引言
什么是 TCP 的三次“握手”?相信大部分人都知道这个面试中常问的面试题,在这篇文章中,我会详细地解释它的细节,到时候你会发现,这是个非常简单的问题。然而,我们学习网络知识并不是为了去准备面试的,由于大部分的网络应用都采用 TCP 作为传输层的协议,因此了解它对于我们写网络程序很重要。在这篇文章中,我会深入很多 TCP 的技术细节,比如它是如何实现可靠数据传输,flow control,和 congestion control 的。如果大家能仔细读完这篇文章,相信一定会对 TCP 有个非常全面的了解。
TCP 连接管理
在这个小节中,我首先会大致介绍 TCP 连接的过程,然后会深入其细节,详细讲解在连接建立的过程中需要设置哪些 bit,初始化哪些状态,和如何关闭一个连接。
TCP 协议只运行在 end systems 上,因此中间的网络元素(比如:routers 和 link-layer switches)并不会去维护 TCP 的连接状态。事实上,中间的 routers 完全不知道有 TCP 连接,它们只看 datagrams. 一个 TCP 连接提供 full-duplex service,假设一个 host 上的进程 A 与 另一个 host 上的进程 B 之间存在一个 TCP 连接,那么应用层数据在从进程 A 到进程 B 的同时,也可以从进程 B 到进程 A.
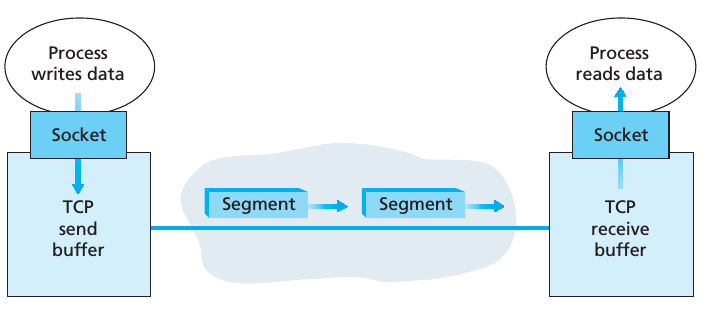
一旦 TCP 连接建立完成以后,2个进程之间就可以彼此发送数据。如下图所示,进程写一个数据流通过 Socket,然后 TCP 把这些数据放到 TCP send buffer(它在 three-way handshake 期间被设置) 中,不时 TCP 会从这个 buffer 中取一些数据,接着把它们传递到网络层。实际上,Each side of the connection has its own send buffer and its own receive buffer.
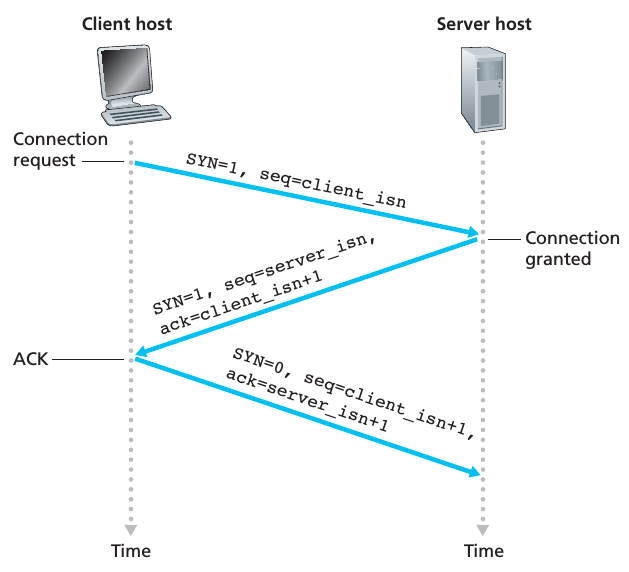
现在让我们来看看建立一个 TCP 连接的具体细节。假设一个 client 的进程想与 server 端的一个进程之间建立起一个 TCP 连接,它需要如下三个步骤:
1、client-side TCP 首先发送一个特殊的 TCP segment 到 server-side TCP. 这个特殊的 TCP segment 并不包含任何应用层的数据,但是这个 segment header 中的 SYN bit 被设为1,因此,这个 segment 叫做 SYN segment. 另外, client 也会随机选择一个初始的 sequence number (client_isn),并把它放到 segment 中的 sequence number field. 接着这个 segment 被封装到一个 IP datagram 中,发给 server.
