文章目录
引言
这将会是一个不断更新的博客,提供了一些数据集下载来源或者数据集信息介绍。在我的研究中,我可能会碰到一些相关任务的数据集,在此做个记录,顺便分享给大家。
一、实体、关系抽取相关的数据集
1. CoNLL
1.1 CoNLL 介绍
CoNLL: The SIGNLL Conference on Computational Natural Language Learning。具体的解释可以参见这里 或者这里
其中,SIGNLL : ACL’s Special Interest Group on Natural Language Learning。具体的解释可以参见这里.
CoNLL从1999年开始,每年都会发布一个公开评测任务,它们会提供任务数据,因此,这里我们需要的就是它们公开的数据集,用来评测我们自己的一些相关模型或者算法。
CoNLL每年的公开任务如下图所示,可以参见这里。
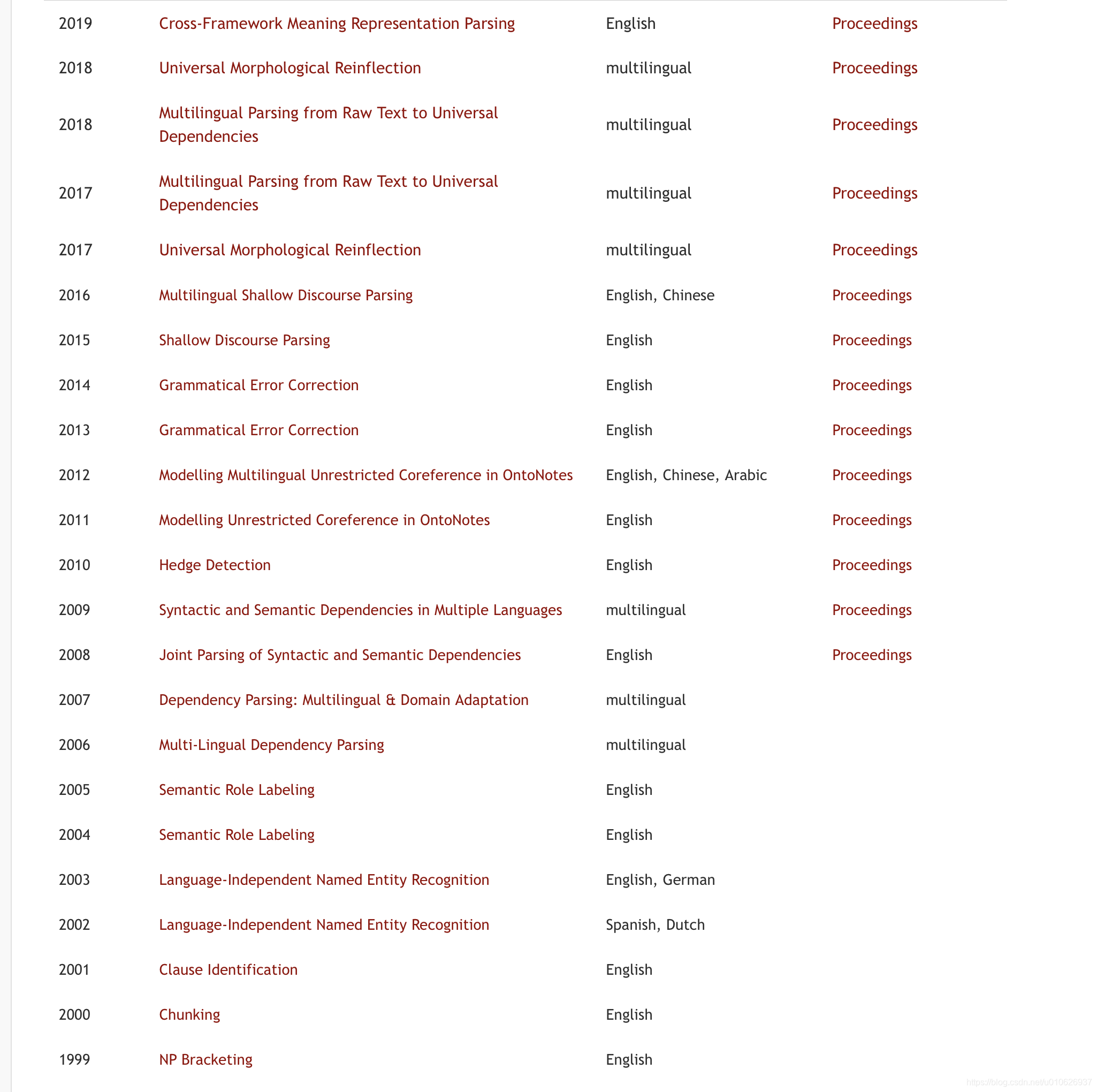
我们以[CoNLL 2012] Modeling Multilingual Unrestricted Coreference in OntoNotes为例,很明显,这里需要依赖数据集OntoNotes(目前的版本为 OntoNotes releases 5.0,其获取方式参见下面介绍),也可以说是原始的数据集,所谓的CoNLL数据集就是将OntoNotes数据集通过相应的程序转换成CoNLL任务所需的格式(一般称之为CoNLL格式)。具体的可参见这里这里。
我们截图(转换过程的一部分),看一下。

通过上图可以看出,需要先下载Ontonotes数据集。下一部分以OntoNotes releases 5.0为例。
1.2 OntoNotes releases 5.0 数据集下载
其获取方式还是比较麻烦的,同时也比较严谨,毕竟是科研数据,具有访问和共享权限,尽量要严格遵守,不然触碰到侵权就不好了。该数据集需要从LDC(语言数据联盟)OntoNotes Releases 5.0 LDC上获取,关于获取方法可以参见这里或者这里。是需要注册以及组织授权的。
1.3 获取CoNLL相关的数据集
获取到OntoNotes 5.0数据集之后,再获取下列与CoNLL相关的数据集。
- conll-2012-train.v4.tar.gz
- conll-2012-development.v4.tar.gz
- conll-2012-test-key.tar.gz
- conll-2012-test-official.v9.tar.gz
- conll-2012-scripts.v3.tar.gz
- reference-coreference-scorers.v8.01.tar.gz
1.4 OntoNotes 数据集转换成conll格式
将所需的材料获取到以后,就可以按照这里步骤进行格式转换即可(将CoNLL triain/development 文件中的skel数据转换为conll)。或者按照如下步骤进行转换(实际上,这两种转换方法都是一样的,只不过后者将一些步骤通过脚本语言给集成了)。
转换脚本为(拷贝以下代码,保存为data_setup.sh):
#!/bin/bash
dlx() {
tar -xvzf $1
rm $1
}
#conll_url=http://conll.cemantix.org/2012/download
dlx conll-2012-train.v4.tar.gz
dlx conll-2012-development.v4.tar.gz
dlx conll-2012-test-key.tar.gz
dlx conll-2012-test-official.v9.tar.gz
