在这篇文章中,我们将一步步地实现从梨视频网站中批量下载视频。
第一步当然是导入需要的库。在这里只简单地使用 requests 库即可。当然,如果想导入 re 库也可以,但是没有必要,因为这个库是 python 内建模块。
import requests
Freshman
首先,我们先来尝试找到一个视频的地址来下载此视频。
打开梨视频网站,随便点开一个视频,如:
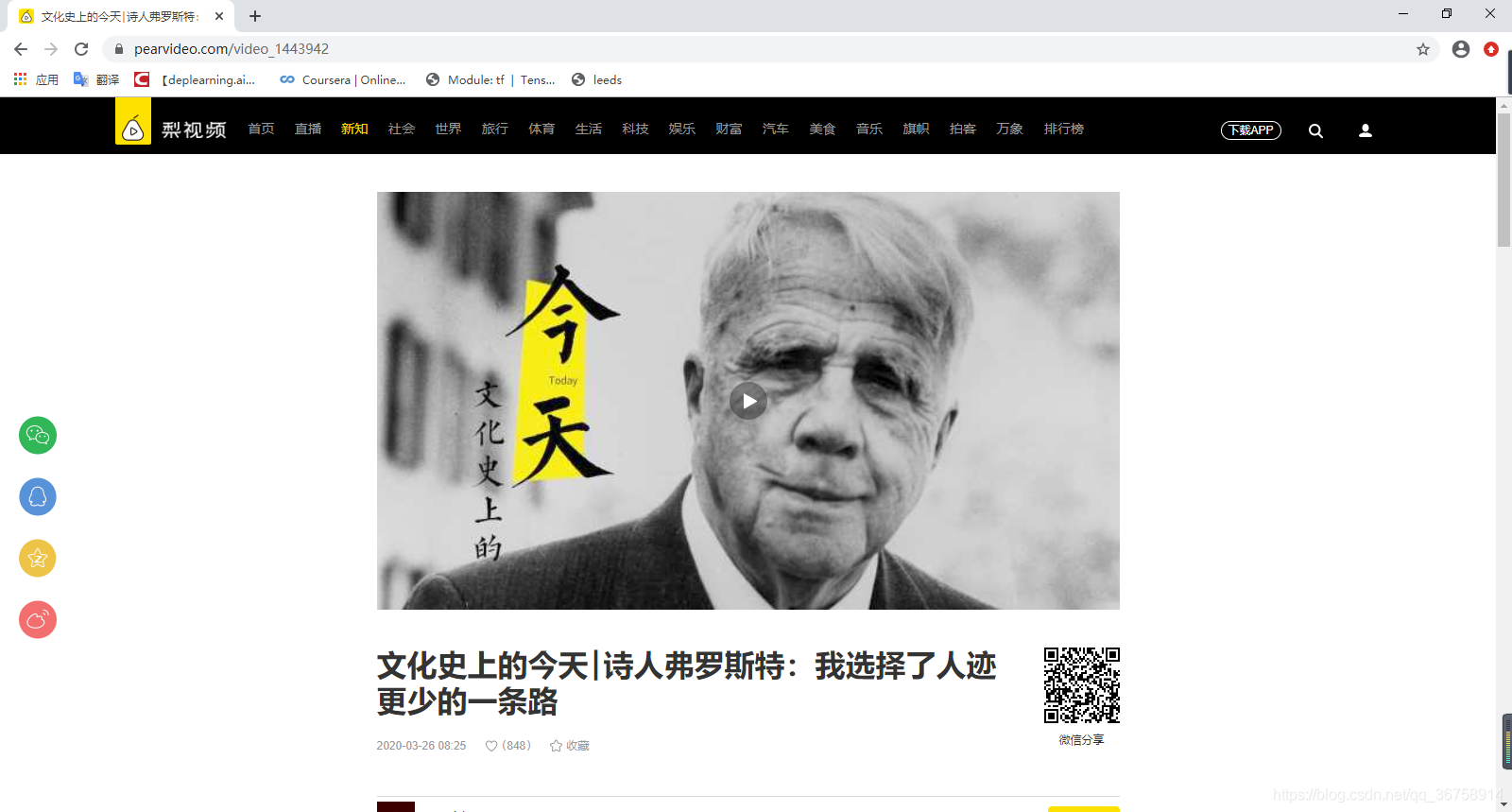
按(Fn+)F12 键,或者鼠标右击屏幕选中“检查”,之后将会出现开发者工具界面,选中“Network”,然后只看“Media”类型的信息,如下图所示。

然后开始播放视频,开发者工具中将会出现这个视频的地址。

此时我们就得到了这个mp4文件的地址。
然后我们就要开始请求网页数据了:
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36'
}
response = requests.get(mp4_url, headers=headers)
其中 headers 被称为请求头,它的作用是将我们使用 python 访问网页伪装成我们正在使用浏览器访问,以防止被反爬。那么,我们如何来寻找 headers 嘞?