2、一旦 server 端收到了步骤1中发送的 SYN segment,它会分配针对这个连接的 buffers 和变量,之后发送一个 connection-granted segment 给 client TCP,这个 segment 也不包含任何的应用层数据,但是这个 segment 有3个 header 会被设置:(1)SYN bit 设为1. (2)acknowledgment field 设置为 client_isn+1. (3)server 会选择一个属于它自己的初始 sequence number (server_isn),并把它放到 sequence number field. 这个 connection-granted segment 被称作 SYNACK segment
3、根据收到的 SYNACK segment,client 会分配针对这个连接的 buffers 和 变量。然后,client 会向 server 发送一个 segment,这个 segment acknowledges server 的 connection-granted segment(通过把 server_isn+1 放入到 acknowledgment field 中),由于连接已经建立,SYN bit 会设置成 0,这个 segment 也有可能会携带 client-to-server 的数据
从上面的步骤中可以看出,为了建立一个 TCP 连接需要在 host 之间发送3个 segment,因此连接建立的过程通常被叫做 three-way handshake. 整个过程如下图所示:
说完了连接的建立过程,现在让我们继续讨论一下连接关闭的过程吧。一个 TCP 连接中的 2 个进程中的任何一个进程都可以结束连接,当一个连接结束时,2个 host 中的资源(buffers 和 variables)被释放。现在我假设是 client 想要关闭连接,它的整个过程如下图:
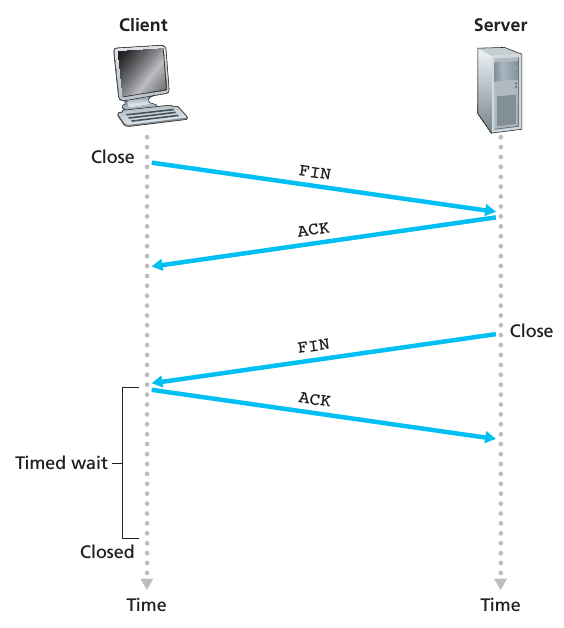
client TCP 会发送一个特殊的 TCP segment 到 server 进程,这个 segment 中的 FIN bit 被设为1. 当 server 收到这个 segment 以后,它会发送一个 acknowledgment segment 给 client. 紧接着,server 会发送它自己的 shutdown segment,其中的 FIN bit 也设为1. 最后,client acknowledges server 的 shutdown segment.,此时,2个 host 中的所有都会被释放。
TCP Segment 结构
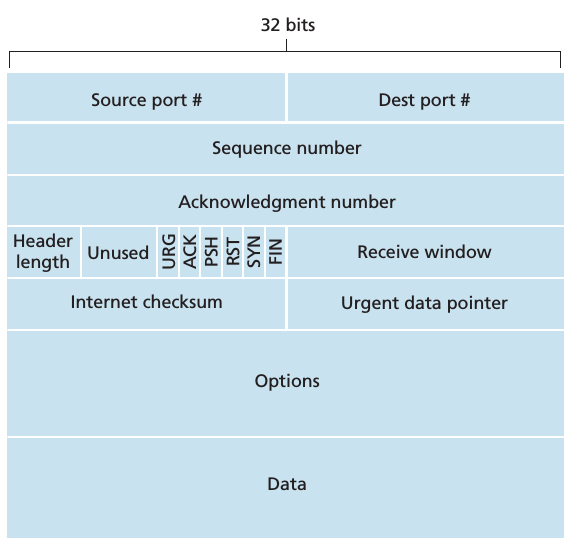
在这个小节中,我会详细介绍 TCP Segment 中各个 header fields 所表示的含义,下图就是一个 TCP Segment,它包含了很多的 header fields 和 一个 data field. 在详细解释这些 header fields 所表示的含义之前,我先来解释一下 Maximum Segment Size(MSS) 是什么?
