1:索引的本质
索引是什么?我们在学习数据库的时候都会按照书本的目录的方式来理解索引,其实索引就是一个帮助我们快速定位sql语句的排好序的数据结构。怎么理解尼?我们在学习查找算法的时候都知道,在查找有序序列的时候,采用二分法可以很快的查找对应元素,但是在数据库中,如果不采用优化索引,只有一行一行的进行比较,才能找到元素,那索引如何工作的尼?

图1.1
如上图所示;我们执行左侧的sql语句,如果我们,没有对col2建立右侧的索引数据结构,则该sql只能在表中,一行一行的检查,比对col2是不是等于99,其平均的时间复杂度就是O(n),如果我们建立右侧的二叉搜索树,那么我们通过二叉搜索树就能在O(logn)的时间内,完成一次查找,每一个节点里面都存放着该内容所在的位置。如果我们针对col1建立二叉搜索树,很显然,二叉树会退化成链表的形式,依然是O(n)得时间复杂度,随时大量数据的出现,将很慢,如下图;
图1.2
这就是二叉搜索树作为索引的缺点和劣势。索引的数据结构是怎么建立的尼?是随着每次插入一条数据的时候,就会针对该数据不断地完善索引数据结构。既然有序二叉排序树不是平衡地二叉树,如果我们采用红黑树(二叉平衡树)地话,是不是就可以解决这个问题了尼?我们看下图1.3
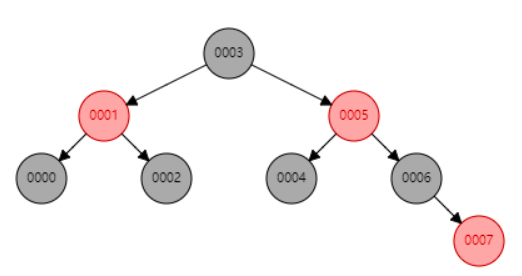
图1.3
由于红黑树的自平衡特性,虽然输入数据都是有序地,但是最终形成也是相对平衡地二叉树。红黑树保证任意一个节点地左右两边的高度小于等于1。似乎可以解决不平衡带来的问题。但是在数据库索引中,依然没有采用红黑树的原因尼?很显然有部分应用场景红黑树还是步合适的,虽然红黑树是平衡的二叉树,但是由于每一个节点处,只存放了一行数据,所以,当数据较多的时候,红黑树的高度依然会很高,所以依然不会采用红黑树!!!下面讲解一种更合适的数据结构。
2:B+树
如下图2.1所示,就是一个B树(多路平衡搜索树)。每一个节点处存放多行元素,这样就可以增加横向的,降低高度,较少磁盘IO操作。
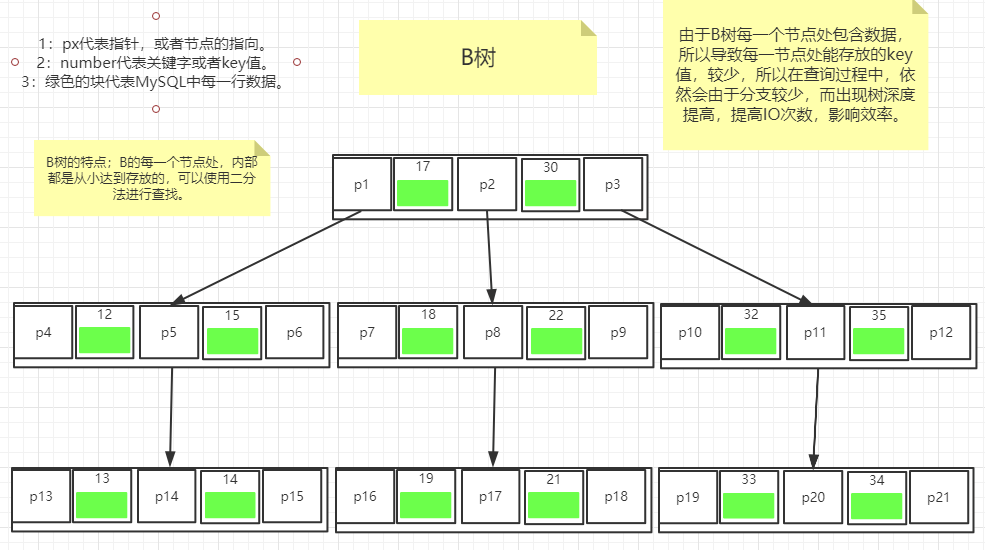
图2.1
但是由于B树的非叶子节点中依然存放部分数据,所以导致每一个节点的索引量依然不是很大,所以MySQL中对B树设升级为B+树,如下图2.2所示
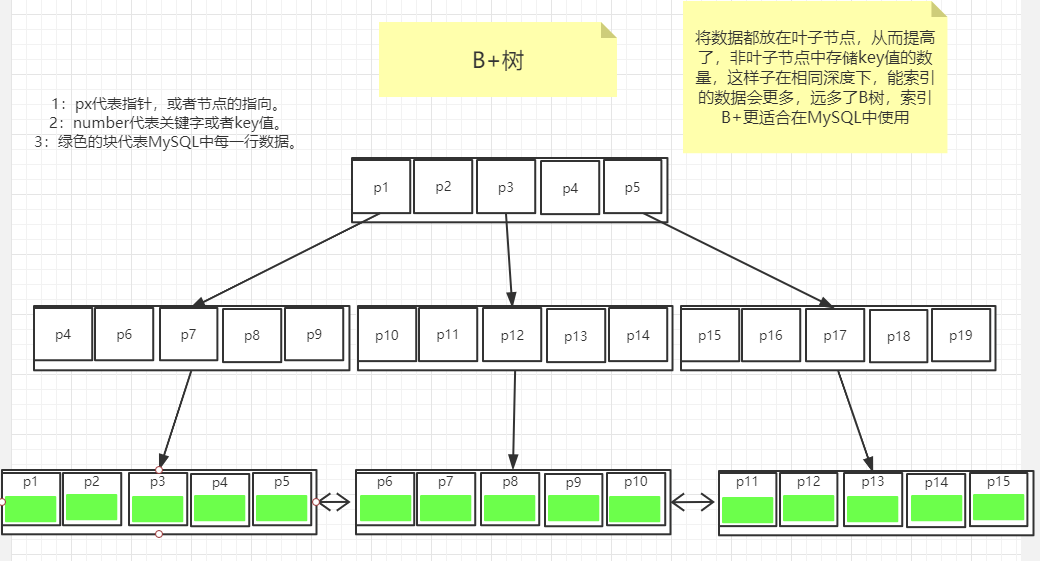
图2.2
将非叶子节点中只存放索引,不存放数据,所以使得非叶子节点处能够尽量存放更多的索引,使得树的高度不会很高!这里的数据是指-该索引对应的行在磁盘的指针。同时上图中B+树有一个问题就是不同底层区间之间要用指针从左向右的相连(双向指针),提高访问速度!!!
下面针对MySQL中的特性,简单分析一下高度为3的B+树,大概可以存放多少条记录?我们使用下面语句,可以知道Innodb中一个节点的大小为大概16KB。
