主键生成策略
1.主键分类
自然主键
主键本身就是表中的一个字段,实体中一个具体的属性,对象本身唯一的特性。就比如说我们一个人有身份证号、姓名、性别等属性,其中身份证号是唯一的可以作为自然主键。
代理主键
主键本身不是表中必须的一个字段,我们使用系统自动增长,或者使用随机字符串等等方法额外设置的主键。开发当中我们一般都使用代理主键,这样可以方便以后我们对用户字段的修改。举个例子:比如说我们使用的自然主键(学号),假如我们在录入学生数据的时候将两个学生的学号录反了,这样我们便想要去修改学生的信息便十分的麻烦,因为我们一张表中不能出现两个相同的主键。
2.主键生成策略
在使用代理主键的过程当中,尽量要做到自动生成主键,不能让用户手动设置主键。一般交给数据库自动增长,让程序生成唯一的标识。
在hibernate当中,为了减少程序的编写,内部提供了多种的主键生成策略:
-
increment
策略:自动增加 long、short、int
注意:在单线程中使用,不要在多线程中使用,因为该方式是寻找当前表最大的id号然后在此基础上+1为下一条记录赋值。所以当两个线程同时对数据库当中的id字段查询时若两个线程查到的是同一个id则两个线程插入的记录id相同必然报错! -
identity
策略:自动增长
原理:使用是数据库底层的增长策略,适用于有自动增长机制的数据库。Mysql有自动增长,Oracle是没有自动增长的。 -
sequence
策略:自动增长
原理:采用序列的方式,必须得要支持序列Oracle支持序列,Mysql不支持序列 -
uuid
策略:适用于字符串类型的主键
原理:使用hibernate中随机生成字符串的主键 -
native
策略:本地策略
原理:在identity和sequence自动切换 -
assigned
策略:hibernate不会帮你管理主键
原理:自己手动调用或通过程序来去生成主键
在开发当中我们一般都是使用native、uuid这两种方式。
持久化
1.什么是持久化&持久化类
什么是持久化
将内存中的一个对象持久化到(存储到)数据库的过程。hibernate框架就是一个持久化的框架,持久化对象会自动更新数据,只要成为持久态对象,不用调用update也会自动更新数据
什么是持久化类
一个Java类与数据库建立的映射关系。Java类+映射文件
2.持久化类编写规则
- 对持久化类提供一个无参的构造方法
底层会通过反射创建对象,如果没有无参构造,反射是无法创建对象的 - 对内部私有的字段要提供get与set方法
不提供的话。hibernate就无法获取对象的值 - 对象持久化类提供一个OID与数据库表当中的主键对应
Java中通过对象的地址来区别是否为同一个对象
数据库中通过主键来区别是否是同一条记录
Hibernate中通过持久化类的OID属性来区分是否是同一个对象 - 持久化类中的属性尽量使用包装类型
包装类型的默认值为NULL
基本数据类型的默认值为数字 - 持久化类不要使用final修饰
跟延时加载有关系,延时加载是Hibernate优化的手段返回的是一个代理对象。使用动态代理 ,低层使用的是字节码增强技术,继承这个类来进行代理。如果使用了final,就不能被继承,不能被继承,代理对象就无法创建,延时加载就无效了
3.持久化类的划分
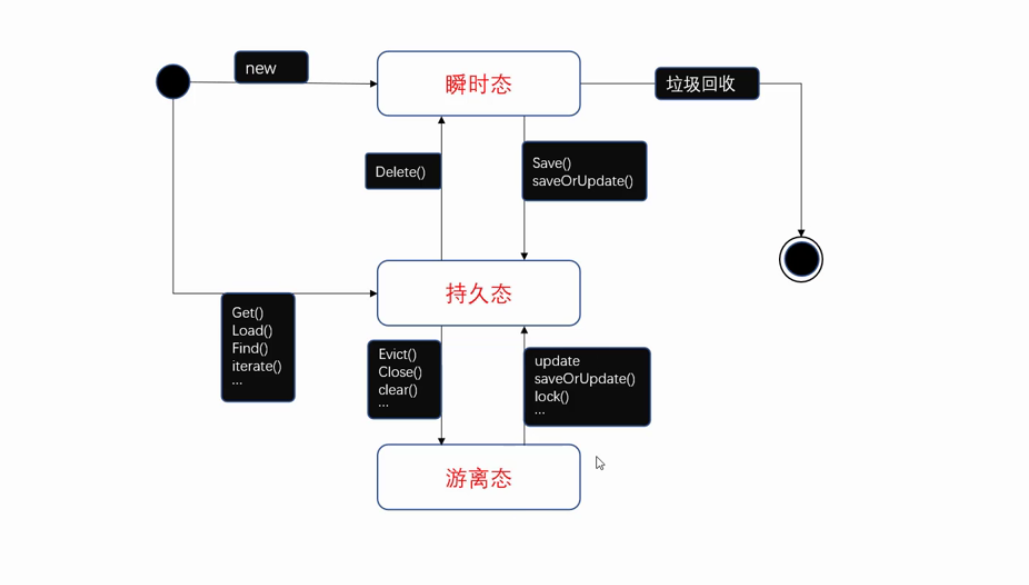
Hibernate是持久层的框架,通过持久化类完成ORM操作,Hibernate为了更好的管理持久化类,将持久化类对象分为三种状态:
| 状态名 | 状态 | 区分 |
|---|---|---|
| 瞬时态 | 没有唯一的OID 没有被session管理 |
刚new出对象时,还没有设置id,还没有被session所管理 |