MSS 就是可以放在1个 segment 中最大的数据量。 那么问题来了,我们如何来设置 MSS 呢?首先,设置 MSS 是为了确保 TCP segment(当它被封装进 IP datagram 时) 加上 network-layer headers 可以纳入到单个 link-layer frame. 因此,我们通常会找到 path MTU(the largest link-layer frame that can be sent on all links from source to destination),然后基于它来设置 MSS. 大家一定要记住:MSS 是一个 segment 中最大的 application-layer data 的大小,它并不包括 segment 中的 headers.
当 TCP 发送一个大文件时,它通常把文件打碎成大小为 MSS(最后1个 chunk 的大小有可能小于 MSS) 的 chunks,当 TCP 创建一个 segment 时,把其中的1个 chunk 放进 segment 的 data field. 下面我来介绍一下各个 header fields 所表达的含义。
TCP sender 和 receiver 用 sequence number field 和 acknowledgment number field 来实现可靠数据传输。The sequence numbers are over the stream of transmitted bytes and not over the series of transmitted segments. The sequence number for a segment is therefore the byte-stream number of the first byte in the segment. 下面我给大家举例说明一下 TCP 在这2个 fields 中都放入什么值。
假设 Host A 中的一个进程想要发送一个大小为 500000 字节的文件到 Host B 中的一个进程,MSS 设置成1000个字节。Host A 中的 TCP 会为数据流中的每个字节进行编号,第1个字节的编号为0,如下图所示:
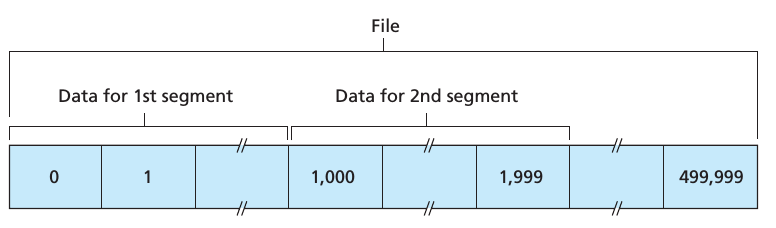
第1个 segment 的 sequence number 为0,第2个 segment 的 sequence number 为1000,第3个 segment 的 sequence number 为2000,依此类推,这些 sequence number 被插进相应 segment 的 sequence number field.
接下来让我们来了解 acknowledgment numbers 代表的含义是什么。由于 TCP 是 full-duplex,因此对于同1个 TCP 连接来说,当 Host A 给 Host B 发送数据的同时,它也可以收到 Host B 发给它的数据。下面让我们来一个具体的例子。
Telnet 是一个有名的 application-layer 协议,它用的传输层协议就是 TCP,假设 Host A 发起一个 session 到 Host B,由于是 Host A 发起的 session,所以它是 client,Host B 是 server. 这里我提醒大家一下,client 既可以做 TCP 的 sender,也可以做 TCP 的 receiver,sever 也如此。这里我们只想让 Host A 发送1个字符 ‘c’ 到 Host B,然后 Host B 在把这个字符发送回来。
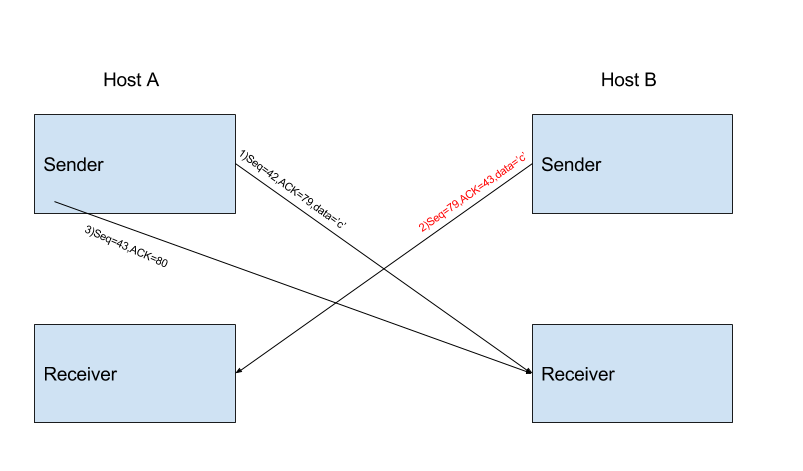
对于上图来说,我需要强调以下几个方面:
1)在上面的例子中,我把初始的 sequence number 标记为0,但是在实际的 TCP 连接的建立过程中,它是由 TCP 2 端的 Host 随机选择的,在它们进行 three-way handshake 时就已经选好了,因此从上图我们可以看到对于 Host A 来说,初始的 sequence number 为42,对于 Host B 来说,初始的 sequence number 是79,这没什么可争议的。
2)上图的第1步中,acknowledgment number 是79,它所表示的含义是它期望从 Host B 那收到的下一个 segment 的 sequence number
3)上图的第2步中,有2个目的:一个是提供 acknowledgment 表示 server 已经收到了 client 发送的数据,它通过把 acknowledgment number 置为 43 表明我已经收到了 sequence number 为 42 以及 42 以下的所有字节,一,现在我正在等 sequence number 为 43 的字节; 另一个是它携带了数据,即字符 ‘c’,发送回 client. This acknowledgment is said to be piggybacked on the server-to-client data segment.