还是在开发者工具这里,在 Network 里随便点击一个地址(假设还是点击刚才找到的mp4地址),会出现:
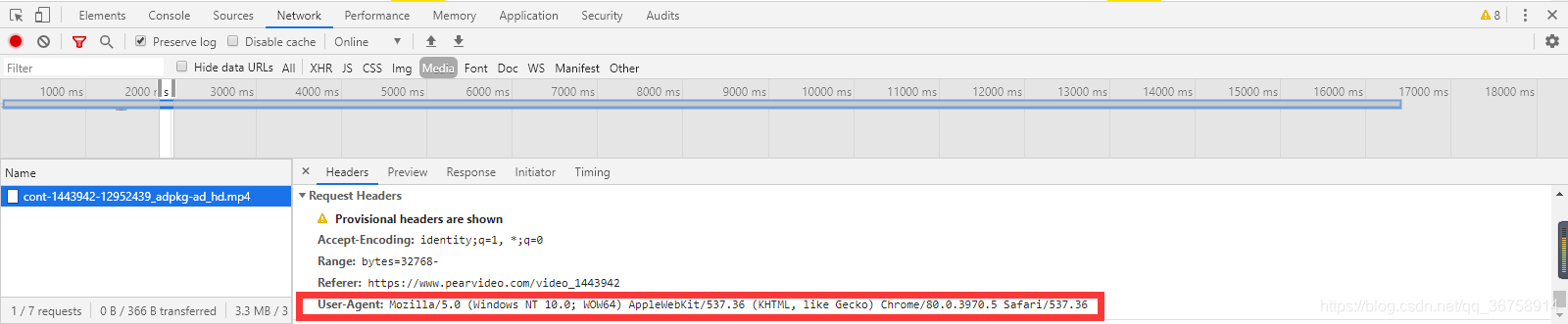
这就是我们的 headers。
得到了网页数据之后,我们就可以将它的内容(即视频)写入文件中了。
with open('人力驱动.mp4', mode='wb') as f:
f.write(response.content)
如此一来,这个视频就被下载好了。
Amateur
那么,我们可不可以直接用下面这个网页地址来下载视频呢?
同样地,我们还是要先请求网页数据:
# 获取网址(视频详情页)
url = 'https://www.pearvideo.com/video_1663280'
# 请求网页数据
res = requests.get(url, headers=headers)
然后,我们选中开发者工具中的 “Element”,并在里面找到那个mp4地址。
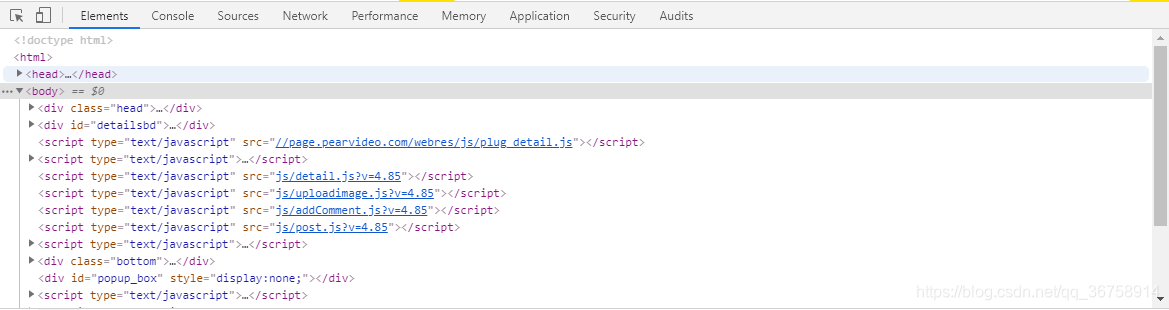
或者,我们点击鼠标右键,选择 “查看网页源代码”,然后在这里面找到地址:
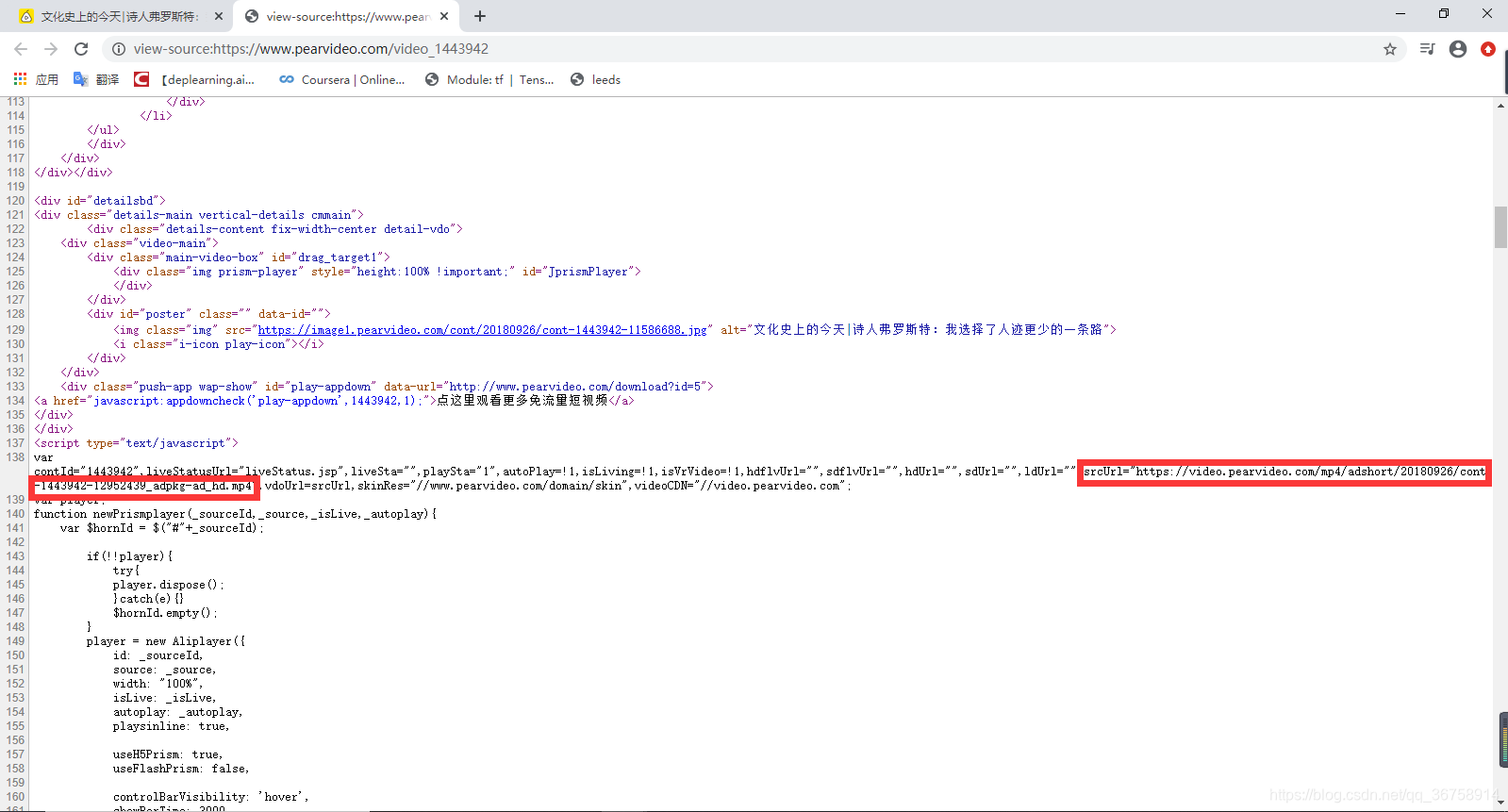
然后我们使用正则表达式来提取视频地址:
mp4_url = re.findall('srcUrl="(.*?)"', res.text)[0]
这个视频的名字也找得到:

name_mp4 = re.findall(r'<title>(.*?)</title>', res.text)[0]
然后类似于请求网页数据的操作,我们对视频数据也进行请求:
# 请求视频数据
response = requests.get(mp4_url, headers=headers)
然后下载视频:
# 保存数据
file_name = f'{name_mp4}.mp4'.replace('_MakerBeta-梨视频官网-Pear Video', '')
with open(file_name, mode='wb') as f:
f.write(response.content)
其中,.replace(A, B) 是用B替换A的意思。
Skilled
接下来,我们将上面的操作封装成一个函数,这个函数的作用是:传入网页地址,可以将这个网页里对应的视频下载下来。
def download(url):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36'
}
# 请求网页数据
res = requests.get(url, headers=headers)
# 正则表达式模块(内建模块,本身自带)
mp4_url = re.findall('srcUrl="(.*?)"', res.text)[0]
name_mp4 = re.findall(r'<title>(.*?)</title>', res.text)[0]
# 请求视频数据
response = requests.get(mp4_url, headers=headers)
# 保存数据
file_name = f'{name_mp4}.mp4'.replace('_MakerBeta-梨视频官网-Pear Video', '')
with open(file_name, mode='wb') as f:
f.write(response.content)
我们的终极目的是将梨视频里的部分视频批量下载下来。在这里,假设我们需要下载“科技”板块的视频。那么我们点击进入此板块,然后下拉页面,此时开发者工具中的 “Network” 中将会出现 XHR 类型的地址:
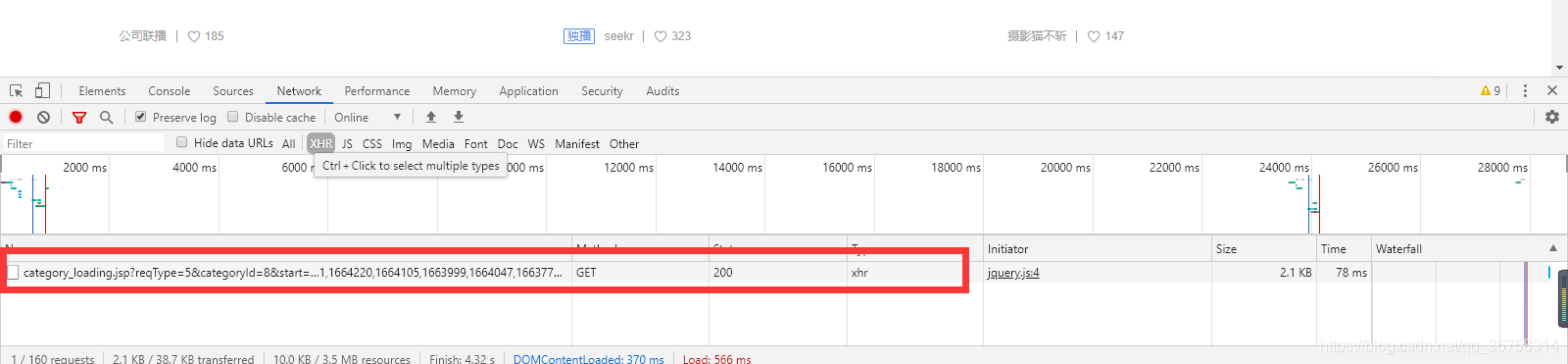
点击它,复制它的请求网址:
 然后开始请求这个网址:
然后开始请求这个网址:
page_url = 'https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start=24&mrd=0.9090481392720261&filterIds=1664423,1664433,1662498,1663692,1663688,1663374,1663280,1663194,1663159,1663019,1663005,1662828,1662717,1662760,1662543'
response = requests.get(page_url)
然后同样地,我们再次打开网页源代码,可以看到每个视频网页的网址的最后一部分(前一部分都是 ‘https://www.pearvideo.com/’),如:

然后我们把这些网址都提取出来并下载视频即可。
catagory = re.findall(r'<a href="(.*?)" class="vervideo-lilink actplay">', response.text)
for i in catagory:
download('https://www.pearvideo.com/' + i)
自此,我们经历了已知视频地址下载视频的初级阶段,到已知视频的网页网址下载视频的中级阶段,到批量下载视频的高级阶段。
