下文切换还有CPU使用率
CPU使用率
Linux作为一个多任务操作系统,将每个CPU的时间划分为很短的时间片,再通过调度器轮流分配给每个任务使用,因此造成多任务同时运行的错觉。
Linux通过/proc虚拟文件系统,向用户提供了系统内部状态的信息。 比如 /proc/stat 提供了系统的CPU和任务统计信息

有需要的时候,查询man proc就可以清楚每一列的涵义,她们都是CPU使用率相关重要指标

CPU使用率就是除了空闲时间之外的其他时间占总CPU时间的百分比
事实上,为了计算CPU使用率,性能工具一般都会取间隔一段时间(比如3s)的两次值,作差后,再计算出这段时间内的平均CPU使用率,而直接使用/proc/stat的数据一般都是开机以来的累加值然后的平均CPU使用率,一般没有什么参考价值
性能分析工具给出的都是间隔一段时间的平均CPU使用率,所以要注意间隔时间的设置,比如 top和ps这两个工具报告CPU使用率,默认的结果很可能不一样,因为top默认是3s间隔时间,而ps是用的确实进程的整个生命周期。
怎么查看CPU使用率
top和ps是常用的性能分析工具,top显示了系统总体的CPU和内存使用情况,以及各个进程的资源使用情况。ps则只显示了每个进程的资源使用情况

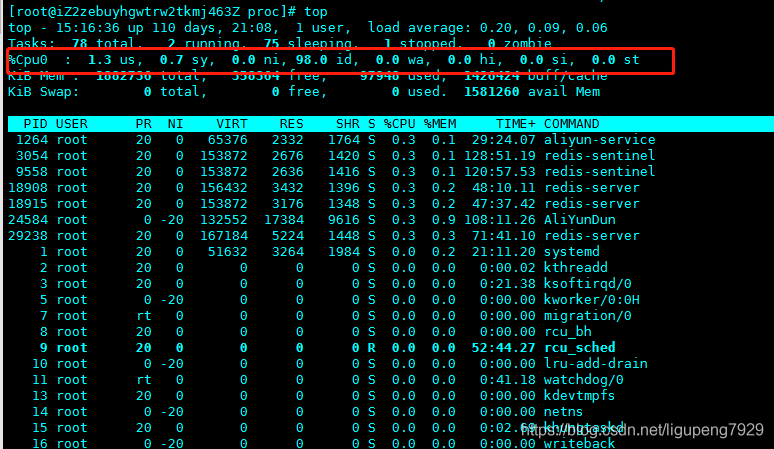
第三行 %Cpu就是系统的CPU使用率,只是把CPU时间变化成了CPU使用率,不过top默认显示是所有CPU的平均值,这个时候需要按数字1,就可以切换每个CPU使用率
空白行之后是每个进程的实时信息,每个进程都有一个%CPU列,标识进程的CPU使用率。它是用户态和内核态CPU使用率的综合,包括进程用户空间使用的CPU、通过系统调用执行的内核空间CPU、以及在就绪队列等待运行的CPU。在虚拟环境中,还包括运行虚拟机占用的CPU
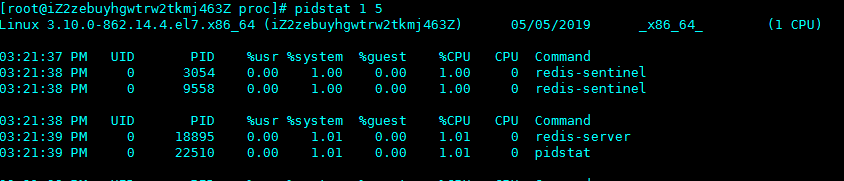
top并没有细分进程的用户态CPU和内核态CPU,可以用pidstat,它是专门分析每个进程CPU使用情况的工具