4)上图第3步中的 segment 只有1个目的,就是 acknowledge 它已经成功地从 server 收到数据。由于这次的 segment 并没有携带数据,因此 receiver 并不会发送任何的 acknowledgment.
接下来,我来继续解释 segment 中各个 headers 的含义。
- 16-bit 的 receive window field 是用于 flow control 的,在下文中我会详细解释的
- 4-bit header length filed 用于指定 TCP header 的长度。由于 TCP 的 options field,TCP header 的长度可能会发生变化,通常情况下 options field 是空的,因此 TCP header 的长度通常是 20 个字节
- The optional and variable-length options field is used when a sender and receiver negotiate the maximum segment size (MSS) or as a window scaling factor for use in high-speed networks. A time-stamping option is also defined
- flag field 包含 6 bits. The ACK bit is used to indicate that the value carried in the acknowledgment field is valid; that is, the segment contains an acknowledgment for a segment that has been successfully received. The RST, SYN, and FIN bits are used for connection setup and teardown. Setting the PSH bit indicates that the receiver should pass the data to the upper layer immediately. Finally, the URG bit is used to indicate that there is data in this segment that the sending-side upper-layer entity has marked as “urgent.” The location of the last byte of this urgent data is indicated by the 16-bit urgent data pointer field. TCP must inform the receiving-side upper-layer entity when urgent data exists and pass it a pointer to the end of the urgent data. (In practice, the PSH, URG, and the urgent data pointer are not used.)
TCP 可靠数据传输
在这个小节中,我将会详细地介绍 TCP 是如何实现可靠数据传输的,但是在读本小节之前,我强烈建议大家先读一下 Reliable Data Transfer Protocol 的原理剖析,理解可靠数据传输的原理之后,我们再来看看 TCP 用到了什么样的技术来实现它的可靠数据传输。
如何设置 retransmit packet 的超时时间
TCP 用 timeout/retransmit 机制来应对底层 channel 可能丢失 packet 的情况,道理其实很简单,但是如果想要实现的这样的机制,我们有一个难题需要解决,也就是 timeout intervals 应该设成多大呢?有一点可以很明确,timeout 应该大于连接的 round-trip time(RTT,即从 segment 的发送到它被 acknowledged 所需要的时间)。那么接下来,就让我们看一下 TCP 是如何估算 sender 与 receiver 之间的 RTT.