| 持久态 | 有唯一的OID 有被session管理 |
已经有了id 调用session方法,把对象给session,才被session所管理 |
| 游离态/托管态/离线态 | 有唯一的OID 没有被session管理 |
把session关闭掉时close时 对象处理游离态 |

状态转换图:
一级缓存
什么是缓存,说白了就是一种优化的方式,将数据存储在缓存(内存)中从而可以不用到数据源(数据库)中去取数据,提高了我们的查询效率。而hibernate又有分一级缓存与二级缓存,其中一级缓存是session级别的,生命周期与Session一致,并且是由Session中的一系列Java集合构成的。一级缓存是自带的不可卸载。二级缓存是SessionFactory级别的缓存,需要自己去配置,默认是开启的,在企业当中一般都不用了,现在都redis
1.一级缓存的特点
- 当应用程序用Session接口的Save(),update(),saveOrUpdate()时,如果session缓存中没有相应的对象,就会自动的从数据库查询相应的信息,写到缓存当中。
- 当调用Session接口的load,get()方法,以及Query接口的list iterator方法时,会判断缓存中是否存在该对象,有则返回, 不会查询数据库,如果缓存中没有要查询的对象,再到数据库当中查询对应的对象,并添加到一级缓存中。
- 当调用session.close方法时,缓存会被清空
下面我们来看一个例子:
@Test
public void testSession(){
Session session = HibernateUtil.openSession();
Transaction transaction = session.beginTransaction();
//第一次获取缓存中不存在需要发送sql到数据库中查询
Customer customer1 = session.get(Customer.class, 2L);
System.out.println(customer1);
//第二次获取相同的数据,缓存中已经存在不需要去数据库获取
Customer customer2 = session.get(Customer.class, 2L);
System.out.println(customer2);
System.out.println(customer1 == customer2);
transaction.commit();
session.close();
}
上面代码运行的结果是:
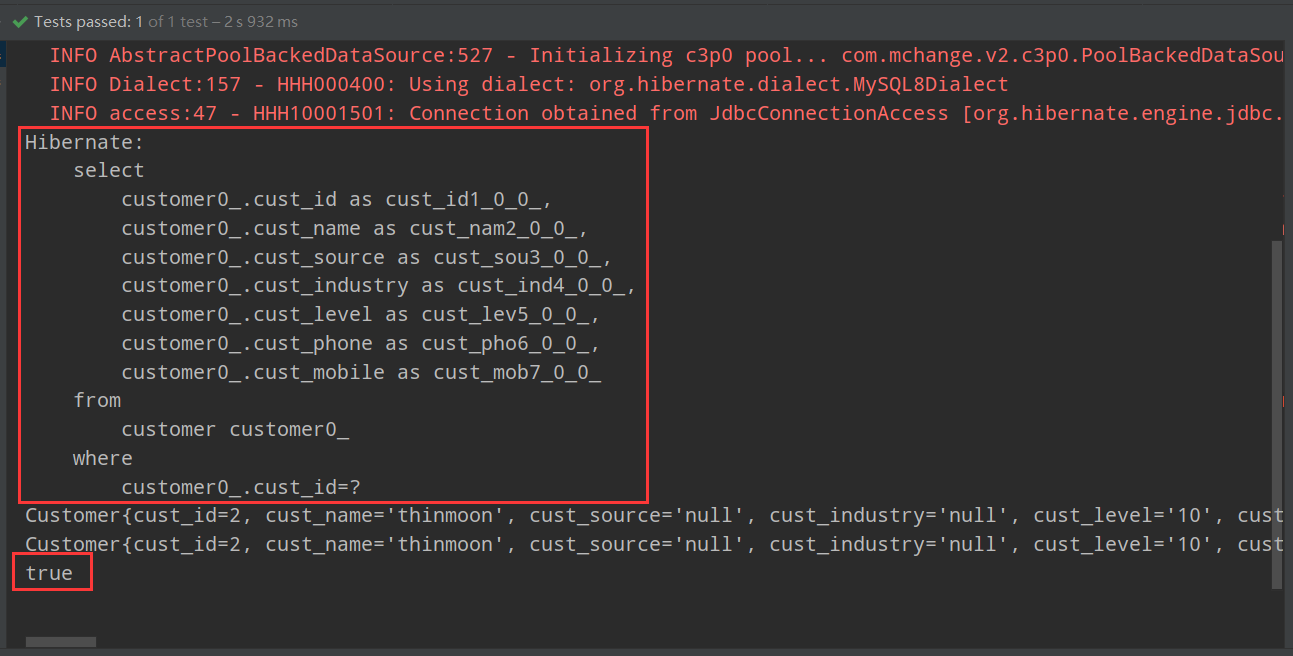
可以看到我们发送了两次对同一条记录的请求,hibernate只帮我们发送一次sql语句,原因就是第二次可以直接在缓存中取出。并且我们可以看到两次取出的是同一个对象!
2.一级缓存内部结构
一级缓存当中有一个区域:快照区
当我们使用id进行查询数据库,hibernate会将查询得到的结果放置到session一级缓存中,同时会复制一份数据放置到session的快照中。
当我们使用tr.commit()的时候,同时会清理session的一级缓存(flush),当清理session一级缓存的时候,hibernate会使用OID对一级缓存中对象和快照中的对象进行比对,如果2个对象(一级缓存的对象和快照的对象)中的属性发生变化,则执行update语句,更新数据库,此时快照区的数据更新成一级缓存中的数据,如果2个对象中的属性不发生变化,此时不执行update语句。这么做的目的就是确保缓存和数据库中的数据一致 。
同时这也解释了我们上文提到的持久态的对象为什么会自动的更新数据!