python爬虫简单上手
要导的一些包
import requests
import re
import bs4
from bs4 import BeautifulSoup
爬下来的数据写进csv还是写进数据库,相应的还要导一些别的包。
获取内容
url = '你的url'
r = requests.get(url)
# 如果你的url是网页的话
text = r.text
# 如果是音频、pdf之类的话
content = r.content
特殊情况
有可能直接这样是不行的,如果打印出来的网页源码和浏览器上看到的不一样的话,可以试试下面的办法:
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
}
# 冒号后面的内容需要自己在浏览器里找
r = requests.get(url,headers=headers)
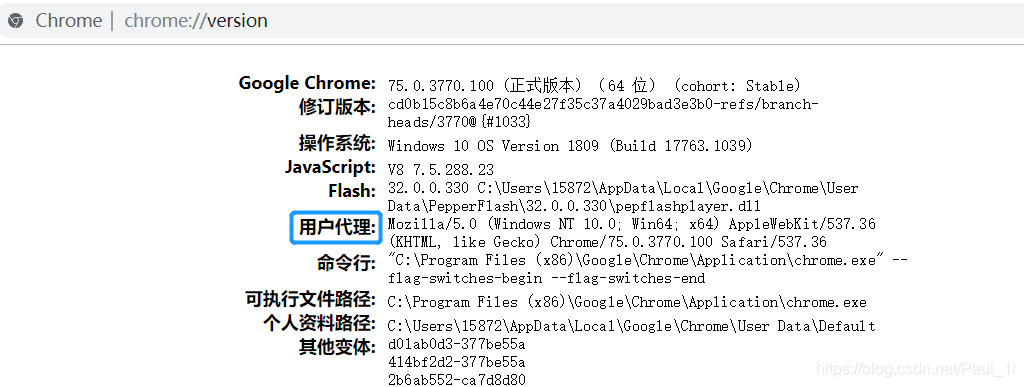
以Chrome为例,在地址栏输入chrome://version,找到用户代理,如下图:
BeautifulSoup
这个东西能帮你快速定位一些标签
soup = BeautifulSoup(text,'html.parser')
# find能找到一个标签,如果有很多的话就找第一个
a = soup.find(name = '标签名', attrs = {"属性名":"属性值"})
# 如果属性是class的话,还可以写成
a = soup.find(name = '标签名', class_ = '类名')
# 这个东西不是完全的匹配的,比如<div class="aa"></div>和<div class="a"></div>
a = soup.find('div', class_ = 'a')# 也会匹配到前面那个
# find_all能找到很多标签,返回一个列表
a = soup.find_all(name = '标签名', attrs = {"属性名":"属性值"})
# 获取标签的子标签
child = p.children
# 获取标签中的文本
txt = p.get_text()
已知首尾字符串,取中间的字符串
# 这个方法很方便,返回的是一个列表,正则匹配
def GetMiddleStr(content,startStr,endStr):
patternStr = r'%s(.+?)%s'%(startStr,endStr)
p = re.findall(patternStr,content)
return p
# 比如如下字符串要取出bbbbb
str1 = 'aabbbbbcc'
str2 = GetMiddlestr(str1,'aa','cc')