TCP 通过 sampling(抽样) 发送到连接中的 segment 的行为,然后 averaging 这些 samples(样本)到一个 “平滑的” RTT 估算,我们暂且把这个估算叫做 EstimatedRTT. 当一个 segment 被发送到 TCP 连接中时,sender 会计时它花费多长时间被 acknowledged,因此会产生一系列地 RTT samples:
上面公式中的
有了 EstimatedRTT,TCP 会用下面的公式来计算 timeout interval:
其中 DevRTT 的计算公式如下:
其中推荐的
TCP 如何处理在网络中丢失的 packet
由于各个操作系统中的 TCP 实现细节都各不相同,在这个小节中,我会介绍一个高度简化版的 TCP sender,它只用 timeouts/retransmit 机制来应对 packet 会丢失的情况。如果你完全理解了 Reliable Data Transfer Protocol 的原理剖析,你一下就能明白下图中描述的简化版 TCP sender:

在 Reliable Data Transfer Protocol 的原理剖析 这篇文章中,我们为每个发送出去的但没有收到 acknowledgment 的 segment 都关联一个 timer. 但是,这样做会导致 timer 管理存在非常大的开销。因此,推荐的做法是只用一个 retransmission timer. 从上图看来,我们确实用的是单个 timer,你可以认为这个 timer 与最小 sequence number 的 segment 相关联,而如何设置超时时间,我在上个小节中已经说介绍过了。从上图中的第3个事件中,我们也可以看出,TCP 采用的是 cumulative acknowledgments,也就是如果你收到了 sequence number 为 n 的 packet 的 acknowledgment,也就表明所有 sequence number 小于等于 n 的 packet 都已经被 receiver 正确收到。
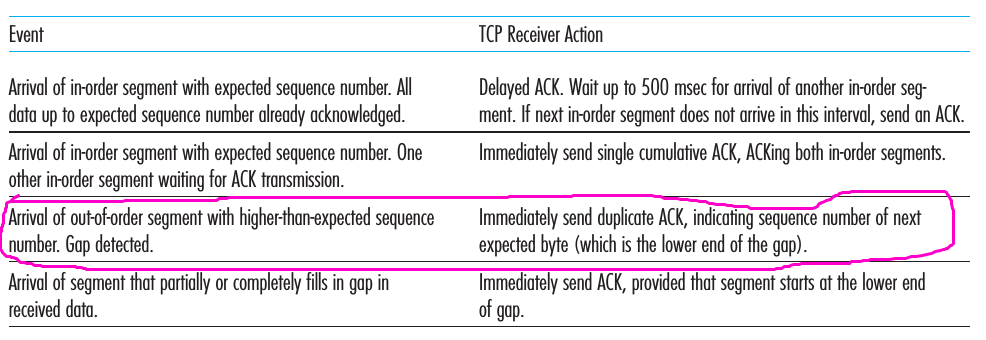
下面的表格中总结了 receiver’s ACK 的生成策略,其中画线部分表明了当 receiver 收到了 out-of-order segment 给出的反应(It reacknowledges the last in-order byte of data it has received),值得注意的是,表中并没有指明 receiver 如何处理 out-of-order segments,这样取决于具体的实现,我们完全可以在 receiver 端 buffer 这些 out-of-order segments.
Doubling the Timeout Interval
大多数的 TCP 实现都采用了 Doubling the Timeout Interval 这一技术,在这一小节中,我来介绍如何使用这个技术,和为什么使用这个技术。在上一小节中,我已经说明了 TCP 会 retransmit 一个超时的 packet. 如果采用了这个技术,TCP 会把这个超时的时间翻倍。下面我举个例子,比如 packet A 的超时时间为 0.75 秒,如果一个超时事件发生时,它会把 packet A 的超时时间设为 1.5 秒,如果再发生超时事件,它会把超时时间设为 3 秒,以此类推。如果 sender 正确收到了 ACK 之后(也就是上面图中的事件3),Timeout Interval 会用最新得到的 EstimatedRTT 和 DevRTT 重新计算出来。
那么为什么要采用这个技术呢?通常情况下,发生超时是要因为网络目前比较拥堵,也就是有太多的 packets 涌进 source 与 destination 之间的 routers,这样会导致长时间的 queuing delay,甚至是 packet 的丢失。如果在这个时间段内,sender 依然坚持连续地 retransmit packets,那么将会使拥堵变得更加严重。因此,这个技术使 TCP 更加有礼貌地去应对这样拥堵的情况。所以说,我们要每个司机都应该学习一下 TCP 地这种精神,以免让我们本来就很糟糕的路况变得更加糟糕。
Fast Retransmit
由于超时而引起的 retransmissions 会有一个超时时间可能会很长的问题。当一个 segment 丢失的时候,这个很长的超时时间会强制 sender 延迟 resending 丢失的 packet,因此会增加 end-to-end delay,而 Fast Retransmit 的出现就是解决这一问题的。
在上面的小节中,我已经说明了由于 out-of-order packet 的到来,receiver 会产生 duplicate ACK,并把它发送到 sender. 由于一个 sender 会连续发送大量地 packets,如果一个 packet 丢失了,sender 很有可能连续收到 duplicate ACKs. 如果一个 sender 收到的3个 duplicate ACKs 为了同一个数据,它会认为这个数据对应的 packet 已经丢失了。这时,即使超时事件并没有发生,sender 也会 retransmit 这个 packet. 由于我们这回加入了 fast retransmit 这个技术,我们应该把上面章节中的事件3改成下图的样子:

下图描述了 Fast retransmit 的过程:
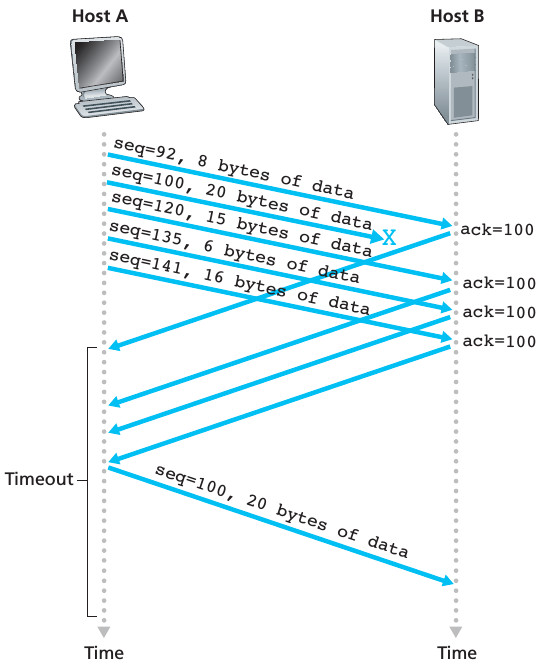
有些人可能会想,为什么不是1个 duplicate ACK 就导致 fast retransmit,而是3个才可以?其实就一句话,不会由于 packet reordering 地出现,过早地去 retransmitting. 下面是更详细地解释,英文很简单,我就不给大家翻译了:
Suppose packets
n,n+1,andn+2 are sent, and that packet n is received and ACKed. If packetsn+1andn+2 are reordered along the end-to-end-path (i.e., are received in the ordern+2,n+1 ) then the receipt of packet n+2 will generate a duplicate ack forn and would trigger a retransmission under a policy of waiting only for second duplicate ACK for retransmission. By waiting for a triple duplicate ACK, it must be the case that two packets after packetn are correctly received, whilen+1 was not received. The designers of the triple duplicate ACK scheme probably felt that waiting for two packets (rather than 1) was the right tradeoff between triggering a quick retransmission when needed, but not retransmitting prematurely in the face of packet reordering.
TCP Flow Control
在上面的章节中,我已经提到过 TCP 连接的每一端都有各自的 receive buffer,当 TCP 正确收到字节以后,然后会把它放到 receive buffer 中,之后上层应用会从这个 buffer 中读取数据,但是应用进程不一定就会立刻去读。实际上,一个应用进程可能忙于做其它的任务,可能很长一段时间之后才会读取 receive buffer 中的数据,那么在这种情况下,如果 sender 依然不断地去发送 packet,那么 receive buffer 很快就会被填满。因此,TCP 提供了 flow-control 来解决这种情况。
为了更好地理解 Flow control 的概念,而不陷于细节,在接下来的讨论中,我们假设 TCP receiver 丢弃 out-of-order packets. 其实 flow control 的原理很简单,就是在2端维护几个变量,下面我来介绍一下具体都有什么变量。如下图所示,receiver 端需要知道自己目前还有多少空闲的 receiver buffer,为了计算 rwnd,receiver 还需要 track 3个变量,它们分别是 RcvBuffer(receiver buffer 总共的大小),LastByteRcvd(最新收到的字节号),和LastByteRead(上层应用最后一次读的字节号).
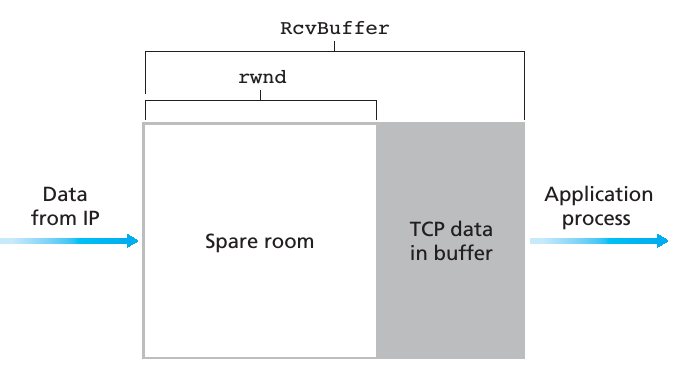
同样的道理,sender 也需要 track 2个变量,它们分别是 LastByteSent(最后一个发送的字节号) 和 LastByteAcked(最后收到 ACK 的字节号),因此在 sender 端需要保证下面的条件成立:
目前为止,flow control 的原理已经讲完了。但是,对于上面的整个过程来说,我们还有1个小问题需要解决。假设我们遇到这样一个场景:receiver buffer 已经满了,receiver 将 rwnd=0 放入到相应的 segment 中并发回给 sender,同时假设此时的 receiver 端已经没有任何 segment 可以发回给 sender. 这样就会导致即使 receiver buffer 已经有空闲了,sender 也不能发送 packet. 为了解决这个问题,TPC 规范要求当 rwnd = 0 时,sender 继续向 receiver 端发送1个数据字节的 segments,而 receiver 将会 acknowledged 这些 segmnets,如果 receiver buffer 有空闲,rwnd 的值又重新变成非0了.
