随着 Echo 出现,all in one 音响类产品雏形开始显现,语音交互成为最直接的控制方式,Amazon Echo作为最佳代表,智能语音交互成为互联网入口的新价值所在。ABI Research 在 2017 年収布的预测报告指出,估计到 2022 年,支持语音控制的装置出货量将达到 7500万台,其中智能喇叭/数位语音助理预计达到 4700 万台,预计智能音箱销售量将会逐步上升,未来三年内还将保持 50%以上的复合增速。2017 年 ,Echo 系列产品销售量超过 1000 万台,销售额达到 8~10 亿美元;伴随着智能音箱的火热以及背后语音交互生态的成熟,将会带动越来越多的设备语音化、智能化,使语音真正成为人机交互的一个界面。而在语音交互设备中,语音唤醒技术越发显得重要,成为人与设备“沟通”的桥梁。
首先,什么是语音唤醒?
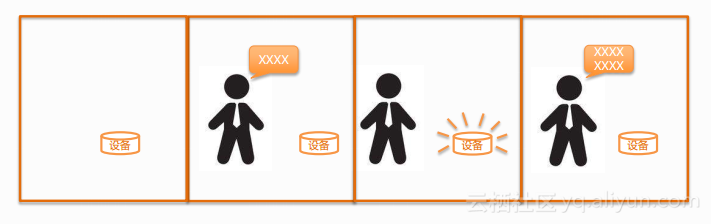
语音唤醒,有时也称为关键词检测(Keyword spotting),也就是在连续不断的语音中将目标关键词检测出来,一般目标关键词的个数比较少(1~2个居多,特殊情况也可以扩展到更多的几个)。
语音唤醒和语音识别的区别:语音识别只能处理一段一段的语音数据,也就是待识别的语音有明确的开始和结束,比如siri按下home键,开始录音说话,松开录音结束,返回识别结果;语音唤醒是处理连续不断的语音流,比如语音开关24小时不间断的检测麦克录音中的关键词信息;语音唤醒可以和语音识别技术结合,用于检测语音开始的位置,替换掉按键,比如Amazon Echo中,用”alexa”作为唤醒词,一旦检测到唤醒词,则开始录音进行语音识别。
语音唤醒性能:
唤醒率:将连续语流中存在的唤醒词检测出来,这个和语音识别的识别率有一定的相似性
误唤醒率:连续语音中不存在唤醒词,但是将一些其他语音误判为唤醒关键词
常用的实现方式:dnn+hmm(深度神经网络+隐马尔科夫模型),lstm+ctc(长短时记忆网络+全连接时序分类模型)
目前业界软件唤醒方案,也即提供SDK,实现唤醒功能一般分为在线和离线版本。国内主要以科大讯飞与百度为代表。唤醒率总体超过95%(这个只能参考,具体看测试场景)。网上也有多种开源的小型语音识别引擎,可以实现单独的语音唤醒功能,性能参差不齐。
简单说明各算法优缺点
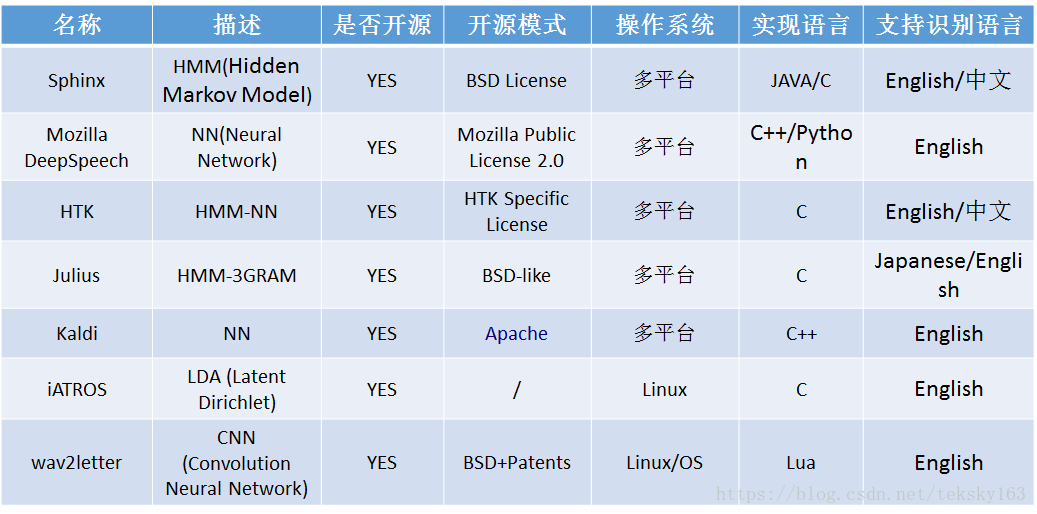
Sphinx
优点
前端结构模块化较好。包括实现预加重、加窗、FFT、Mel频率滤波器、离散余弦变换、MFCC特征提取
通用的声学模型结构
适合嵌入到Android、ARM平台
操作文档具有很好的可读性,易于学习,贴近实践操作
缺点
采用传统的HMM-GMM框架,对其原理的学习及掌握具有一定的难度Mozilla DeepSpeech
优点
该模型的准确性接近人类在听同样的录音时的感知
Mozilla还发布了世界上第二大公开的语音数据集,这是全球近2万名用户的贡献
缺点
语音数据主要集中在英文语言,还缺乏多种语音数据集的支持
男性语音数据暂时多于女性语音数据HTK
优点
代码历史悠久、稳定、高效
操作文档HTKBOOK全面
模型训练工具齐全
缺点
采用传统的HMM框架,对其原理的学习及掌握具有一定的难度
模型训练的预处理的部分工作繁琐易出错
Julius
优点
支持神经网络建模
最新的版本采用模块化的设计思想,使得各功能模块可以通过参数配置
缺点
文档以日文居多
神经网络中的优化trick较多,较多地依赖于经验Kaldi
优点
加入了对神经网络的支持
维护更新及时
学术界、工业界活跃度高,是目前主流的语音识别研发工具
缺点
通过公共接口的设计让不同的工具容易协作,但是增加了对脚本及算法的理解难度
神经网络中的优化较多,调参较多地依赖于经验
iATROS
优点
适用于语音和手写文字识别的实现
提供了一个模块化的结构,可以用来建立不同的系统,其核心是一个类维特比在Hidden Markov模型的网络搜索
提供离线识别和在线语音识别标准工具(基于ALSA模块)
缺点
网络复杂度较高,识别速度略慢Wav2letter
优点
简单高效的端到端自动语音识别(ASR)系统,结合了基于卷积网络的声学模型和图解码
其被训练输出文字,转录语音,而无需强制对齐音素
引入了一个自动的序列标注训练分割准则,而不需要与CTC一致的对齐方式
缺点
目前只能识别英文语音了解更多信息 可关注微信公众号Deverloper_Taoists