一、套接字概述
套接字地址结构可以在两个方向上传递: 从进程到内核和从内核到进程。地址转换函数在地址的文本表达和它们存放在套接字地址结构中的二进制之间进行转换。多数现存的IPv4代码使用inet_addr和inet_ntoa这两个函数,不过两个新函数inet_pton和inet_ntop同时适用于IPv4和IPv6两种代码。二、套接字地址结构
大多数套接字函数都需要一个指向套接字地址结构的指针作为参数。每个协议族都定义它自己的套接字地址结构。这些结构的名字均以sockaddr_开头,并以对应每个协议族的唯一后缀结尾。
(1)IPv4套接字地址结构
IPv4套接字地址结构通常也称为“网际套接字地址结构”,它以sockaddr_in命名,定义在<netinet/in.h>头文件中。它的POSIX定义如下:

A、长度字段sin_len是为增加对OSI协议的支持而随4.3BSD—Reno添加的,有了长度字段,才简化了长度可变套接字地址结构的处理。即使有了长度字段,我们也无须设置和检查它,除非涉及路由套接字。
B、POSIX规范只需要这个结构中的3个字段:sin_family、sin_addr和sin_port。对于符合POSIX的实现来说,定义额外的结构字段是可以接受的,这对于网际套接字地址结构来说也是正常的。几乎所有的实现都增加了sin_zero字段,所以所有的套接字地址结构大小都至少是16字节。
C、sin_addr、sin_family、sin_port的POSIX数据类型。in_addr_t数据类型必须是一个至少32位的无符号整数类型,in_port_t必须是一个至少16位的无符号整数类型,而sa_family_t可以是任何无符号整数类型。在支持长度字段的实现中,sa_family_t通常是一个8位的无符号整数,而在不支持长度字段的实现中,它则是一个16位的无符号整数。具体如下图

D、IPv4地址和TCP或UDP端口号在套接字地址结构中总是以网络字节来存储。
E、32位IPv4地址存在两种不同的访问方法。举例,如果serv定义为某个网际套接字地址结构,那么serv.sin_addr将按in_addr结构引用其中的32位IPv4地址,而serv.sin_addr.s_addr将按in_addr_t(通常为一个无符号的32位整数)引用同一个32位IPv4地址。因此,必须正确使用IPv4地址。
F、sin_zero字段未曾使用,不过在填写这种套接字地址结构时,我们总是把该字段置为0。按照惯例,我们总是在填写前把整个结构置为0,而不单是置sin_zero字段为0。
(2)通用套接字地址结构
当作为一个参数传递进任何套接字函数时,套接字地址结构总是以引用形式(也就是以指向该结构的指针)来传递。然而以这样的指针作为参数之一的任何套接字函数必须处理来自所支持的任何协议族的套接字地址结构。在如何声明所传递指针的数据类型上存在一个问题。有了ANSI C后解决办法很简单:void * 是通用的指针类型。然而套接字函数是在ANSI C之前定义的,在1982年采取的办法是在<sys/socket.h>头文件定义一个通用的套接字地址结构,如图

于是套接字函数被定义为以指向某个通用套接字地址结构的一个指针作为其参数之一,这正如bind函数的ANSI C函数原型所示:
// int bind(int, struct sockaddr *, socklen_t); //
这就要求对这些函数的任何调用都必须要将指定特定于协议的套接字地址结构的指针进行类型强制转换(casting),变成指向某个通用套接字地址结构的指针,如:
//
