前言
Redis是一个支持持久化的内存数据库,通过持久化可以把在内存中的数据同步到硬盘上,来保证数据的持久化,当Redis在重启时候,可以通过加载硬盘文件重新加载数据到内存中,达到数据恢复的目的。
Redis提供了两种持久化的方法:RDB与AOF
RDB:
是Redis默认的持久化方法,按照一定的时间周期策略把位于内存中的数据保存为RDB文件(是一个二进制的文件)有两个命令可以进行RDB文件的生成:sava 和BGsave。
在执行save命令时候会阻塞Redis服务器进程,在执行过程中,Redis服务器不能够处理任何其他的请求。但是BGsave不同的是,在执行时候会派生出一个子进程由子进程完成RDB文件的创建,服务器父进程继续完成其他的响应。
执行时候状态:在BGSAVE命令执行期间,客户端发送的SAVE命令会被服务器拒绝,服务器禁止SAVE命令和BGSAVE命令同时执行是为了避免父进程(服务器进程)和子进程同时执行两个rdbSave调用,防止产生竞争条件。
其次,在BGSAVE命令执行期间,客户端发送的BGSAVE命令会被服务器拒绝,因为同时执行两个BGSAVE命令也会产生竞争条件。最后,BGREWRITEAOF和BGSAVE两个命令不能同时执行:
❑如果BGSAVE命令正在执行,那么客户端发送的BGREWRITEAOF命令会被延迟到BGSAVE命令执行完毕之后执行。
❑如果BGREWRITEAOF命令正在执行,那么客户端发送的BGSAVE命令会被服务器拒绝。因为BGREWRITEAOF和BGSAVE两个命令的实际工作都由子进程执行,所以这两个命令在操作方面并没有什么冲突的地方,不能同时执行它们只是一个性能方面的考虑——并发出两个子进程,并且这两个子进程都同时执行大量的磁盘写入操作,导致的问题也是显而易见的。
在讲述完了大体的模型以后下面来看看具体的小细节部分。
自动间隔性保存
前面介绍到了SAVE命令和BGSAVE的实现方法,并且说明了这两个命令在实现方面的主要区别:SAVE命令由服务器进程执行保存工作,BGSAVE命令则由子进程执行保存工作,所以SAVE命令会阻塞服务器,而BGSAVE命令则不会。因为BGSAVE命令可以在不阻塞服务器进程的情况下执行,所以Redis允许用户通过设置服务器配置的save选项,让服务器每隔一段时间自动执行一次BGSAVE命令。用户可以通过save选项设置多个保存条件,但只要其中任意一个条件被满足,服务器就会执行BGSAVE命令。举个例子,如果我们向服务器提供以下配置:
save 900 1
save 300 10
save 30 10000
以上的条件表示:
❑服务器在900秒之内,对数据库进行了至少1次修改。
❑服务器在300秒之内,对数据库进行了至少10次修改。
❑服务器在60秒之内,对数据库进行了至少10000次修改。
只要有任意一个条件被满足,服务器就会执行BGSAVE命令。
设置保存的条件
当Redis服务器启动时,用户可以通过指定配置文件或者传入启动参数的方式设置save选项,如果用户没有主动设置save选项,那么服务器会为save选项设置默认条件:
save 900 1
save 300 10
save 30 10000
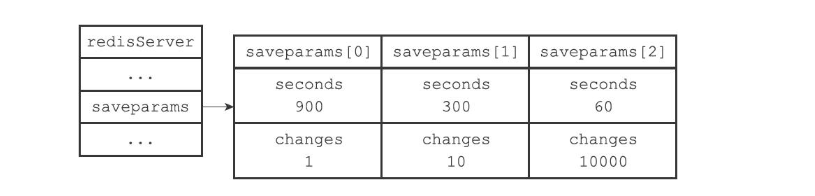
接着,服务器程序会根据save选项所设置的保存条件,设置服务器状态redisServer结构的saveparams属性:
struct redisServer{
struct saveparm * saveparams;
} ;
saveparams属性是一个数组,数组中的每个元素都是一个saveparam结构,每个saveparam结构都保存了一个save选项设置的保存条件:
struct saveparam{
//秒数
time_t seconds;
// 修改数
int changes;
};
这个是时候 若是以下面的选项作为条件时候
save 900 1
save 300 10
save 30 10000
数据库就会是如下图所示样子:
RDB总结:
❑RDB文件用于保存和还原Redis服务器所有数据库中的所有键值对数据。
❑SAVE命令由服务器进程直接执行保存操作,所以该命令会阻塞服务器。