dlx conll-2012-scripts.v3.tar.gz
dlx reference-coreference-scorers.v8.01.tar.gz
mv reference-coreference-scorers conll-2012/scorer
ontonotes_path=/Users/xuxiu/Downloads/e2e-coref-master/ontonotes-release-5.0
bash conll-2012/v3/scripts/skeleton2conll.sh -D $ontonotes_path/data/files/data conll-2012
#----------------------以上过程就是格式转换操作-------------------
#===========以下过程是对转换后的文件进行格式转换和预处理==========
#拷贝最终转换后的文件出来
function compile_partition() {
rm -f $2.$5.$3$4
cat conll-2012/$3/data/$1/data/$5/annotations/*/*/*/*.$3$4 >> $2.$5.$3$4
}
function compile_language() {
compile_partition development dev v4 _gold_conll $1
compile_partition train train v4 _gold_conll $1
compile_partition test test v4 _gold_conll $1
}
compile_language english#将English文件中转换后的文件,拷贝出来
#compile_language chinese#如果不需要转换中文语料,就注释掉
#compile_language arabic#如果不需要转换阿拉伯语料,就注释掉
python minimize.py#转换为易理解和易于读取的json文件格式
python get_char_vocab.py#得到词汇词典(charater 为单位),char_vocab.english.txt
#python filter_embeddings.py glove.840B.300d.txt train.english.jsonlines dev.english.jsonlines
#python cache_elmo.py train.english.jsonlines dev.english.jsonlines
从这里获取minimize.py 和 get_char_vocab.py 两个文件(注意,只需要获取这两个文件即可,其余的不用管)。然后执行:./data_setup.sh
说明:
1、在本代码示例中,我们只转换了English语料,如果你需要转换所有语言的语料集,那就将compile_language chinese这里给取消注释。
2、在执行./data_setup.sh的时候,可能会报错。有两点需要注意:
a、本脚本中涉及到的skeleton2conll.py (这个文件在你下载的conll-2012-scripts.v3.tar.gz这里会找到)代码为python2,所以如果用python3 执行的时候,会报错。因此,在这里修改skeleton2conll.sh 代码,将以下语句中的python改为python2(或者根据报错信息,修改代码也可以,不会太难。)
erun -v "python2 $d/v?/scripts/skeleton2conll.py $gold_parse $skel $conll $EDITED --text"将这里的python 改为python2(我这是修改之后的语句)
