集群版一
在上一篇我们简单介绍了下Redis的使用,下面是时候集群环境下的Redis了。
集群的意义
Redis集群的出现势必是为了解决单机不可解决的问题,有哪些问题呢,简单总结如下:
- 在单机环境下,如果某一个Redis实例不可用,或者所有实例不可用,Redis无论是作为缓存还是作为数据库使用,都必然对业务造成很大影响,单点机器出现故障的概率还是很高的。
- Redis作为一个纯内存操作的应用,受OS限制,内存不可能无限扩大,如果我们需要同时缓存几十上百G的数据,单机环境无法提供支持
- 单机在机器性能非常好的情况下,QPS官方是在10-15w,但是考虑到有很多子线程任务,一般应该会低于10w,单机无法支持高并发环境。
CAP原则
也称CAP定理,即在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼。举个例子,强一致性与可用性是一对冤家,无法共存,下面会有介绍。Redis集群实现的是AP。
集群实现方案
1.解决单点故障问题
既然一台机器不可靠,那就多搞几台嘛。水平扩展Redis服务器不是就解决了问题嘛,同时还能顺带着解决下性能问题: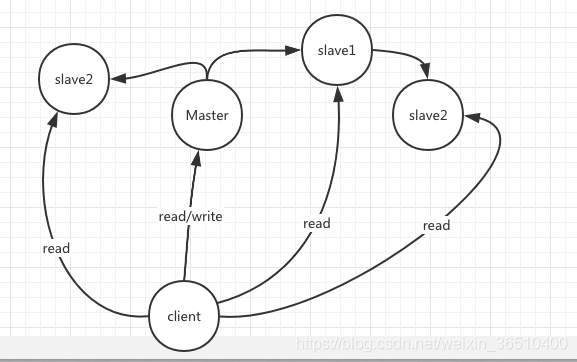
一台Master外挂n台salve,每个salve理论上持有Master的全量数据,相当于Master有n个镜像,当Master down了之后,slave仍旧可以持有完整数据对外提供服务,还能支持读写分离,想想还有点小激动呢。
首先解释两个名词:
- 主从
简单理解就是,client即可以与主机连接,还可以和从机连接 - 主备
备,即备份机,client是无法与备机进行连接,只有主机down了之后,备机替代主机功能才可以连接
一般主机可以读写,从机只能读。
附带出现的新问题
一致性问题
先冷静一下,该如何让每个slave持有完整的数据呢?数据一致性的问题就这么出现了,下面换个简化图示例:
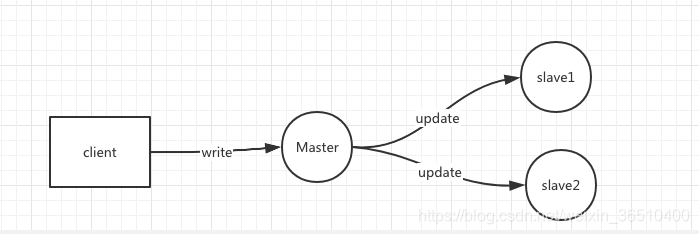
client向Matser写入一条数据,然后Master向两台slave同步数据。假设现在slave1接收到同步请求,并完成数据同步,slave2因网络波动,根本就美欧收到请求,或者接收到轻轻,但是数据同步期间发生错误,实际没有完成同步操作,那么现在就出现了这么一种情况,Master和slave1数据时最新的,但是slave2压根儿就没有这条数据。假设当前突发状况,Master和slave1都down了,只剩下了slave2可以对外提供服务,此时,这笔新插入的数据就这么丢失了。