CPU使用率过高怎么办?
通过top、ps、pidstat等工具,能够轻松找到CPU使用率较高的进程,接下来怎么查找占用CPU的代码是哪个函数呢?
首先是GDB,这个功能强大的程序调试利器,但是,GDB并不适合在性能分析的早期应用,因为GDB调试程序过程会终端程序运行,这在线上环境往往是不允许的。所以,GDB只适合在性能分析的后期,当找到了出问题的大致函数后,线下再借助它进一步调试函数内部问题。
我这里使用pref分析问题,通常使用pref top。表格式样的数据:

其中第二种常见用法也就是perf record和perf report。perf top虽然实时展示系统的性能信息,但是它的缺点并不保存数据,无法用于离线或者后续分析,而perf record则提供了保存数据功能,保存后的数据用perf report解析展示。还可以加-g 参数开启调用关系的采样。
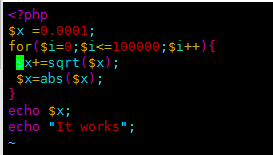
案例:PHP+Nginx的Web服务为例,当发现CPU使用率过高的问题
1>首先,并发10个请求测试Nginx性能,测试100个请求
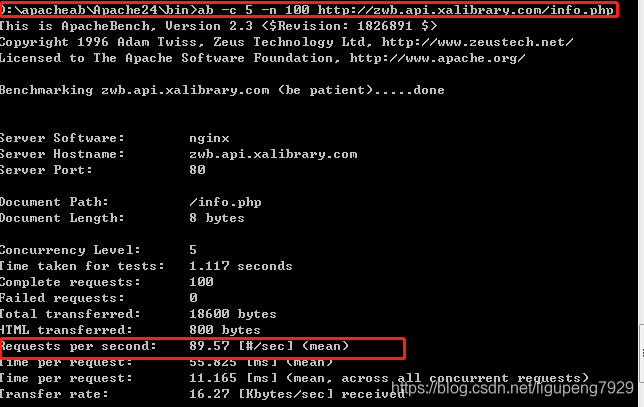
Nginx承受每秒的平均请求只有89.57,将测试请求增加到10000时候呢。
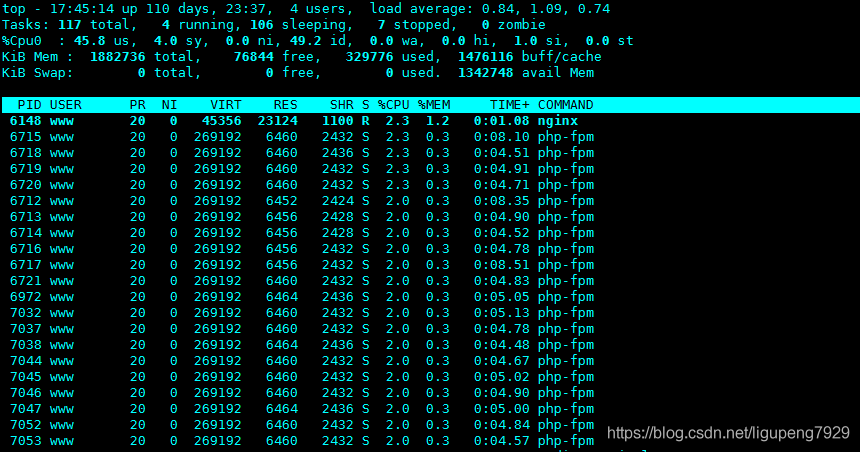
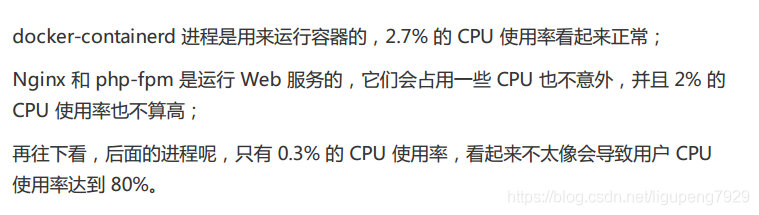
可以看到PHP-fpm使用率加起来接近
通过perf top -g -p 进程号