❑BGSAVE令由子进程执行保存操作,所以该命令不会阻塞服务器。
❑服务器状态中会保存所有用save选项设置的保存条件,当任意一个保存条件被满足时,服务器会自动执行BGSAVE命令。
❑RDB文件是一个经过压缩的二进制文件,由多个部分组成。
❑对于不同类型的键值对,RDB文件会使用不同的方式来保存它们。
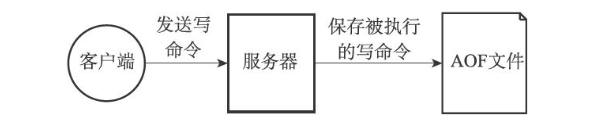
AOF
AOF持久化是通过保存redis服务器所指向的写命令来记录数据库状态。通过Write函数追加到文件的最后。如下图所示:
举个栗子:
redis> SET mes "hello"
OK
redis> SADD fruits "apple" "banana" "cherry"
(integer) 3
redis> RPUSH numbers 123 456 789
(integer) 3
RDB持久化保存数据库状态的方法是将msg、fruits、numbers三个键的键值对保存到RDB文件中,而AOF持久化保存数据库状态的方法则是将服务器执行的SET、SADD、RPUSH三个命令保存到AOF文件中。被写入AOF文件的所有命令都是以Redis的命令请求协议格式保存的,因为Redis的命令请求协议是纯文本格式,所以我们可以直接打开一个AOF文件,观察里面的内容。
AOF持久化的实现;
AOF持久化功能的实现可以分为命令追加(append)、文件写入、
文件同步(sync) 三个步骤。
命令追加
当AOF持久化功能处于打开状态时,服务器在执行完一个写命令之后,会以协议格式将被执行的写命令追加到服务器状态的aof_buf缓冲区的末尾:
struct redisServer{
//AOF 缓冲区
sds aof_buf;
}
举个栗子
redis> SET KEY VALUE;
OK
那么服务器在执行这个SET命令之后,会将以下协议内容追加到aof_buf缓冲区的末尾:
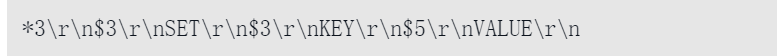
再度执行相同的操作,就会继续进行对应的追加
AOF文件的写入与同步
Redis的服务器进程就是一个事件循环(loop),这个循环中的文件事件负责接收客户端的命令请求,以及向客户端发送命令回复,而时间事件则负责执行像serverCron函数这样需要定时运行的函数。
因为服务器在处理文件事件时可能会执行写命令,使得一些内容被追加到aof_buf缓冲区里面,所以在服务器每次结束一个事件循环之前,它都会调用flushAppendOnlyFile函数,考虑是否需要将aof_buf缓冲区中的内容写入和保存到AOF文件里面
flushAppendOnlyFile函数的行为由服务器配置的appendfsync选项的值来决定,各个不同值产生的行为如表所示:
| appendsync选项的值 | flushAppendOnlyFile函数的行为 |
|---|---|
| always | 将aof_buf 缓存区中的所有内容都同步到AOF文件里面 |
| everysec | 将AOf_buf缓冲区中的所有内容都写入到AOF文件,如果上次同步AOF文件的时间 距离现在超过一秒钟,那么再次对AOF文件进行同步,并且这个同步操作是由一个线程专门负责执行的 |
| no | j将AOF_BUF缓冲区中的所有的内容都写入到AOF文件,但并不对AOF文件进行同步,何时同步由操作系统来决定 |
注意:如果用户没有主动为appendfsync选项设置值,那么appendfsync选项的默认值为everysec
为了提高文件的写入效率,在现代操作系统中,当用户调用write函数,将一些数据写入到文件的时候,操作系统通常会将写入数据暂时保存在一个内存缓冲区里面,等到缓冲区的空间被填满、或者超过了指定的时限之后,才真正地将缓冲区中的数据写入到磁盘里面。这种做法虽然提高了效率,但也为写入数据带来了安全问题,因为如果计算机发生停机,那么保存在内存缓冲区里面的写入数据将会丢失。
为此,系统提供了fsync和fdatasync两个同步函数,它们可以强制让操作系统立即将缓冲区中的数据写入到硬盘里面,从而确保写入数据的安全性。
