今天要说一下Requests模块中爬取到网页内容解码方式
response.text和 response.content两者的区别
首先要到爬取得网页上找该网页的编码方式
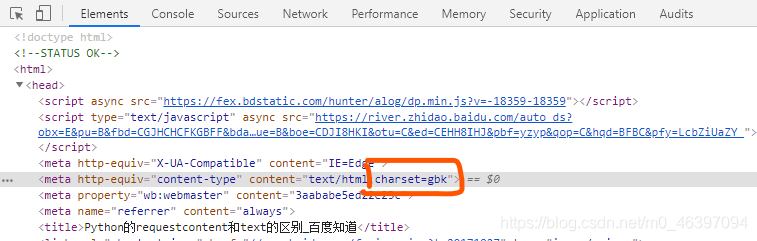
得到网页的编码方式就可以继续写代码啦
1.使用content输出
print(response.content.decode('utf-8')) #decode('utf-8')的意思是以utf-8的编码的方式解码为Unicode2.使用text输出
response.encoding = 'utf-8' #为请求的网页指定该网页的编码方式,这样text输出的时候,就不会瞎猜编码方式,而解出乱七八糟的鬼
print(response.text)参考代码(上面的response都是从参考代码里面来的)
import requests
kw = {'wd':'巴基斯坦'}
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# params 接收一个字典或者字符串的查询参数,字典类型自动转换为url编码,不需要urlencode()
#这就是requests库的其中一个方便的地方
response = requests.get("http://www.baidu.com/s", params = kw, headers = headers)
# 查看响应内容,response.text 返回的是Unicode格式的数据
print(response.text)
# 查看响应内容,response.content返回的字节流数据
print(response.content)
# 查看完整url地址
print(response.url)
# 查看响应头部字符编码
print(response.encoding)
# 查看响应码
print(response.status_code)有人看到这里就有疑问了,那我用print(response.encoding)来查看网页的编码方式
然后再来解码不行么???不行么???不行么???(你敢说不行我抽到你痉挛)
答案:当然是OK的啦哈哈哈哈哈哈(所以这是一个大彩蛋,到这样就有两种方式获得网页编码方式啦)
不过呢有时候可能会出错:比如爬百度用print(response.encoding)得到的是ISO-8859-1单字节编码
可是我去百度网址按F12查看的确是‘utf-8’编码,然后我果断用utf-8解码,因为单字节编码无法表示中文哦!
所以有时候出错的时候,可以就试一试这两种方法(目前我知道的就是这两种啦,因为我还是一个小白)
个个都是爱动脑筋的帅哥美女.....嘻嘻嘻嘻嘻(都这样说了还不给我“赞”?)
----------------------------------------------------------------------------------------------
当然有人会问啦,这个编码破东西有点不理解,能不能在帮我梳理梳理
哈哈哈哈哈哈,先给我点个赞赞赞赞
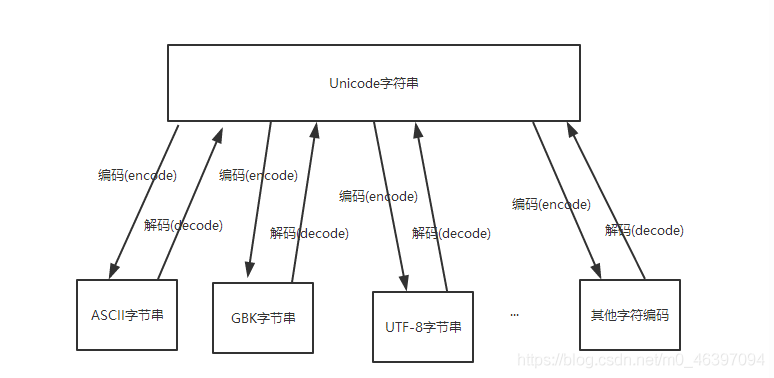
知识大放送:
encode()和decode()的区别和意思
decode英文意思是 解码,encode英文意思是 编码
字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码, 即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。
decode的作用是将其他编码的字符串转换成unicode编码,如str101.decode('utf-8'),表示将utf-8编码的字节串str101转换成unicode编码
encode的作用是将unicode编码转换成其他编码的字符串,如str101.encode('gb2312'),表示将unicode编码的字符串str101转换成gb2312编码
差不多是这个意思啦哈哈哈哈哈
最后献上一张宝图(对各位靓仔靓妹有帮助的,记得给我集个赞呀)