然后查找这两个函数,发现了文件的源码
小结:
CPU使用率是最直观最常用的系统性能指标,我们在排查性能问题通常会关注第一个指标,尤其弄清楚用户(%user)、Nice(%nice)、系统(%system)、等待I/O(%iowait)、中断(%irq)以及软中断(%softirq)这几种不同CPU使用率
比如说:

系统的CPU使用率很高,却找不到原因?
当系统的的CPU使用率很高的时候,不一定能找到相对应高的CPU使用率进程
案例分析:
1>首先进行ab压力测试
2>然后第一个终端运行top,观看CPU
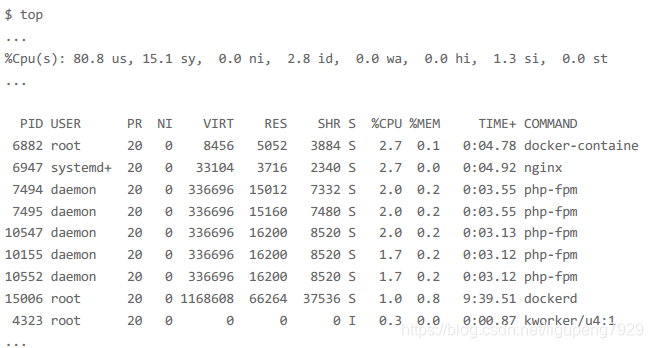
发现用户的CPU使用达到80%,系统的使用15%,空闲CPU(id)只有2.8。
也没有发现可疑进程:
3>这个时候看来top不管用了,接下来使用pidstat,分析进程的CPU使用情况
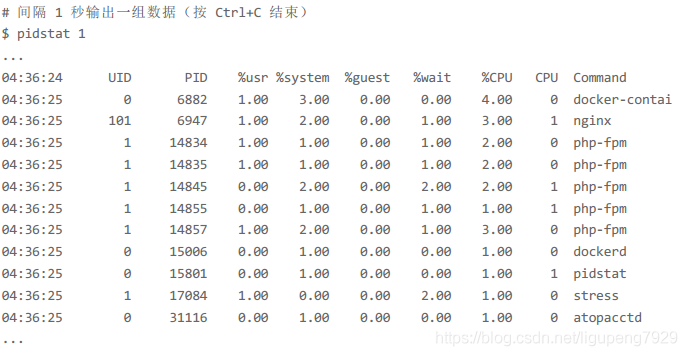
这个时候也发现CPU使用率不高,Docker和Nginx也是有4%和3%,但是CPU使用率高达80%
5>我们再次运行top,并且观察发现
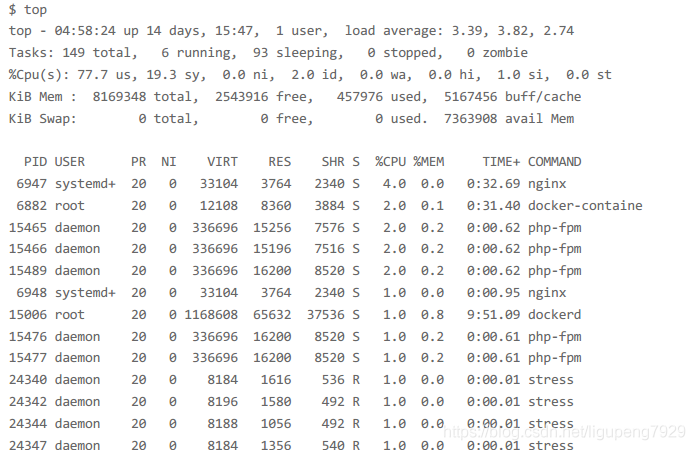
ab测试的参数,并发请求为5,在看进程表的话php-fpm数量也是5,再加上Nginx,一共六个,但是这些都是出于Sleep(S)状态,真正在Running(R)的是stress进程。
6>但是根据进程PID,pidstat分析这几个进程使用-P选项,却没有任何输出