既然水平扩展出现了一些问题,那就撸起袖子往下干吧。大致有这么几种方案(下面内容属于延伸扩展):
强一致性
很好理解,要么三台机器全部成功,要么全部失败。现在client给Master发送一条写指令,Master写入成功了,下面给两台slave同步数据,因为Redis是单进程的,为了实现强一致性,Master只能是阻塞等待两台slave同步的结果,如果两台都回复Master成功,ok,一次写入完成。如果slave1通知同步完成,slave2通知失败,或者半天过去了,都没给出同步结果,那Master只能认为此次同步失败了,为了强一致性,要么重试,要么将已经成功的数据撤销。但是不论是撤销数据,还是重试(此时线程还阻塞着呢),对于client来讲相当于是服务不可用。由此可见,愿景很美好,但是代价实在是太大了,严重破坏可用性。
弱一致性
既然可用性怎么娇气,那肯定不能使用同步阻塞了,哎,那就换成异步通知呗。当client数据到达Master之后,Master成功就行,然后Master异步通知两个slave进行数据同步,但是无法保证两个slave的数据能完全和Master一致。
最终一致性
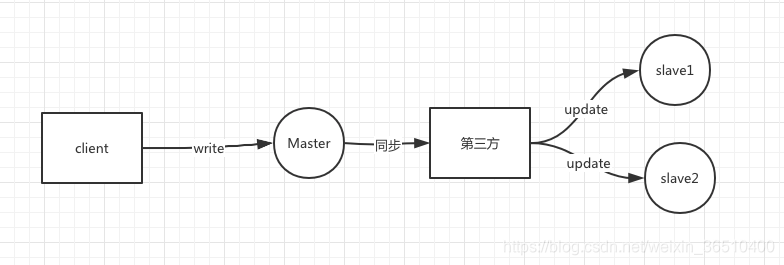
假若有一个可靠的第三方,Master将数据同步提交(响应必须足够快),获得第三方回执后即可认为数据同步成功,slave1,slave2的具体同步操作,由第三方异步的去更新,保证最终两台从机都能update。
数据读取问题
Redis读写分离后,假设Master已经更新数据,但是slave还没有来得及完成更新。现有两个client,一个从Master读取数据,一个从slave读取数据,完蛋了,一个读出了新数据,另一个读的是老数据。
Master单点问题
无论是主从还是主备,都离不开一个主机Master,问题来了,这个Master本身,还是一台单点机器,问题又回到原点了…
Redis是如何实现的呢?
解决Master单点问题
想象一下如果是一个人,如何判断一台Master是否可用呢?很简单,与Master建立通信,判断Master是否可以提供服务。下面,可以给大家介绍下哨兵(Sentinel)了:
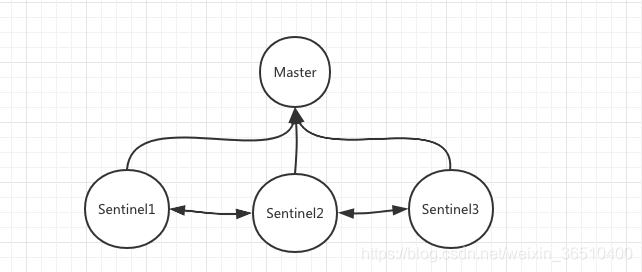
相信聪明的你一定注意到了上面哨兵我画了3个,为什么不是1个,也不是两个呢?
首先我们要明确哨兵存在的意义,是为了解决Master的单点问题,说直白一点,就是监控当前的Master是否存活,是否可以提供服务。