struct sockaddr_in serv; /*IPv4 socket address structure*/
/* fill in serv{} */
bind(sockfd, (struct sockaddr *) &serv, sizeof(serv));
//
(3)套接字地址结构的比较

三、值-结果参数
当往一个套接字函数传递一个套接字地址结构时,该结构总是以引用形式来传递,也就是说传递的是指向该结构的一个指针。该结构的长度也作为一个参数来传递,不过其传递方式取决于该结构的传递方向:是从进程到内核,还是从内核到进程。
(1)从进程到内核传递套接字地址结构的函数有3个:bind、connect和sendto。这些函数的一个参数是指向某个套接字地址结构的指针,另一个参数是该结构的整数大小,例如:
//
struct sockaddr_in serv;
/* fill in serv{} */
connect(sockfd, (struct sockaddr *) &serv, sizeof(serv));
//

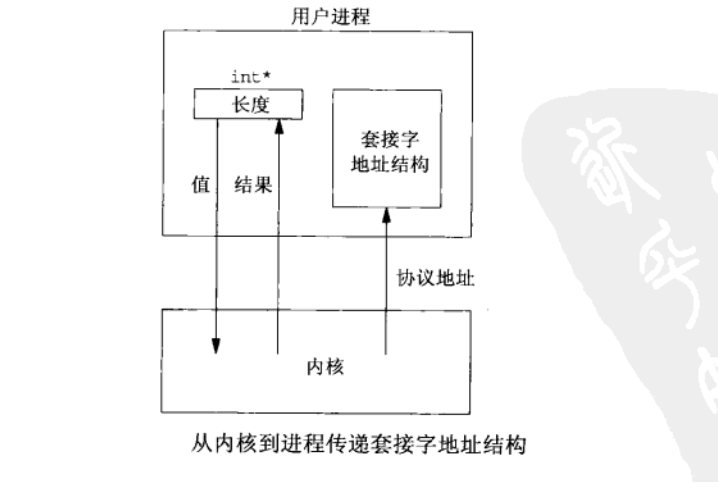
(2)从内核到进程传递套接字地址结构的函数有4个:accept、recvfrom、getsockname和getpeername。这4个函数的其中两个参数是指向某个套接字地址结构的指针和指向表示该结构大小的整数变量的指针。例如:
// struct sockaddr_un cli; /* Unix domain */ socklen_t len; len = sizeof(cli); /* len is a value */ getpeername(unixfd, (struct sockaddr *) &cli, &len); /* len may have changed */ //
把套接字地址结构大小这个参数从一个整数改为指向某个整数变量的指针,其原因在于:当函数被调用时,结构大小是一个值(value),它告诉内核该结构的大小,这样内核在写该结构时不至于越界;当函数返回时,结构大小又是一个结果(result)。它告诉进程内核在该结构中究竟存储了多少信息。这种类型的参数称为值-结果(value-result)参数。如图:
四、字节排序函数
1、一个16位整数,它由2个字节组成。内存中存储这两个字节有两种方法:一种是将低序字节存储在起始地址,这称为小端(little-endian)字节序;另一种方法是将高序字字节存储在起始地址,这称为大端(big-endian)字节序。具体如图:
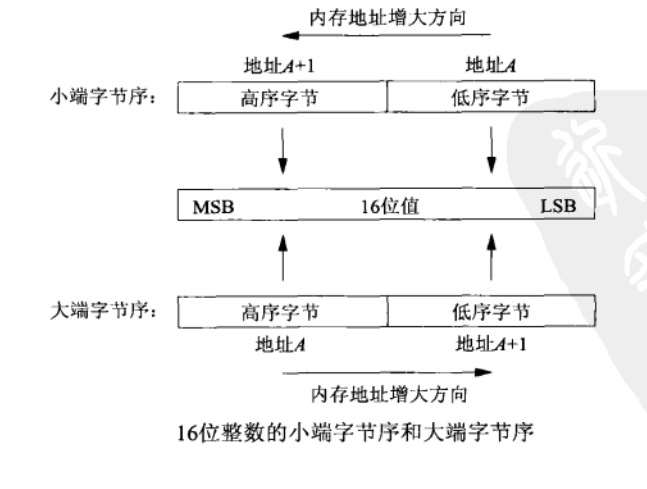
MSB:most significant bit 即最高有效位 LSB:least significant bit 即最低有效位
2、这两种字节序之间没有标准可循,两种格式都有系统使用。我们把某个给定系统所用的字节序称为主机字节序(host byte order)。网络协议必须指定一个网络字节序(network byte order),所以需要区分清不同字节序之间的差异。比如,在每个TCP分节中都有16位的端口号和32位的IPv4地址。发送协议栈和接收协议栈必须就这些多字节字段各个字节的传送顺序达成一致。网际协议使用大端字节序传送这些多字节整数。由于历史的原因和POSIX规范的规定,套接字地址结构中的某些字段必须按照网络字节进行维护。因此需要注意主机字节序和网络字节序之间相互转换。这两种字节序之间的转换使用以下4个函数。
