KMP算法
KMP算法是D.E.Knuth、J.H.Morris和V.R.Pratt共同提出的,简称KMP算法。 常用于在一个文本串S内查找一个模式串P 的出现位置,这个算法由Donald Knuth、Vaughan Pratt、James H. Morris三人于1977年联合发表,故取这3人的姓氏命名此算法。
下面先直接给出KMP的算法流程:
假设现在文本串S匹配到 i 位置,模式串P匹配到 j 位置
• 如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++,继续匹配下一个字符;
• 如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]。此举意味着失配时,模式串P相对于文本串S向右移动了j - next [j] 位。
• 换言之,当匹配失败时,模式串向右移动的位数为:失配字符所在位置 - 失配字符对应的next 值(next 数组的求解会在下文的1.3.3节中详细阐述),即移动的实际位数为:j - next[j],且此值大于等于1。
next 数组各值的含义:代表当前字符之前的字符串中,有多大长度的相同前缀后缀。例如如果next [j] = k,代表j 之前的字符串中有最大长度为k 的相同前缀后缀。
1. 最长前缀后缀
如果给定的模式串是:“ABCDABD”,从左至右遍历整个模式串,其各个子串的前缀后缀分别如下表格所示:
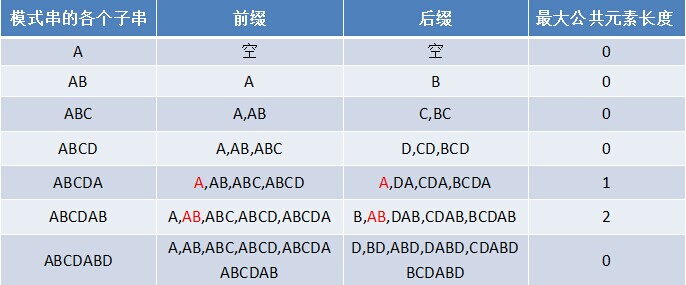
也就是说,原模式串子串对应的各个前缀后缀的公共元素的最大长度表为(下简称《最大长度表》):