假设现在一个Master只有一个哨兵监控,如果某一个时间点哨兵与Master之间出现网络波动,哨兵认为Master down了,启动灾备,将一台slave切换成了新Master,其实老Master好好的,这便出现了典型的网络分区问题,一部分连接仍旧和老Master保持联系,一部分新连接则和新Master进行交互,产生不一致。
既然只有一个哨兵不可行,再加一个哨兵会怎么样呢?假使在某一时刻一个哨兵连接出现问题,判定Master出现问题,而另外一个哨兵与Master保持着正常连接,判断Master好好的,一个认为down了,一个认为没问题,到底该听谁的呢?很明显,仅仅两个哨兵也不可行。
至少需要三个哨兵去监控一个Master,当超过其中一半数+1的哨兵认为Master down了,即投票数大于当前哨兵的一半,才可以认为Master是真的down了,应该启动灾备了。
关于哨兵这块,本章节不扩展开来讲了,后续有专门章节详解哨兵是如果工作,如何发起救援的。
Redis的实现
下面我们以一个简单的小demo来看下Redis是如何实现数据同步的:
环境:mac os
工具:shell,docker(本人比较懒,不想配置一大堆东西,使用docker容器的默认配置)
说明:本demo使用Redis使用默认配置,修改配置后的结果,与本demo会有些许不一样。
1.首先,我们在本机模拟建立一个Redis集群环境。首先启动4个空白shell:
2.从左到右的4个shell中,分别输入如下命令(为了演示效果,我们让Redis实例进行前端阻塞运行):
左上:
docker run --name master -p 6379:6379 redis
右上:
docker run --name slave1 -p 6380:6380 redis
左下:
docker exec -ti master redis-cli
右下:
docker exec -ti slave1 redis-cli
效果如图:

我们顺利的启动了两台Redis实例,一个是6379,一个是6380,
同时启动了两个客户端,一个连接实例6379,一个连接实例6380
同时,由于docker的沙箱机制,两个容器之间是不能通信的,我们下面建立一个网桥用于实例之间的双向通信:
docker network create -d bridge myBridge
docker network connect myBridge master
docker network connect myBridge slave1
