本文章为《深入浅出 Java 虚拟机》系列课程学习笔记,侵删。学习地址为 深入浅出 Java 虚拟机
1 引言
垃圾回收器一般使用默认参数,就可以比较好的运行。但如果用错了某些参数,那么后果可能会比较严重。
如果你的应用程序目前已经满足了需求,那建议不要再随便动这些参数了。另外,优化代码获得的性能提升,远远大于参数调整所获得的性能提升,不要纯粹为了调参数而走了弯路。
那么,GC 优化的目标是什么呢?其实可以总结为以下三点:
- 系统容量
- 延迟
- 吞吐量
2 系统容量
假如你的内存是无限大的,那么无论是存活对象,还是垃圾对象,都不需要额外的计算和回收,你只需要往里放就可以了。这样,就没有什么吞吐量和延迟的概念了。
但其实,越是资源限制比较严格的系统,对它的优化就会越明显。通常在一个资源相对宽松的环境下优化的参数,平移到另外一个限制资源的环境下,并不是最优解。
3 吞吐量、延迟
吞吐量大不代表响应能力高,吞吐量一般这么描述:在一个时间段内完成了多少个事务操作;在一个小时之内完成了多少批量操作。
响应能力是以最大的延迟时间来判断的,比如:一个桌面按钮对一个触发事件响应有多快;需要多长时间返回一个网页;查询一行 SQL 需要多长时间,等等。
这两个目标,在有限的资源下,通常不能够同时达到,我们需要做一些权衡。
4 如何选择垃圾回收器
- 如果你的堆大小不是很大(比如 100MB),选择串行收集器一般是效率最高的。参数:-XX:+UseSerialGC
- 如果你的应用运行在单核的机器上,或者你的虚拟机核数只有 1C,选择串行收集器依然是合适的,这时候启用一些并行收集器没有任何收益。参数:-XX:+UseSerialGC
- 如果你的应用是“吞吐量”优先的,并且对较长时间的停顿没有什么特别的要求。选择并行收集器是比较好的。参数:-XX:+UseParallelGC
- 如果你的应用对响应时间要求较高,想要较少的停顿。甚至1秒的停顿都会引起大量的请求失败,那么选择 G1、ZGC、CMS 都是合理的。虽然这些收集器的 GC 停顿通常都比较短,但它需要一些额外的资源去处理这些工作,通常吞吐量会低一些。参数:-XX:+UseConcMarkSweepGC、-XX:+UseG1GC、-XX:+UseZGC 等
从上面这些出发点来看,我们平常的 Web 服务器,都是对响应性要求非常高的。选择性其实就集中在 CMS、G1、ZGC 上。
而对于某些定时任务,使用并行收集器,是一个比较好的选择。
5 大流量应用
这是一类对延迟非常敏感的系统。吞吐量一般可以通过堆机器解决。
假如某个接口一天有 10 亿次请求,每秒的峰值大概也就 5~6 w/秒,虽然不算是很大,但也不算小。
一般达到这种量级的系统,承接请求的都不是一台服务器,接口都会要求快速响应,一般不会超过 100ms。
这种系统,一般都是社交、电商、游戏、支付场景等,要求的是短、平、快。长时间停顿会堆积海量的请求,所以在停顿发生的时候,表现会特别明显。我们要考量这些系统,有很多指标。
- 每秒处理的事务数量(TPS)
- 平均响应时间(AVG)
- TP 值,比如 TP90 代表有 90% 的请求响应时间小于 x 毫秒
其中我们重点了解一下 TP 值,它最能代表系统中到底有多少长尾请求,这部分请求才是影响系统稳定性的元凶。大多数情况下,GC 增加,长尾请求的数量也会增加。
我们的目标,就是减少这些停顿。本文章假定使用的是 CMS 垃圾回收器。
6 调优
假设每次请求的大小有 20KB,这个接口每天有 10 亿次请求,那么一天的流量就有 18TB 之巨。假如高峰请求 6w/s,我们部署了 10 台机器,那么每个 JVM 的流量就可以达到 120MB/s,这个速度算是比较快的了。
假设我们的机器是 4C 8GB 的,分配给了 JVM 10248GB/32= 5460MB 的空间。那么年轻代大小就有 5460MB/3=1820MB。进而可以推断出,Eden 区的大小约 1456MB,那么大约只需要 12 秒,就会发生一次 Minor GC。不仅如此,每隔半个小时,会发生一次 Major GC。
