缘起
回归这个问题最先接触的时候是在高中,在高中讲了什么关于回归问题的,我们先回顾一下。
··首先先引入了一些单变量的,标量的期望方差等一些概念用来刻画一些统计量。
··随后引入了散点图,也就是给定一组(x,y),用作图的方法来在图上标出一系列的点。然后如果这些点的组合大约是一条直线的话,就说这些点满足y=ax+b这样的一个关系。
··然后称这种分析为一元线性回归分析。然后根据提供的数据,去求出参数a,b 。这样面对符合这个规律的x,我们都可以求出一个相应的y,这个y接近真实值。
··如何确定这个a,b呢?
··伟大的数学家们已经给我们指明了道路。首先想想我们的目的是啥?我们首先确定的是,这些点之间有某种关系,使得他们近似满足这样一条直线,又因为我们不知道的原因(其他变量等等原因),然后导致他们不完全满足这个函数。所以我们的目的是尽量减少其他因素的干扰,还原其本身的这个方程。所以我们定义一个量,用这个量来辨别我们这个函数的拟合(使我们生成的函数,更符合这个函数本身)效果,这个量数学家们称它为平方和误差,说人话就是c=y1^2 +y2^2 +…+yn^2但是他经常被写成这种形式,c=Σ yi^2 。从我们的直觉上来说,这应该是一种多数点的民主,就是这个量越小的话,就会使得更多的点接近我们的直线。我们的拟合效果就越好。

··我们高中并没有学习偏导数这一概念,所以我们妥协的使用如下方法来求a和b
这种方法的原理和优缺点就不再赘述。
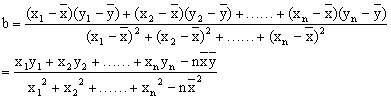
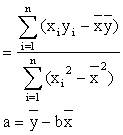
进阶
偏导
··先从确定a,b说起。我们高中没学过偏导数等概念所以采用了一种比较简陋的方式去求出参数,现在我们引进偏导数去求解。
首先先写出上述我们用来确定拟合效果的函数损失函数
loss=Σ(wxi+b-yi)^2
我们想要使得loss达到最小,然后确定此时w和b的值。确定w和b的时候我们是知道一部分x和y的,这就是我们的样本数据。如何使得loss最小呢?学过导数的就知道,这是一个二元函数,我们用loss分别对w和b求偏导使得两个偏导数为0,这样的话,此时的w和b我们就可以确定了
∂ loss/∂ w=2x(wxi+b-yi)
∂ loss/∂ b=2(wxi+b-yi)
我们让这两个偏导数等于0从而解出来w和b就行了
··而有的时候我们可能并不是单变量的x,我们可能有多个x,就比如典型的回归分析的案例,波士顿房价一样。
····所以我们的公式变一下,变成 y=w1x1+w2x2+……+wnxn+b,这种的我们可以用向量的观点简化一下(w1,w2,w3,…,wn,b)(x1,x2,x3,…xn)这种写法一方面是写起来简单,一方面是因为计算机擅长进性向量内积的运算。
····如果我们有多个变量来求的话,假设我们有20个因素印象也就是有20个x,在加上一个b的话,那一共就要有21个待求参数,如果我们想求解参数的话,我们必须最少有21个上述的偏导等于0的方程,与此同时最少有21个样本。我们可以知道如果要进行图像的某种预测的话,图像一般都是rgb三个维度,每个维度就算是64*64的,那么我们就有几百个参数要进性求解。如果单纯依靠求导的话,人是很辛苦的,如果依靠计算机的话,但是计算机并不擅长解方程。那该怎么办,伟大的数学家再一次站了出来,提出了梯度下降的方法,来避免求导,从而算出参数。
梯度下降法
··梯度下降法的思想不是很难,自然界中有一种现象,叫做水往低处流,然后梯度下降的方法也是差不多。假设在曲面上任意去一个点,那么我们在在其周围找一个微小距离,这样我们就可以得到这个点周围各个方向的变化率了,也就是我们知道沿那个方向可以更快速的接近最低点。那么梯度下降法就是我先有个初始位置,一般采用标准高斯分布或者0来为初始值。然后算这个初始位置的周围的导数,然后选择梯度方向,到达新的位置之后在重复上述运算。这样就可以找出该函数的最低点了。

下面是公式上的推导
我们假设有个二元函数z=f(x,y)
当x变化Δx,y变换Δy
下面是公式上的推导
我们假设有个二元函数z=f(x,y)
当x变化Δx,y变换Δy的时候 那么z就变化Δz
现在做一个推导
f’(x)=limΔx->0(f(x+Δx)-f(x))/Δx
因为根据我们的思路Δx和Δy都是一个微小量 那么lim就可以去掉
f‘(x)=(f(x+Δx)-f(x))/Δx
上面这个公式就近似成立
所以
f(x+Δx)=f’(x)Δx+f(x)
上述就是近似公式的推导
那么对于二元函数来说应该是这样的
f(x+Δx,y+Δy)=f(x,y)+∂f(x,y)*Δx/∂x+∂f(x,y)Δy/∂y
Δz=f(x+Δx,y+Δy)-f(x,y)
Δz=∂f(x,y)Δx/∂x+∂f(x,y)Δy/∂y
那么对于多变量的近似公式来讲
Δz=∂zΔx/∂x+∂zΔy/∂y+∂zΔw/∂w+……
然后这个式子有可以写成向量的形式
▽(∂z/∂w,∂z/∂x,∂z/∂y) 和 Δg(Δw,Δx,Δy)
然后让我们在回顾一下向量的知识
我们知道对于平面内的两个向量,当夹角为180的时候,ab的内积最小,
也就是满足
a=-kb
那么对于两个向量
▽(∂z/∂w,∂z/∂x,∂z/∂y)
Δg(Δw,Δx,Δy)来说
当-k▽(∂z/∂w,∂z/∂x,∂z/∂y)=Δg(Δw,Δx,Δy)的时候Δz达到最小。
其实当角度等于180和0都会使ab的内积的绝对值达到最大,那么我们的Δz应该沿那个方向走呢?我们的目的是使得偏导数等于0,那么我们应该沿着减小最大的方向走,也就是-k的方向,那么0度的方式又是啥,其实这个就是梯度方向,我们的Δz沿着的是梯度反方向走的。
··上面我们说的微小位移,就是Δx,和Δy。根据上面公式我们知道,他们就等于-k▽(∂z/∂w,∂z/∂x,∂z/∂y)这个东西。所以我们成这个k叫做学习率
如果这个学习率过大,那么可能会出现,越过最小值的问题,如果这个学习率比较小则可能出现到不了最小值的问题

解决方案的话,好像还没有明确的标准,只能通过反复实验
上述就是回归问题的基本分析了,下一节是numpy实现这个回归问题的求解。