ok,至此,我们的准备工作都已经全部完成。
3.为了演示,我们现在6379中添加部分key:

4.将6380设置为6379的slave
在连接6380的客户端中使用跟随命令:
replicaof 172.17.0.2 6379
ok,执行完毕,我们现在来看下4个shell的显示界面

在Master的shell中,我们可以看到Master在slave成功连接之后,进行了这么几件事情:使用copy-on-write方式,新起了一个后台线程23执行bgsave(即生成当前Master中全量RDB文件),完成之后,将RDB文件用SYNC命令发送给了slave。
在slave的shell中,我们可以看到,与Master建立连接之后,开始建立SYNC通道,发送ping到Master验证连接是否通畅,在接收到Master发送过来的RDB数据之后,首先清空了自己的老数据,然后加载RDB数据进入内存。
我们来看下效果:
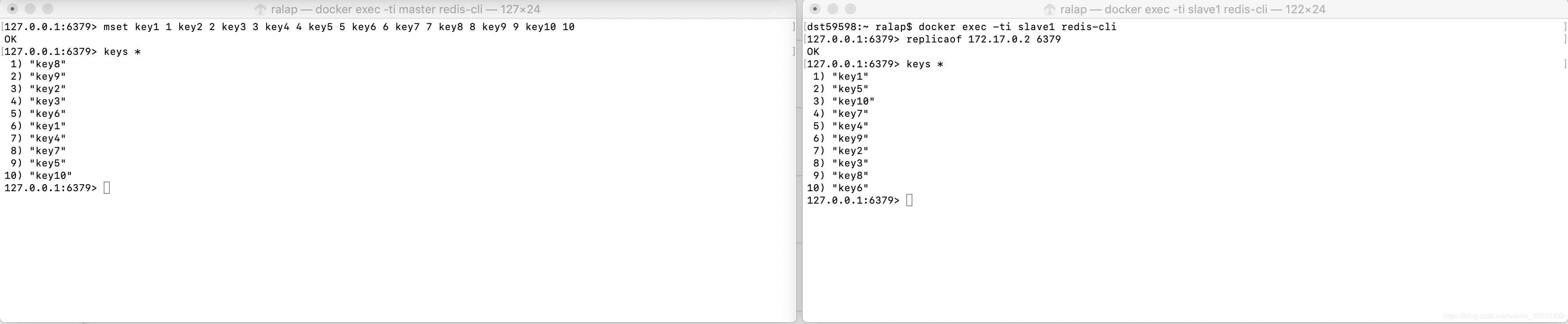
至此,Master与slave之间,完成了一次全量数据的同步。
5.增量数据同步:
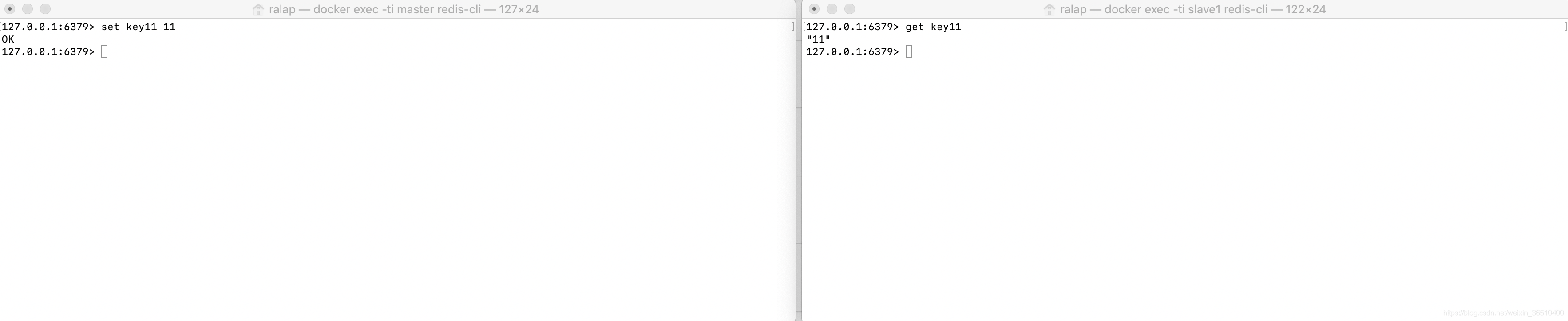
我们在Master中再新增一个key11,然后去slave中查看,可以看到key11已经同步到了slave中
下面我们总结下Redis的主从复制逻辑:
- 全量数据同步:
一般使用场景为slave新连接进Master,或者slave down很长时间,恢复之后重新与Master建立连接。
全量同步,是需要使用RDB文件的,默认是先将生成的RDB文件保存在磁盘上,等RDB文件全部生成完毕之后,再发送给slave。所以性能会受到磁盘速度的限制,可以在conf中添加配置:repl-diskless-sync no,将生成的RDB文件不落磁盘,直接通过网络形式发送给slave。
至于数据同步过程,上面的demo中已经有了详细过程,这里就不做过多说明了。
另外,说明一点,在slave删除自身旧数据,加载新数据的过程中,默认是阻塞进行的,可以在conf中配置异步进行,在这段时间内,slave仍响应请求,同时以旧数据返回,但是加载新数据集的操作只能是在主线程中,会阻塞salve。 - 增量同步:
增量同步相较于全量同步,会稍微复杂一些。
我们先看下Master和slave下都有哪些信息:
输入"info replication"
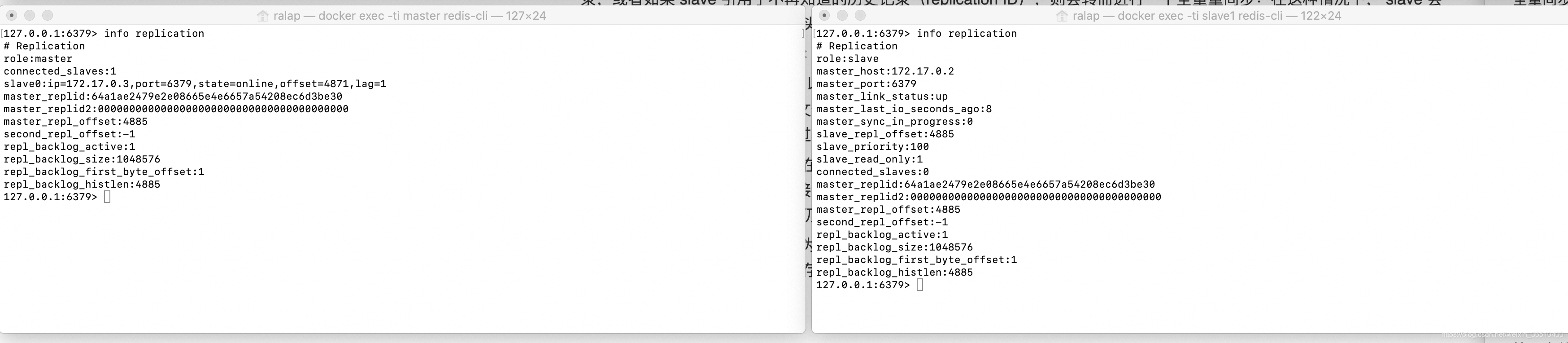