// #include <netinet/in.h> uint16_t htons(uint16_t host16bitvalue); /* 返回网络字节序的值 */ uint32_t htonl(uint32_t host32bitvalue); /* 返回网络字节序的值 */ uint16_t ntohs(uint16_t net16bitvalue); /* 返回主机字节序的值 */ uint32_t ntohl(uint32_t net32bitvalue); /* 返回主机字节序的值 */ //
其中h代表host,n代表network,s代表short,l代表long。short和long这两个称谓是出自4.2BSD的Digital VAX实现的历史产物。如今我们应该把S视为一个16位的值(例如TCP或UDP端口号),把l视为一个32位的值(例如IPv4地址)。事实上即使在64位的DigitalAlpha中,尽管长整数占用64位,htonl和ntohl函数操作的仍然是32位的值。当使用这些函数时,我们并不关心主机字节序和网络字节序的真实值(或为大端,或为小端)。所要做的只是调用适当的函数在主机和网络字节序之间转换某个给定值。
五、字节操纵函数
1、操纵多字节字段的函数有两组,它们既不对数据作解释,也不假设数据是以空字符结束的C字符串。当处理套接字地址结构时,我们需要这些类型的函数,因为我们需要操纵诸如IP地址这样的字段,这些字段可能包含值为0的字节,却并不是C字符串。以空字符结尾的C字符串是由在<string.h>头文件中定义、名字以str(表示字符串)开头的函数处理的。名字以b(表示字节)开头的第一组函数起源于4.2BSD,几乎所有现今支持套接字函数的系统仍然提供它们。名字以men(表示内存)开头的第二组函数起源于ANSI C标准,支持ANSI C函数库的所有系统都提供它们。
// #include <strings.h> void bzero(void *dest, size_t nbytes); /* 源自Berkeley的函数,参数只有两个,比3个参数的memset函数好记 */ void bcopy(const void *src, void *dest, size_t nbytes); int bcmp(const void *ptrl, const void *ptr2, size_t nbytes); //
bzero把目标字节串中指定数目的字节置为0。我们经常使用该函数来把一个套接字地址结构初始化为0。bcopy将指定数目的字节从源字节串移到目标字节串。bcmp比较两个任意的字节串,若相同则返回值为0,否则返回值为非0。
2、ANSI C函数:
// #include <string.h> void *memset(void *dest, int c, size_t len); void *memcpy(void *dest, const void *src, size_t nbytes); int memcmp(const void *ptr1, const void *ptr2, size_t nbytes); /*返回:若相等则为0,否则为<0或>0 */ //memset把目标字节串指定数目的字节置为值c。memcpy类似bcopy,不过两个指针参数的顺序是相反的。当源字节串与目标字节串重叠时,bcopy能够正确处理,但是memcpy的操作结果却不可知。这种情况下必须改用ANSI C的memmove函数。
记住memcpy两个指针参数顺序的方法之一时记住它们是按照与C中赋值语句相同的顺序从左到右书写的:dest = src;
记住memset最后两个参数顺序的方法之一是认识到所有ANSI C的memXXX函数都需要一个长度参数,且总是最后一个参数。