b、因为我注释掉了compile_language chinese和compile_language arabic 所以涉及到这两个语言的地方可能会报错,但是不会影响我的结果,可以忽略不见。
执行完毕之后会在同目录生成三个json文件数据:训练集-验证集-测试集(train、dev、test)。其中doc_key为文本分类名称,sentences为切分完毕的对话,speakers为句子发言者、clusters即指代文本短语的聚类结果(共指) 。英文语料的结果为:train.english.jsonlines、dev.english.jsonlines、test.english.jsonlines。示例数据如下:
{
"clusters": [],
"doc_key": "nw",
"sentences": [["This", "is", "the", "first", "sentence", "."], ["This", "is", "the", "second", "."]],
"speakers": [["spk1", "spk1", "spk1", "spk1", "spk1", "spk1"], ["spk2", "spk2", "spk2", "spk2", "spk2"]]
}
转换以前的数据格式如下所示(注意下文件名称,相应的格式匹配),

转换后的数据为:

通过对比上两图可以看出处理之前的红框单词都是mask掉的。
如果嫌麻烦可以从这里获取已经处理好的。
作用:该语料集可以用来评测:语义角色标注(Sematic Role Labeling)、coreference solution、命名体识别(NER)等任务模型。
2、 ACE
ACEAutomatic Content Extraction这也是一个公开评测项目,它们也提供了相应的数据集,请仔细阅学这个网页中的介绍,了解涉及到的任务以及数据说明。该数据同样是从LDC(语言数据联盟)上获取,不过不是免费的。例如ACE 2005。
关于ACE2005的数据集的理解可以参见这里和这里,还有这里。
作用:该语料集可以用来评测:实体抽取Entity Detection and Tracking (EDT) 、关系抽取Relation Detection and Characterization (RDC)、事件抽取Event Detection and Characterization (EDC)等任务模型。
关于ACE数据集处理的问题,可以参见这个资料,里面包含相应的处理部分。
目前的问题就是,还没有办法获取到ACE的数据集,如果你有好的资源的话,可以分享给我,留言给我哦,不胜感激。
二 、 文本摘要相关的数据集
TAC
TAC(Text Analysis Conference)也是一个在线评测任务,这里的数据集也是它们为了评测模型而公开的数据集。我们以TAC 2014为例,具体的信息可以参考这里。
TAC 2014 has seven tracks in two major areas:
- Summarization Track develops technologies that produce short, coherent summaries of text.
- Knowledge Base Population (KBP) Tracks develop technologies for building and populating knowledge bases (KBs) from unstructured text.
也就是说这个任务的公开数据集可以用来评测,摘要任务,知识图谱填充和建立的任务。具体的信息可以参见网页信息这里。
【未完待续。。。】