不管是年轻代还是老年代,这个 GC 频率都有点频繁了。
可以算一下我们的 Survivor 区大小,大约是 182MB 左右,如果稍微有点流量偏移,或者流量突增,再或者和其他接口共用了 JVM,那么这个 Survivor 区就已经装不下 Minor GC 后的内容了。总有一部分超出的容量,需要老年代来补齐。这些垃圾信息就要保存更长时间,直到老年代空间不足。
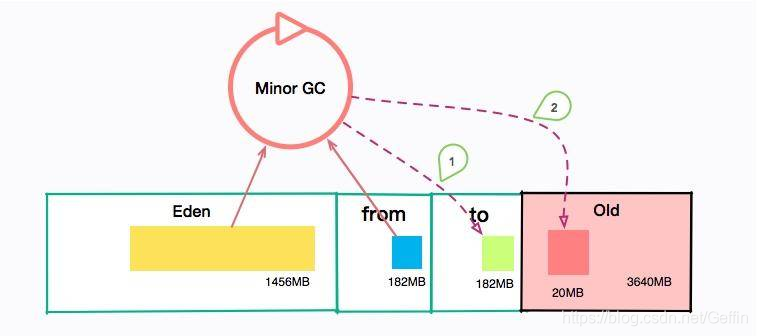
我们发现,用户请求完这些信息之后,很快它们就会变成垃圾。所以每次 MinorGC 之后,剩下的对象都很少。
也就是说,我们的流量虽然很多,但大多数都在年轻代就销毁了。如果我们加大年轻代的大小,由于 GC 的时间受到活跃对象数的影响,回收时间并不会增加太多。
如果我们把一半空间给年轻代。也就是下面的配置:
-XX:+UseConcMarkSweepGC -Xmx5460M -Xms5460M -Xmn2730M
重新估算一下,发现 Minor GC 的间隔,由 12 秒提高到了 18 秒。
Minor GC 有所改善,但是并没有显著的提升。相比较而言,Major GC 的间隔却增加到了 3 小时,是一个非常大的性能优化。这就是在容量限制下的初步调优方案。
但是这有一个问题,由于每秒的请求都非常大,如果应用重启或者更新,流量瞬间打过来,JVM 还没预热完毕,这时候就会有大量的用户请求超时、失败。
为了解决这种问题,通常会逐步的把新发布的机器进行放量预热。比如第一秒 100 请求,第二秒 200 请求,第三秒 5000 请求。大型的应用都会有这个预热过程。
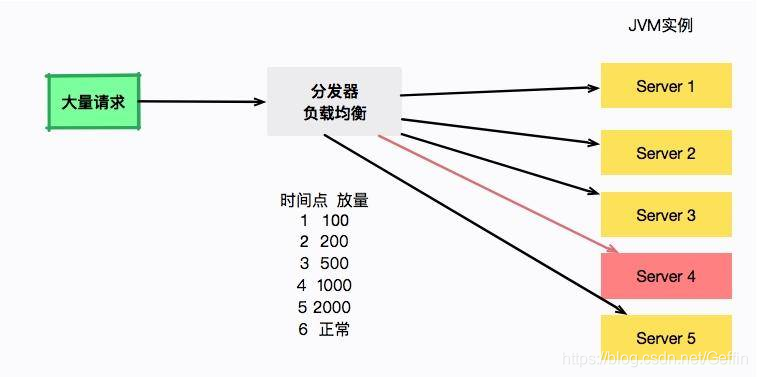
如图所示,负载均衡器负责服务的放量,server4 将在 6 秒之后流量正常流通。但是奇怪的是,每次重启大约 20 多秒以后,就会发生一次诡异的 Full GC。
注意是 Full GC,而不是老年代的 Major GC,也不是年轻代的 Minor GC。事实上,经过观察,此时年轻代和老年代的空间还有很大一部分,那 Full GC 是怎么产生的呢?
一般,Full GC 都是在老年代空间不足的时候执行。但不要忘了,我们还有一个区域叫作 Metaspace,它的容量是没有上限的,但是每当它扩容时,就会发生 Full GC。
事实上,MetaspaceSize 的大小大约是 20MB。这个初始值太小了。现在很多类库,包括 Spring,都会大量生成一些动态类,20MB 很容易就超了,我们可以试着调大这个数值。按照经验,一般调整成 256MB 就足够了。同时,为了避免无限制使用造成操作系统内存溢出,我们同时设置它的上限。
经观察,启动后停顿消失。
这种方式通常是行之有效的,但也可以通过扩容机器内存或者扩容机器数量的办法,显著地降低 GC 频率。这些都是在估算容量后的优化手段。
7 总结
其实,如果没有明显的内存泄漏问题和严重的性能问题,专门调优一些 JVM 参数是非常没有必要的,优化空间也比较小。
所以,我们一般优化的思路有一个重要的顺序:
- 程序优化,效果通常非常大
- 扩容,能用钱解决的问题不算问题
- 参数调优,在成本、吞吐量、延迟之间找一个平衡点
我们的业务场景是高并发的。对象诞生的快,死亡的也快,对年轻代的利用直接影响了整个堆的垃圾收集。
- 足够大的年轻代,会增加系统的吞吐,但不会增加 GC 的负担
- 容量足够的 Survivor 区,能够让对象尽可能的留在年轻代,减少对象的晋升,进而减少 Major GC
我们还看到了一个元空间引起的 Full GC 的过程,这在高并发的场景下影响会格外突出,尤其是对于使用了大量动态类的应用来说。通过调大它的初始值,可以解决这个问题。