UDP 并没有提供这样的 flow control 服务,如果上层应用进程并没有及时读取 buffer 中的数据,而 buffer 又已经满的情况下,如果依然有 segments 被发送到 buffer,它们将被 dropped.
TCP Congestion Control
在介绍 TCP 是如何实现 Congestion Control 之前,大家先想一想为什么要有 Congestion Control? 其实就一句话,它想让所有使用网络的人“公平地”占有网络资源。
想要实现 congestion control,我们需要考虑3个问题:1)TCP sender 如何限制发送 segment 的速率? 2)TCP sender 如何知道网络情况是否拥堵? 3)做到了以上2点,TCP 用什么样的算法去实现 congestion control? 下面我来简要地回答一下这3个问题:
1)通过 congestion window
2)由于网络层并不会给 TCP sender 一个显示的反馈,因此 TCP sender 不可能准确地知道网络状况如何,它只能去“感觉”。
3)TCP congestion-control algorithm
限制 TCP sender 的发送速率
在上面的章节中,我们通过 track 几个变量来实现 flow control,同样地道理,sender 通过 congestion window(暂且用 cwnd 表示) 变量,通过下面地公式,TCP 可以间接地控制 sender 发送 segment 的速率:
由于上面的公式中限制 unacknowledged 数据的数量,因此它间接地限制了 sender 的发送速率。通过调整 cwnd 的值,sender 就间接地调整了它发送数据到 connection 的速率。在这个小节中,我只想考虑 congestion control 的问题,因此在接下来的讨论中,我们假设 rwnd 无限大,因此 sender 的发送速率只被 cwnd 所限制。
TCP sender 感知网络中的拥堵情况
在上面的章节中,我们已经学习到如果网络状况很拥堵,那么连接路径中的某些 routers 会 overflow,从而导致 datagram 丢失。反过来,datagram 的丢失会触发 sender 中的 loss 事件(timeout or the receipt of three duplicate ACKs). 因此,如果有 loss event 发生,sender 就会认为 sender-to-receiver path 的网络情况拥堵。如果 TCP sender 顺利地收到 ACK,则表明发送的 segment 已经成功地被 receiver 收到,从而表明当前网络状况很好。
有一点需要强调的是:这里并没有一个 explicit signals 去表明网络的拥堵状况,ACKs 和 loss events 都是一个 implicit signals,因此 each TCP sender acts on local information asynchronously from other TCP senders.