AOF持久化的效率和安全性
服务器配置appendfsync选项的值直接决定AOF持久化功能的效率和安全性。
□ 当appendfsync的值为always时,服务器在每个事件循环都要将aof_buf缓冲区中的所有内容写入到AOF文件,并且同步AOF文件,所以always的效率是appendfsync选项三个值当中最慢的一个,但从安全性来说,always也是最安全的,因为即使出现故障停机,AOF持久化也只会丢失一个事件循环中所产生的命令数据。
□ 当appendfsync的值为everysec时,服务器在每个事件循环都要将aof_buf缓冲区中的所有内容写入到AOF文件,并且每隔一秒就要在子线程中对AOF文件进行一次同步。从效率上来讲,everysec模式足够快,并且就算出现故障停机,数据库也只丢失一秒钟的命令数据。
□ 当appendfsync的值为no时,服务器在每个事件循环都要将aof_buf缓冲区中的所有内容写入到AOF文件,至于何时对AOF文件进行同步,则由操作系统控制。
因为处于no模式下的flushAppendOnlyFile调用无须执行同步操作,所以该模式下的AOF文件写入速度总是最快的,不过因为这种模式会在系统缓存中积累一段时间的写入数据,所以该模式的单次同步时长通常是三种模式中时间最长的。从平摊操作的角度来看,no模式和everysec模式的效率类似,当出现故障停机时,使用no模式的服务器将丢失上次同步AOF文件之后的所有写命令数据。
以上就是AOF进行持久化的全部过程,下面来进行一个完整的回顾
重点回顾
❑AOF文件通过保存所有修改数据库的写命令请求来记录服务器的数据库状态。
❑AOF文件中的所有命令都以Redis命令请求协议的格式保存。
❑命令请求会先保存到AOF缓冲区里面,之后再定期写入并同步到AOF文件。
❑appendfsync选项的不同值对AOF持久化功能的安全性以及Redis服务器的性能有很大的影响。
❑服务器只要载入并重新执行保存在AOF文件中的命令,就可以还原数据库本来的状态。
❑AOF重写可以产生一个新的AOF文件,这个新的AOF文件和原有的AOF文件所保存的数据库状态一样,但体积更小。
❑AOF重写是一个有歧义的名字,该功能是通过读取数据库中的键值对来实现的,程序无须对现有AOF文件进行任何读入、分析或者写入操作。
当两个同时开启时候,优先选择AOF进行数据库的恢复。对于 AOF来说是追加的方式,所以没有磁盘的寻址开销 会更快,像 mysql中 binlog
各自的优点与缺点:
RDB
优点:对于 RDB的优点来说,前面讲到了 会生成数据文件,每个数据文件分别都代表了某一个时刻 reids里面的数据,这样的情况很适合做冷备,完整的数据运维设置定时的任务 定时同步到远端的服务器中 若是出现了宕机,就可以恢复几分钟之前的数据,使用 BGsave来说 可以fork一个子进行来做持久化 在数据恢复的时候 比AOF来得快。
缺点:
1.是RDB是生产快照文件的 五分钟会生成一个快照文件,但是若是在这五分钟内出现了故障就会导致 数据的丢失会丢失五分钟之内的数据, 对于 AOF来说 最多 丢失一秒的数据
2. 在生成数据快照的时候 如果文件很大 ,客户端可能会暂停执行几毫秒 此时若是正好在做秒杀活动的时候 fork一个子进程去生成一个大的快照 就会出现问题。
AOF
对于 RDB来说 是五分钟生成的一次快照 但是 AOF 是一秒一次去通过一个后台的线程 sync 操作 最多丢失一秒的数据。
AOF在对日志文件进行操作的时候 是以 append-only 来去写入得 只是追加的方式写入数据,自然就少了很多磁盘的寻址开销 写入性能惊人 文件 也不容易被损坏。
注意:
AOF的日志是通过一个叫非常可读的方式记录的,这样的特性就适合做灾难性数据误删除的紧急恢复了,比如公司的实习生通过flushall清空了所有的数据,只要这个时候后台重写还没发生,你马上拷贝一份AOF日志文件,把最后一条flushall命令删了就完事了。
缺点: 一样的数据 时候 AOF 文件比 RDB 还要大,在AOF开启以后 Reids 支持写入的 APS会比 RDB支持下的要低 异步刷新一次日志 fsync 。