我们可以看到,在Master中,有当前自己的replication ID,以及自己的数据偏移量offset,而在slave中,不仅有自己的replication ID,还有Master的replid以及Master的offset,这些便是最近一次Master同步数据的信息。
Master将自身的复制流传给slave时,发送多少字节的数据,自身的偏移量offset就会增加多少,目的是当有新的操作修改自己的数据集时,它可以用offset去更新slave的状态。基本上每一对replication ID和offset,可以确定一个确切的数据版本。
当salve连接到Master之后,使用PSYNC命令发送他们记录的旧的master replicationID和它们至今为止处理的offset,这样Masetr便可以知道,应该从哪个数据开始,将其后续的数据同步给slave
假设这样一个问题,如果slave最近的同步时间是一小时前,在这1小时内,Master已经更新4G的数据,当slave再次进行同步的时候,是否还是这样同步呢?答案不是。
从上面的图中,我们可以看到一个叫"repl_backlog_size"的信息,这个便是Master的操作命令缓冲区,大小时可以配置的,为了便于理解,可以将它想象成一个环状的内存空间:
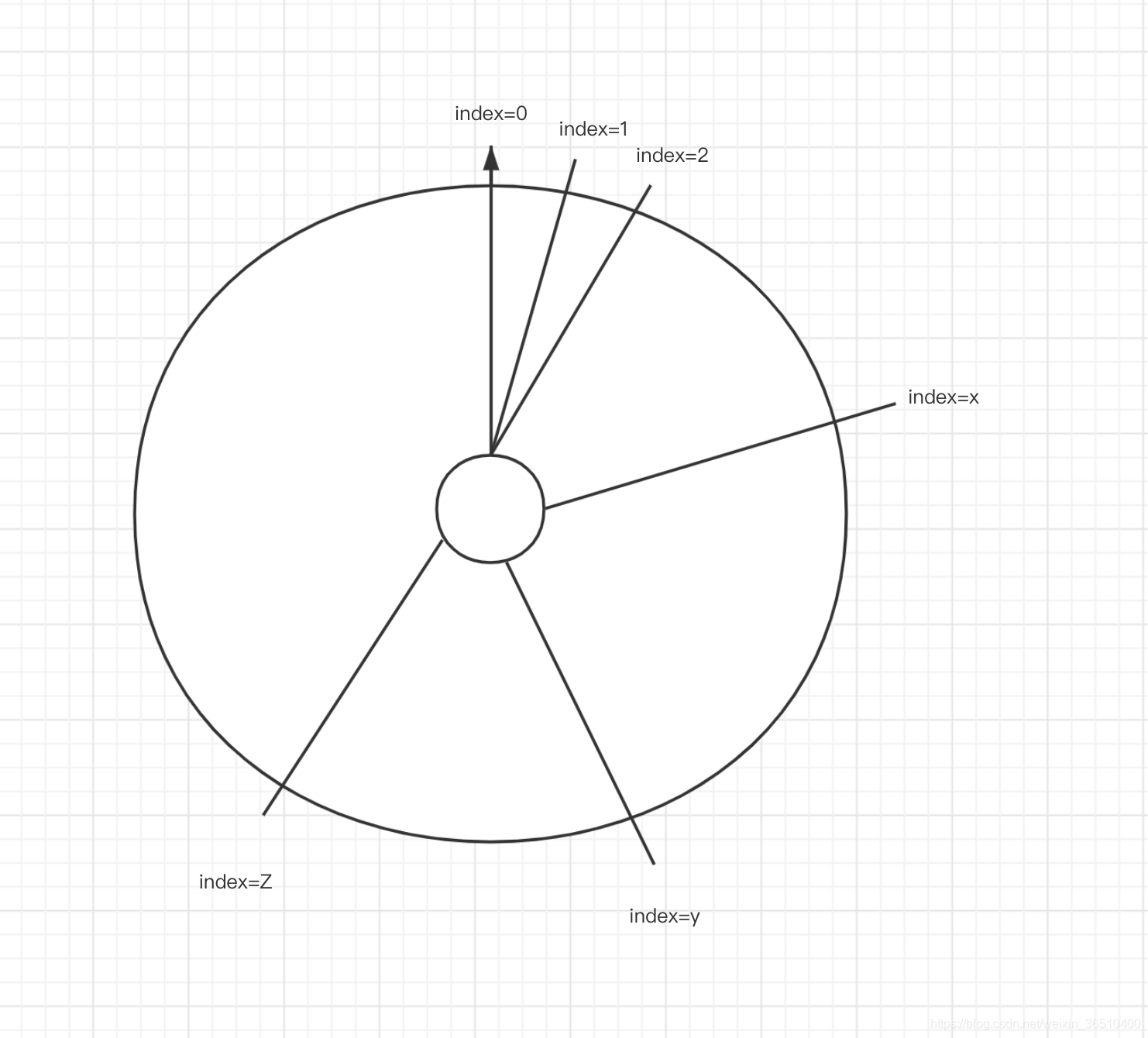
从index=0开始,来一条指令,往环内填入数据,直到填满整个环状内存,后续再来一条命令,将之前index=0的地方开始,将老的指令替换为新的指令。
当slave携带offset信息过来之后,Master会根据这个offset,去指令缓冲区内寻找相应的偏移量,如果在缓冲区内找到了,则将其后续指令同步给slave,如果在缓冲区内没有找到相应的偏移量,则进行RDB全量数据同步。
slave默认是只读模式,可以通过conf调整为读写模式。
主从模式下,Redis由于是异步复制,所以无法确保每个slave都收到了数据,总会有数据丢失的可能,这需要看具体的使用场景是否能够容忍,考研网络分区的容忍度。
另外,Redis支持部分一致性,通过配置:
min-replicas-to-write xxx
min-replicas-max-lag xxx
设置最小的slave写入成功的数据,以及相互之间通信的最大超时时间。比如xxx配置为3,只有当最少3台salve都写入成功了,这条数据才会认为写入成功,最终进入Redis数据集。
1.解决Redis容量问题
篇幅有限,在后续的Redis分区章节进行讲解,敬请期待。