六、inet_aton、inet_addr和inet_ntoa函数
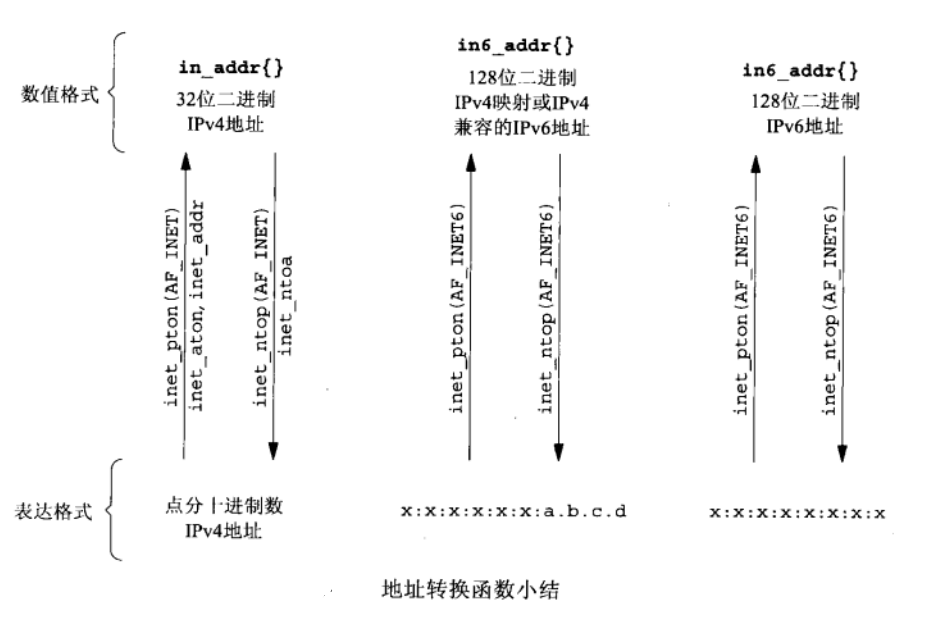
1、下面是两组地址转换函数,它们在ASCII字符串与网络字节序的二进制值(这是存放在套接字地址结构中的值)之间转换网际地址。
(1)inet_aton、inet_addr和inet_ntoa在点分十进制数串(例如“192.168.1.66”)与它长度为32位的网络字节序二进制置间转换IPv4地址。
(2)两个较新的函数inet_pton和inet_ntop对于IPv4地址和IPv6地址都适用。
// #include <arpa/inet.h> int inet_aton(const char *strptr, struct in_addr *addrptr); in_addr_t inet_addr(const char *strptr); char *inet_ntoa(struct in_addr inaddr); //
其中a表示addr,n表示network
A、inet_aton函数将strptr所指C字符串转换成一个32位的网络字节序二进制值,并通过指针addrptr来存储。若字符串有效则为1,否则为0。注:inet_aton函数中,如果addrptr指针为空,那么该函数仍然对输入的字符串执行有效性检查,但是不存储任何结果。
B、inet_addr进行相同的转换,返回值为32位的网络字节序二进制值(IPv4地址)。该函数存在一个问题:所有2^32个可能的二进制值都是有效的IP地址(从0.0.0.0到255.255.255.255),但是当出错时该函数返回INADDR_NONE常值(通常是一个32位均为1的值)。这意味着点分十进制数串255.255.255.255(这是IPv4的有限广播地址)不能由该函数处理。该函数出错时返回可能是-1而不是INADDR_NONE。这样该函数的返回值可能是-1也可能是INADDR_NONE,所以比较时会出问题,具体取决于C编译器。如今inet_addr函数已废弃,新的代码会使用inet_aton函数。
C、inet_ntoa函数返回:指向一个点分十进制数串的指针。inet_ntoa函数将一个32位的网络字节序二进制IPv4地址转换成相应的点分十进制数串。由该函数的返回值所指向的字符串驻留在静态内存中。这意味着该函数是不可重入的。注:该函数以一个结构体而不是指向该结构的一个指针作为其参数,这是情况是比较少见的。
七、inet_pton和inet_ntop函数
1、这两个函数是随着IPv6出现的新函数,对于IPv4地址和IPv6地址都适用。《UNIX 网络编程》一书的示例都在使用这两个函数。函数名中p和n分别代表表达(presentation)和数值(numeric)。地址的表达式格式通常是ASCII字符串,数值格式则是存放到套接字地址结构中的二进制值。
// #include <arpa/inet.h> int inet_pton(int family, const char *strptr, void *addrptr); /* 成功返回1,若输入不是有效的表达格式则为0,出错为-1 */ const char *inet_ntop(int family, const void *addrptr, char *strptr, size_t len); /* 成功则为指向结果的指针,若出错则为NULL */ //
