正则表达式
七、平衡组/递归匹配-----html的匹配
(?'group') 把捕获的内容命名为group,并压入堆栈(Stack)
(?'-group') 从堆栈上弹出最后压入堆栈的名为group的捕获内容,如果堆栈本来为空,则本分组的匹配失败;
(?(group)yes|no) 如果堆栈上存在以名为group的捕获内容的话,继续匹配yes部分的表达式,否则继续匹配no部分;
(?!) 零宽负向先行断言,由于没有后缀表达式,试图匹配总是失败。
示例,匹配一个html中的<div><div/>之中的内容:
<div[^\)]*>[^\(\)]*(((?'Open'<div[^\)]*>)[^\(\)]*)+((?'-Open'</div>)[^\(\)]*)+)*(?(Open)(?!))</div>
为了便于阅读,即呈现以下的效果:
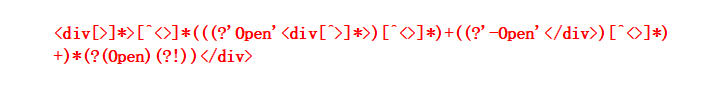
<div[^>]*>匹配了"<div"、之后跟着的除了">“的内容以及之后的一个”>";
[^<>]*匹配了">“后除了左尖括号和右尖括号的内容;
接下来是3个连续的优先级括号,先从最里面开始看:
(?'Open'<div[^>]*>)匹配了<div>中嵌套的又一个”<div"+内容+">",并且压入名为Open的堆栈;
[^<>]*匹配了第二个">“后除了左尖括号和右尖括号的内容;
联立上两条的((?'Open'<div[^>]*>)[^<>]*)+即是匹配了第二个”<div"+内容+">"+后面的内容;+则是进行多次重复,即现在我们已经匹配了的内容如下:(并且注意,此处均没有匹配任何一个</div>)

(?'-Open'</div>)中,?'-Open'是弹出Open中最后压入的东西(在这里Open中只压入左括号,即弹出最近出现的左括号一个),之后再匹配一个</div>,但是若堆栈本身为空,此括号优先级处匹配失败,包括</div>也无法匹配到;
[^<>]*匹配了当前这一级的</div>之后的内容;
总体来看((?'-Open'</div>)[^<>]*)+,即匹配了</div>及之后到再次出现一个</div>之间的内容多次;
三个优先级括号内的内容终于可以合起来了,(((?'Open'<div[^>]*>)[^<>]*)+((?'-Open'</div>)[^<>]*)+)*,总体下来就是匹配了除最外一级<div></div>、以及隶属于最外层<div></div>的内容的内容,看图理解就是匹配了未被划掉的行数:

(?(Open)(?!)),最后这里即是在遇到最外层的右尖括号前面,判断"Open"这个堆栈中是否为空;如果非空,则匹配失败。
八、其它代码