SHOW GLOBAL STATUS LIKE 'Innodb_page_size';
那我们,假定每一个索引大小为8B,每一个指向下一个节点的指针为6B,那么在非叶子节点的每一个索引和指针都是成对出现的,所以大概每一个节点可以存放16KB/(8B+6B) = 1170个,即第一层的节点可以存放1170个指向下一层的指针,那第二层的指针个数尼?1170*1170 = 1368900个,第三层为叶子节点,其存放索引和数据,假设一个索引和数据的大小在一起为1KB,那么第三层为每一个节点处16个数据。所以该三层B+共可以索引到1170*1170*16条记录,为21902400个,大概2千万!也即是说2千万条记录,只需要一个3层的B+树就可以进行索引了。
3:Myisam存储引擎的特点
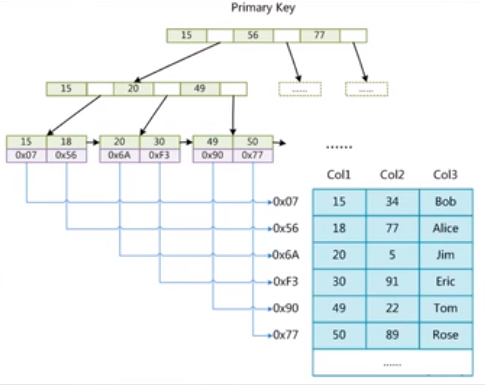
图3.1
我们观察Myisam存储引擎的文件,会发现有3个文件分别是.MYF,.MYI和.MYD三个文件(非聚合)分别是Myisam的数据格式框图文件,Myisam的索引文件以及Myisam的数据文件。我们以一条sql语句为例来分析。
select t.* from table t #假设col1列是建立索引的 where t.col1 = 99;
上图语句,由于我们筛选条件col1是建立索引的了,所以会搜索在MYI文件里开始索引col1,按照B+树进行索引,找到对应数据的磁盘指地址后,在从MYD文件中将数据load进来,即Myisam索引中存放的是相应数据的磁盘地址!
4:Innodb存储引擎的特点
- 表数据文件本身就是一个B+树组织的索结构文件
- 索引中叶子节点包含完整的数据记录
- 为什么Innodb必须有用主键,并且推荐使用整形的自增当作索引?
- Innodb表,如果没有认为建立主键,则软件会找一列没有重复数据的列作为主键列,建立B+树的索引结构。如果没有不重复的列,则MySQL会自动维护一列新的不重复列作为主键。
- 整形?因为在索引的过程中,要进行很多次比较和判断,整形的比较显然比字符型的要快呀。同时所在空间也小很多。
- 自增?我们观察下图,发现如果索引是递增的,那么在范围查找的时候,就会很方便,在叶子节点处,所有数据都是递增的,只要索引处分界值的数据,通过下面的的节点之间的指针(双向的指针)就可以很方便进行范围查找。同时,还有一个原因,就是如果不是递增的主键索引,那么在插入新的记录的主键时B+树为了实现非叶子节点的递增顺序,很有可能做一次分裂和平衡调整,显然比递增的操作要慢很多。
- 为什么非主键索引结构中,叶子节点处存放的是主键值?
- 一致性和节省空间

图4.1
上图4.1就是Innodb存储引擎下的主键索引的结构,每一个叶子节点处都都对应者相应的记录,聚合的。而相比于Myisam,在Innodb中每一个叶子节点处存放的就是对应行中数据记录(Myisam中索引B+树叶子节点存放的是对应数据行所在的磁盘地址)!