A、这两个函数的family参数既可以是AF_INET,也可以是AF_INET6。如果以不被支持的地址族作为family参数,这两个函数就都返回一个错误,并将errno置为EAFNOSUPPORT。
B、inet_pton函数转换strptr指针所指的字符串为通过addrptr指针存放的二进制结果。
C、inet_ntop进行相反的转换。len参数是目标存储单元的大小,以免该函数溢出其调用者的缓冲区。为有助于指定这个大小,在<netinet/in.t>头文件中有如下定义:
// #define INET_ADDRSTRLEN 16 /* for IPv4 dotted-decimal */ #define INET6_ADDRSTRLEN 46 /* for IPv6 hex string */ //如果len太小,不足以容纳表达格式结果(包括结尾的空字符),那么返回一个空指针,并置errno为ENOSPC。inet_ntop函数的 strptr参数不可以是一个空指针。 调用者必须为目标存储单位分配内存并指定其大小。调用成功时,这个指针就是该函数的返回值。
2、地址转换函数小结
八、sock_ntop和相关函数
1、inet_ntop的一个基本问题是:它要求调用者传递一个指向某个二进制地址的指针,而该地址通常包含在一个套接字地址结构中,这就要求调用者必须知道这个结构的格式和地址族。这就是说,为了使用这个函数,我们必须为IPv4编写如下代码:
// struct sockaddr_in addr; inet_ntop(AF_INET, &addr.sin_addr, str, sizeof(str)); //
或为IPv6编写如下代码:
// struct sockaddr_in6 addr6; inet_ntop(AF_INET6, &addr6.sin6_addr, str, sizeof(str)); //这就使得我们的代码与协议相关了。为了解决这个问题,我们将自行编写一个名为sock_ntop的函数,它们指向某个套接字地址
结构的指针为参数,查看该结构的内部,然后调用适当的函数返回该地址的表达格式。
// #include "unp.h" char *sock_ntop(const struct sockaddr *sockaddr, socklen_t addrlen); //返回:若成功则为非空指针,若出错则为NULL
这就是《UNIX 网络编程》示例中使用的自己定义的函数(非标准系统函数)的说明形式;unp.h是自己定义的。sockaddr指向一个长度为addrlen的套接字地址结构。本函数用它自己的静态缓冲区来保存结果,而指向该缓冲区的一个指针就是它的返回值。


九、readn、writen和readline函数
字节流套接字(例如TCP套接字)上的read和write函数所变现的行为不同于通常的文件I/O。字节流套接字上调用read或write输入或输出的字节数可能比请求的数量少,然而这不是出错的状态。这个现象的原因在于内核中用于套接字的缓冲区可能已达到了极限。此时所需要的是调用者再次调用read或write函数,以输入或输出剩余的字节。有些版本的Unix在往一个管道中写多于4096字节的数据时也会表现出这样的行为。这个现象在read一个字节流套接字时很常见,但是在write一个字节流套接字时只能在该套接字为非阻塞的前提下才能出现。尽管如此,为预防万一,不让实现返回一个不足的字节计数值,我们总是改为调用writen函数来取代write函数。
致谢
1、《UNIX网络编程》卷一:套接字联网API [第3版] W.Richard Stevens、Bill Fenner、Andrew M.Rudoff 著