Hadoop--入门
HDFS概述及常用命令
一.HDFS概述
1.背景
随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理 多台机器上的文件,这就是分布式文件管理系统。HDFS只是分布式文件管理系统中的一种
2.定义
HDFS (Hadoop Distributed File System), 它是-个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。HDFS的使用场景适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据分析,并不适合用来做网盘应用
二.HDFS优缺点
1.优点
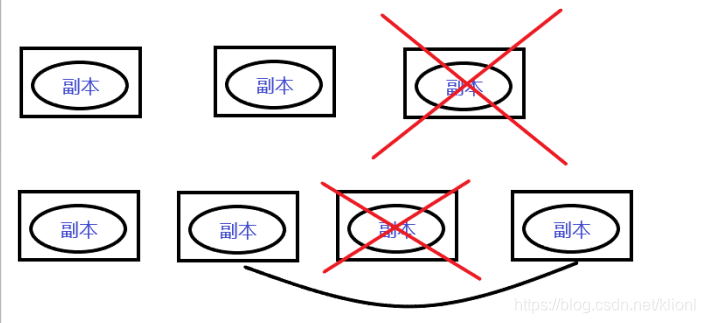
1.高容错性
(1)数据自动保存多个副本。它通过增加副本的形式,提高容错性。
(2)某一个副本丢失以后,它可以自动恢复。
2.适合处理大数据
(1)数据规模:能够处理数据规模达到GB、TB、甚至PB级别的数据
(2)文件规模:能够处理百万规模以上的文件数量,数量相当之大。
3.可构建在廉价机器上,通过多副本机制,提高可靠性。
2.缺点
1不适合低延时数据访问,比如亳秒级的存储数据,是做不到的。
2无法高效的对大量小文件进行存储。
(1)存储大量小文件的话,它会占用NameNode大量的内存来存储文件目录和块信息。这样是不可取的,因为NameNode的内存总是有限的
(2)小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
3不支持并发写入、文件随机修改。一个文件只能有一个写,不允许多个线程同时写;
三.HDFS组成结构
1.NameNode
相当于Master, 它是一个主管、管理者
(1)管理HDFS的名称空间
(2)配置副本策略
(3)管理数据块(Block) 映射信息
(4)处理客户端读写请求
2.DataNode
相当于Slave,NameNode下达命令, DataNode执行实际的操作
(1)存储实际的数据块
(2)执行数据块的读写操作
3.Client
客户端
(1)文件切分,文件上传HDFS的时候,Client将文件切分成一个一个的Block, 然后进行上传
(2)与NameNode交互,获取文件的位置信息
(3)与DataNode交互, 读取或者写入数据
(4)Client提供一些命令来管理HDFS,比如NameNode格式化
(5)Client可以通过一些命令来访问HDFS,比如对HDFS增删查改操作
4.Secondary NameNode
并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务
(1) 辅助NameNode,分担其工作量,比如定期合并Fsimage和Edit, 并推送给NameNode
(2)在紧急情况下,可辅助恢复NameNode
四.HDFS常用命令
1.基本语法
bin/hadoop fs 具体命令 或者 bin/hdfs dfs 具体命令
dfs是fs的实现类
2.命令大全
[root@master hadoop-2.7.2]# bin/hadoop fs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>]
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] <path> ...]
[-cp [-f] [-p | -p[topax]] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] <src> <localdst>]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
Generic options supported are
-conf <configuration file> specify an application configuration file
-D <property=value> use value for given property
-fs <local|namenode:port> specify a namenode
-jt <local|resourcemanager:port> specify a ResourceManager
-files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster
-libjars <comma separated list of jars> specify comma separated jar files to include in the classpath.
-archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines.