TCP congestion-control 算法
理解了 sender 如何控制发送速率,如何感知网络是否拥堵,现在让我们考虑一下 TCP 是如何操作它们,从而做到 congestion control 的。如果理解了上面所有的内容,那么你就可以很容易理解这个算法,其实整个算法所描述的就是在3个状态(slow start,congestion avoidance,和 fast recovery)间不断切换,其中 fast recovery 并不是必要的。对于这个算法来说,我并不想用太多的文字来描述它,这是因为算法本身其实很简单,但是它的逻辑比较多,这会导致需要大量的文字去描述它,从而增加了其复杂性,让其更不好理解。因此我直接给出 TCP congestion control 的 FSM,如下图,然后我强调一些大家需要知道的重点内容。
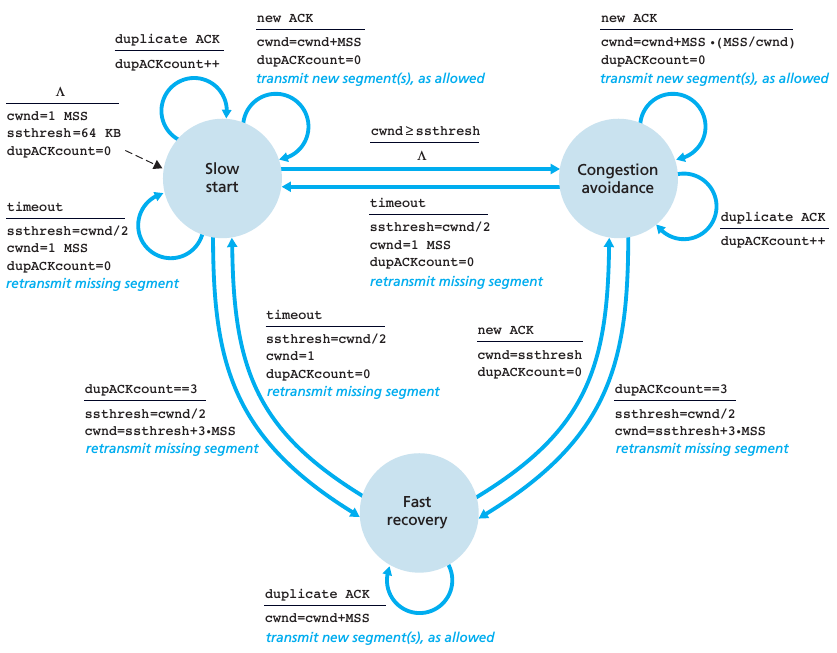
首先我们谈谈 slow start 这个状态的重点内容:
1、从上图中的初始状态中我们可以看出,cwnd 的初始值为 1,每当 new ACK(sender 此时会认为网络状况很好) 事件触发时,sender 会让 cwnd = cwnd + MSS,因此在这个状态小,虽然初始的发送速率很慢,但是它的速度是呈指数增长(
2、ssthresh 是 slow start threshold 的缩写; 从上图可以看出,3个事件会导致 slow start 的状态结束:1)当 cwnd 大于 slow start 的阈值; 2)超时事件; 3)收到3个重复的 ACKs,即发生 fast retransmit
你从上图可以看到,ssthresh 的值除了在初始的情况下被设置一次外,其余设置它的时候要么是超时,要么就是收到3个重复的 ACKs,而且每次它的值都被设成 ssthresh=cwnd/2,此时公式中的 cwnd 都是在网络比较拥堵时的值发送速率,因此当我们的
接下来让我们谈谈 congestion avoidance 这个状态的重点内容:
当它收到一个新 ACK 时,它让 cwnd=cwnd+MSS*(MSS/cwnd),这就表明这个状态下的发送速率是呈线性增长的。比如,如果当前 cwnd = 10 个 segment,因为1个 MSS 等于1个 segment,所以它必须收到10个新的 ACK 之后,才会增加1个 MSS
最后,让我们来聊一隐 fast recovery 状态:
上面我已经说过了,这个状态是推荐使用的,但并不是必须的,在早期的 TCP 版本中,TCP Tahoe,就没有这个状态,是新的 TCP 版本,TCP Reno,才有这个状态。如果大家仔细想一下,其实这个状态很合理,既然我们可以收到3个重复的 ACKs,证明丢包很有可能是先前网络状况不好的情况下引起的,目前网络状况不错。从上图我们可以看到,只有由3个重复的 ACKs 引起的 retransmit 才会进入这个状态。
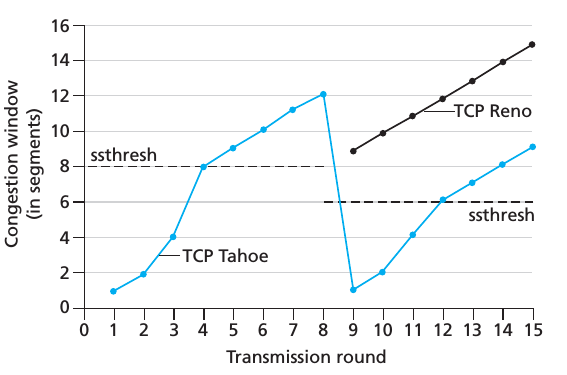
下图是 Tahoe 和 Reno 2个 TCP 版本关于 congestion window 变化的对比,我们可以看到 cwnd 的初始值都是 1 MSS,即1个 segment,然后呈指数增长,紧接着越过 slow start 的阈值以后呈线性增长,在第9个 transmission round 时,由于 Tahoe 版本没有 fast recovery 状态,我们可以看到它又回到了 slow start 状态,而 Reno 进入了 fast recovery 状态。