Linux文件处理工具
一. cut
功能 : 数据切割,用于显示每行从开头算起 num1 到 num2 的文字。
语法 :
cut [-bn] [file]
cut [-c] [file]
cut [-df] [file]
选项 :
| -b | 以字节为单位进行分割 |
|---|---|
| -c | 以字符为单位进行分割 |
| -d | 自定义分隔符,默认为制表符 |
| -f | 与-d一起使用,指定显示哪个区域 |
例如 :-b
[root@xiaoagiao ~]# cat ab
apple
apple
apple
Apple
apple q
apple q
apple q
bannan
shj
[root@xiaoagiao ~]# cut -b 4 ab//将文件每行第四个字符显示出来。
l
l
l
l
l
l
l
n
- -c
[root@xiaoagiao ~]# cat ac
李云龙
apple
王富贵
Apple
apple q
bannan
shj
[root@xiaoagiao ~]# cut -b 1 ac
▒
a
▒
A
a
b
s
[root@xiaoagiao ~]# cut -c 1 ac
李
a
王
A
a
b
s
数字可以代表区间。
如: 1-2 ,-2 (前两个),2-(第二个往后)。
- - f -d
cut -d ’ ’ -f 2 ab -->以空格为分隔符显示ac文件内容第二段。
二 . sort
功能 :将文件内容排序显示。
语法 :sort [-option] file
选项 :
| -f | 忽略大小写排序 |
|---|---|
| -b | 忽略最前面的空白字符 |
| -M | 以月份名字排序 |
| -n | 以纯数字排序 |
| -u | 相邻数据去重 |
| -r | 反向排序 |
| -t | 指定排序分隔符 |
| -k | 执行区间 |
| -o filename | 将结果保存在filename中 |
例如 :
-k和-t
sort -t ’ . ’ -k 2 file—>每行以 . 为分隔符排序后面的内容。
sort -o newfile file —>将file的内容排序后放入newfile中。
三. uniq
功能 : 挑选排序过的文件中重复的行
| -c | 标注出现的次数(相邻行) |
|---|---|
| -d | 只输出重复的行 (相邻行) |
| -D | 显示所有重复行 (相邻行) |
| -f | 跳过前N行 是通过空白分割 |
| -i | 忽略大小写 |
| -s N | 跳过前N行(除过第n行) |
| -u | 只显示唯一的行 |
| -w N | 每行的第N个字符之后不做对照 |
uniq [-option] file
四.grep(文本过滤工具)
grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来。
正则表达式:由一类特殊的字符以及文本字符所编写的模式,并不代表字面含义,表达控制或者通配的功能。
- 命令格式:
grep [option] pattern file
- 命令功能:
用于过滤/搜索的特定字符。
3. 命令参数:
- -i:忽略字符大小写
- -n:显示行号
- -E:支持使用扩展正则表达式
- -o:打印匹配到的行
- -v:显示不能被匹配到的行
- -A #:后几行
- -B #:前几行
- -C #:前后各几行
例:
grep -A 3 root /etc/passwd
找到后三行中的root字符。
4. 字符匹配
-
. :匹配任意单个字符。
-
[ ] :匹配指定范围内任意单个字符
-
[^] :匹配指定范围外任意字符
-
[:alnum:] #文字数字字符
-
[:alpha:] #文字字符
-
[:digit:] #数字字符
-
[:graph:] #非空字符(非空格、控制字符)
-
[:lower:] #小写字符
-
[:cntrl:] #控制字符
-
[:print:] #非空字符(包括空格)
-
[:punct:] #标点符号
-
[:space:] #所有空白字符(新行,空格,制表符)
-
[:upper:] #大写字符
-
[:xdigit:] #十六进制数字(0-9,a-f,A-F)
5. 匹配次数
* :匹配其前面的字符任意次。0次,1次或者多次
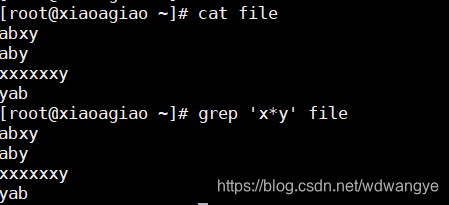
-
.* :匹配任意长度的任意字符

-
? :匹配其前面的字符0次或者1次,最多一次
[root@xiaoagiao ~]# grep 'x\?y' file abxy aby xxxxxxy yab -
\ + :匹配其前面的字符1次或者多次,至少一次
[root@xiaoagiao ~]# grep 'x\+y' file
abxy
xxxxxxy
前四种虽然可以指定匹配次数,但不能规定准确的次数。
| \{m\} | 匹配其前面的字符m次 |
|---|---|
| \ {m,n \ } | 匹配其前面的字符至少m次,至多n次(m到n次) |
| \ {0,n \ } | 匹配前边字符至多n次 |
| \ {m, \ } | 匹配前边的字符至少m次 |
如:’[a-z]\{5,10\}'匹配有5–10个连续小写字母的行。
6. 位置锚定
-
^:行首锚定,用于模式的最左侧。
如:’^grep’–>匹配所有以grep开头的行。 -
$:行尾锚定,用于模式的最右侧。
如:’^grep’–>匹配所有以grep结尾的行。 -
^ $:空白行
如:^ [[:space:]]*$–>筛选空白或包含空白字符的行。
^pattern$–>用pattern来匹配整行。
-
\ <或者\b:词首锚定,用于单词的左侧。
-
\ >或者\b:词尾锚定,用于单词的右侧。
如 : ‘\ <ab’–>匹配以ab开头的行。
7. 分组引用。
\ (\ ):
**分组:**将一个或者多个字符捆绑在一起当作一个整体处理。
引用 :
分组括号内匹配的模式,会被正则表达式引擎记录在内部变量中,通过变量进行应用。
- \1:模式从左侧起,第一个左括号与之匹配的右括号之间模式所匹配到的字符
- \2: 模式从左侧起,第二个左括号与之匹配的右括号之间模式所匹配到的字符。
- …
如 :grep ‘(l. .k)’ . * file
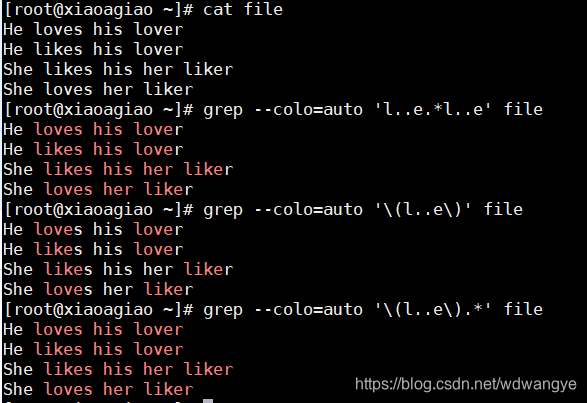
grep ‘(l. .k)’ . *\1 file

指定某一个分组后,会将第一个过滤的目标作为指定目标,在当前行只找相同的字符
从而找到前后相同字符的行。
grep ’ (l . . k\ ). *( r . . t \ ). *\1’ file(两个分组,匹配第一个)
grep ’ (l . . k\ ). *( r . . t \ ). * \1. *\2’ file(两个分组,匹配两个)