The general command line syntax is
bin/hadoop command [genericOptions] [commandOptions]
3.常用命令实操
1 启动Hadoop集群(方便后续的测试)
[root@master hadoop-2.7.2]# sbin/start-dfs.sh
[root@master hadoop-2.7.2]# sbin/start-yarn.sh
2 -help:输出这个命令参数
[root@master hadoop-2.7.2]# hadoop fs -help rm
-rm [-f] [-r|-R] [-skipTrash] <src> ... :
Delete all files that match the specified file pattern. Equivalent to the Unix
command "rm <src>"
-skipTrash option bypasses trash, if enabled, and immediately deletes <src>
-f If the file does not exist, do not display a diagnostic message or
modify the exit status to reflect an error.
-[rR] Recursively deletes directories
3 -ls: 显示目录信息
[root@master hadoop-2.7.2]# hadoop fs -ls /
Found 3 items
-rw-r--r-- 4 root supergroup 1366 2020-03-20 14:52 /README.txt
drwx------ - root supergroup 0 2020-03-21 19:40 /tmp
drwxr-xr-x - root supergroup 0 2020-03-21 20:04 /user
4 -mkdir:在HDFS上创建目录
[root@master hadoop-2.7.2]# hadoop fs -mkdir -p /sanguo/shuguo
5 -moveFromLocal:从本地剪切粘贴到HDFS
[root@master hadoop-2.7.2]# hadoop fs -moveFromLocal ./kongming.txt /sanguo/shuguo
[root@master hadoop-2.7.2]# hadoop fs -ls /sanguo/shuguo
Found 1 items
-rw-r--r-- 4 root supergroup 31 2020-04-03 16:38 /sanguo/shuguo/kongming.txt
6 -appendToFile:追加一个文件到已经存在的文件末尾
7 -cat:显示文件内容
[root@master hadoop-2.7.2]# hadoop fs -appendToFile liubei.txt /sanguo/shuguo/kongming.txt
[root@master hadoop-2.7.2]# hadoop fs -cat /sanguo/shuguo/kongming.txt
wo shi kong ming
wo shi liubei
8 -chgrp 、-chmod、-chown:Linux文件系统中的用法一样,修改文件所属权限
[root@master hadoop-2.7.2]# hadoop fs -chmod 666 /sanguo/shuguo/kongming.txt
[root@master hadoop-2.7.2]# hadoop fs -ls /sanguo/shuguo
Found 1 items
-rw-rw-rw- 4 root supergroup 31 2020-04-03 16:38 /sanguo/shuguo/kongming.txt
9 -copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去
[root@master hadoop-2.7.2]# hadoop fs -copyFromLocal README.txt /
[root@master hadoop-2.7.2]# hadoop fs -ls /
Found 2 items
-rw-r--r-- 4 root supergroup 1366 2020-04-03 16:41 /README.txt
drwxr-xr-x - root supergroup 0 2020-04-03 16:35 /sanguo
10 -copyToLocal:从HDFS拷贝到本地
[root@master hadoop-2.7.2]# hadoop fs -copyToLocal /sanguo/shuguo/kongming.txt ./
[root@master hadoop-2.7.2]# ls ./
bin include lib LICENSE.txt logs README.txt share
etc kongming.txt libexec liubei.txt NOTICE.txt sbin
[root@master hadoop-2.7.2]# cat kongming.txt
wo shi kong ming
wo shi liubei
11 -cp :从HDFS的一个路径拷贝到HDFS的另一个路径
[root@master hadoop-2.7.2]# hadoop fs -cp /sanguo/shuguo/kongming.txt /zhuge.txt
[root@master hadoop-2.7.2]# hadoop fs -ls /
Found 3 items
-rw-r--r-- 4 root supergroup 1366 2020-04-03 16:41 /README.txt
drwxr-xr-x - root supergroup 0 2020-04-03 16:35 /sanguo
-rw-r--r-- 4 root supergroup 31 2020-04-03 16:46 /zhuge.txt