这个时候在怀疑性能工具出问题之前,最好先用其他工具交叉确认下,使用ps查看进程的状态
7>这个时候发现原来进程不存在了,所以pidstat没有任何输出,所以既然进程没有了,那么性能问题也没有了吧

8>这个时候再用top确认一下


结果还是一样CPU使用率高达80%,并且原来的我们看到的stress进程的ID跟前面是不同了。进程的PID再变,这说明什么?

9>这个时候可以使用perf record -g命令 ,并等待一会(15s)后按 Ctrl+C退出。然后再运行perf report 查看报告。
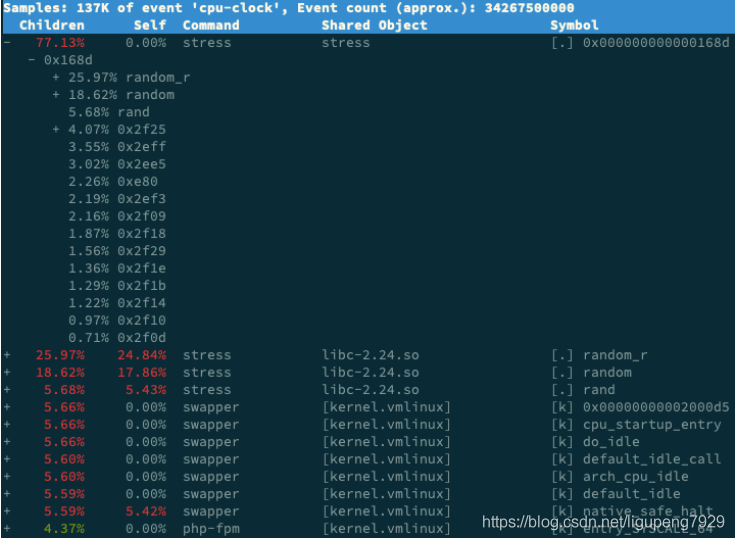
这个时候看到stress占用CPU时钟事件的77%,而且调用栈比较最高,是随机生成函数random(),这个时候只要减少或者删除stress调用就可以减轻系统的CPU压力
execsnoop:在这里案例中,我们使用了top、pidstat、pstree等工具分析了CPU使用率高的问题,并发现CPU升高是短时进程stress导致的,这个分析比较复杂。
这个时候就可以用更好地办法监控,execsnoop就是一个专为短时进程设计的工具。它通过ftrace实时监控进程的exec()行为,并输出短时进程的基本信息,包括进程PID、父进程PID、命令行参数以及执行结果。比如通过execsnoop监控上述案例,就可以直接得到大量stress在不停启动。
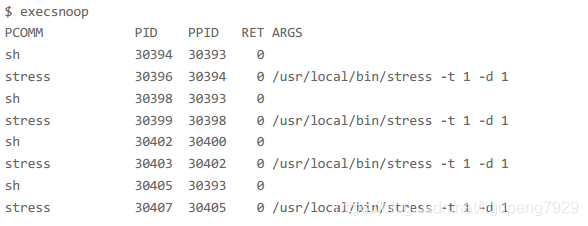
execsnoop所用的ftrace是一种常用的动态追踪技术,一般用于分析Linux内核的运行时行为
小结:碰到常规问题无法解释的CPU使用率情况时,首先想到有可能是短时应用导致的问题。有这两种情况
第一:应用里直接调用了其他二进制程序,这些程序通常运行时间短,通过top等工具不容易发现
第二:应用本身不断的崩溃重启,而启动过程的资源初始化,占用相当多CPU
对于这类进程,我们可以用pstree或者execsnoop找到他们父进程,再从父进程所在应用入手排查问题的根源
