第十章 序列建模:循环和递归网络
2020-2-21 深度学习笔记10 - 序列建模:循环和递归网络 1(展开计算图,循环神经网络–经典 / 导师驱动 / 唯一单向量输出 / 基于上下文RNN建模)
2020-2-23 深度学习笔记10 - 序列建模:循环和递归网络 2(双向RNN,基于编码 - 解码的序列到序列结构–不等长输出序列,计算循环神经网络的梯度)
2020-2-24 深度学习笔记10 - 序列建模:循环和递归网络 3(深度循环网络,递归神经网络,长期依赖的挑战,回声状态网络ESN)
2020-2-25 深度学习笔记10 - 序列建模:循环和递归网络 4(渗漏单元和其他多时间尺度的策略,长短期记忆和其他门控RNN)
优化长期依赖
我们已经了解在许多时间步上优化RNN时发生的梯度消失和爆炸的问题。
而二阶导数可能在一阶导数消失的同时消失。二阶优化算法可以大致被理解为将一阶导数除以二阶导数(在更高维数,由梯度乘以Hessian 的逆)。如果二阶导数与一阶导数以类似的速率收缩,那么一阶和二阶导数的比率可保持相对恒定。
当然二阶方法也有许多缺点,包括高的计算成本、需要一个大的小批量、并且倾向于被吸引到鞍点。
所以说机器学习中,设计一个易于优化模型通常比设计出更加强大的优化算法更容易。
1-截断梯度
强非线性函数(如由许多时间步计算的循环网络)往往倾向于非常大或非常小幅度的梯度。 如下图所示,我们可以看到,目标函数(作为参数的函数)存在一个伴随”悬崖”的”地形”:宽且相当平坦区域被目标函数变化快的小区域隔开,形成了一种悬崖。

一个简单的解决方案已被从业者使用多年:截断梯度。
- 一种选择是在参数更新之前,逐元素地截断小批量产生的参数梯度。
- 另一种是在参数更新之前截断梯度g的范数||g||:
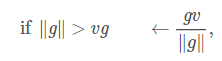
其中v是范数上界,g用来更新参数。 因为所有参数(包括不同的参数组,如权重和偏置)的梯度被单个缩放因子联合重整化,所以后一方法具有的优点是保证了每个步骤仍然是在梯度方向上的,但实验表明两种形式类似。
2-引导信息流的正则化
正则化或约束参数,以引导”信息流”。 特别是即使损失函数只对序列尾部的输出作惩罚,我们也希望梯度向量
在反向传播时能维持其幅度:

外显记忆
神经网络擅长存储隐性知识,但是他们很难记住事实。被存储在神经网络参数中之前,随机梯度下降需要多次提供相同的输入,即使如此,该输入也不会被特别精确地存储。
Graves推测这是因为神经网络缺乏工作存储(working memory)系统,即类似人类为实现一些目标而明确保存和操作相关信息片段的系统。 这种外显记忆组件将使我们的系统不仅能够快速”故意”地存储和检索具体的事实,也能利用他们循序推论。 神经网络处理序列信息的需要,改变了每个步骤向网络注入输入的方式,长期以来推理能力被认为是重要的,而不是对输入做出自动的、直观的反应 。
为了解决这一难题,Weston引入了记忆网络,其中包括一组可以通过寻址机制来访问的记忆单元。 记忆网络原本需要监督信号指示他们如何使用自己的记忆单元。 Graves引入的神经网络图灵机,不需要明确的监督指示采取哪些行动而能学习从记忆单元读写任意内容,并通过使用基于内容的软注意机制,允许端到端的训练。 这种软寻址机制已成为其他允许基于梯度优化的模拟算法机制的相关架构的标准。