12 -mv:在HDFS目录中移动文件
[root@master hadoop-2.7.2]# hadoop fs -mv /zhuge.txt /sanguo/shuguo/
[root@master hadoop-2.7.2]# hadoop fs -ls /sanguo/shuguo/
Found 2 items
-rw-rw-rw- 4 root supergroup 31 2020-04-03 16:38 /sanguo/shuguo/kongming.txt
-rw-r--r-- 4 root supergroup 31 2020-04-03 16:46 /sanguo/shuguo/zhuge.txt
13 -get:等同于copyToLocal,就是从HDFS下载文件到本地
[root@master hadoop-2.7.2]# hadoop fs -get /sanguo/shuguo/kongming.txt ./
get: `./kongming.txt': File exists
14 -getmerge:合并下载多个文件,比如HDFS的目录 /user/atguigu/test下有多个文件:log.1, log.2,log.3,…
[root@master hadoop-2.7.2]# hadoop fs -getmerge /sanguo/shuguo/* /zaiyiqi.txt
[root@master hadoop-2.7.2]# cat /zaiyiqi.txt
wo shi kong ming
wo shi liubei
wo shi kong ming
wo shi liubei
15 -put:等同于copyFromLocal
[root@master hadoop-2.7.2]# hadoop fs -put /zaiyiqi.txt /sanguo/shuguo
[root@master hadoop-2.7.2]# hadoop fs -ls /sanguo/shuguo
Found 3 items
-rw-rw-rw- 4 root supergroup 31 2020-04-03 16:38 /sanguo/shuguo/kongming.txt
-rw-r--r-- 4 root supergroup 62 2020-04-03 16:51 /sanguo/shuguo/zaiyiqi.txt
-rw-r--r-- 4 root supergroup 31 2020-04-03 16:46 /sanguo/shuguo/zhuge.txt
16 -tail:显示一个文件的末尾
[root@master hadoop-2.7.2]# hadoop fs -tail /sanguo/shuguo/kongming.txt
wo shi kong ming
wo shi liubei
17 -rm:删除文件或文件夹
[root@master hadoop-2.7.2]# hadoop fs -rm /sanguo/shuguo/kongming.txt
20/04/03 16:52:39 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted /sanguo/shuguo/kongming.txt
[root@master hadoop-2.7.2]# hadoop fs -ls /sanguo/shuguo
Found 2 items
-rw-r--r-- 4 root supergroup 62 2020-04-03 16:51 /sanguo/shuguo/zaiyiqi.txt
-rw-r--r-- 4 root supergroup 31 2020-04-03 16:46 /sanguo/shuguo/zhuge.txt
18 -rmdir:删除空目录
[root@master hadoop-2.7.2]# hadoop fs -mkdir /test
[root@master hadoop-2.7.2]# hadoop fs -ls /
Found 3 items
-rw-r--r-- 4 root supergroup 1366 2020-04-03 16:41 /README.txt
drwxr-xr-x - root supergroup 0 2020-04-03 16:35 /sanguo
drwxr-xr-x - root supergroup 0 2020-04-03 16:54 /test
[root@master hadoop-2.7.2]# hadoop fs -rmdir /test
[root@master hadoop-2.7.2]# hadoop fs -ls /
Found 2 items
-rw-r--r-- 4 root supergroup 1366 2020-04-03 16:41 /README.txt
drwxr-xr-x - root supergroup 0 2020-04-03 16:35 /sanguo
19 -du统计文件夹的大小信息
[root@master hadoop-2.7.2]# hadoop fs -du -s -h /sanguo/shuguo/zaiyiqi.txt
62 /sanguo/shuguo/zaiyiqi.txt
[root@master hadoop-2.7.2]# hadoop fs -du -h /sanguo/shuguo/
62 /sanguo/shuguo/zaiyiqi.txt
31 /sanguo/shuguo/zhuge.txt
20 -setrep:设置HDFS中文件的副本数量
[root@master hadoop-2.7.2]# hadoop fs -setrep 10 /sanguo/shuguo/zhuge.txt
Replication 10 set: /sanguo/shuguo/zhuge.txt

这里设置的副本数只是记录在NameNode的元数据中,是否真的会有这么多副本,还得看DataNode的数量。因为目前只有3台设备,最多也就3个副本,只有节点数的增加到10台时,副本数才能达到10。
