一、ArrayList和Vector的区别?如何理解Vector的线程安全?
共同点
1、两者都实现了List接口,并且属于有序存储集合,可根据索引直接取值。
2、允许集合内的元素重复或为Null。
区别
1、ArrayList是线程不安全的,Vector是线程安全的(Vector类中所有自带方法都是线程安全的,因为方法都使用synchronized关键字标注)
2、Vector扩容后会增长原来的一倍,ArrayList增长原来的0.5倍。
此外,关于Vector的线程安全问题,很多人都称之为“有条件的线程安全”,它对于单独的操作可以是线程安全的,但是某些操作序列可能需要外部同步。举个例子,假如我们定义如下删除Vector中最后一个元素方法,
public Object deleteLast(Vector v){
int lastIndex = v.size()-1;
v.remove(lastIndex);
}这是一个复合操作,其中包括size()和remove(),一旦多线程进行访问,有可能会抛出数据越界的异常。当然了,我们同样可以用 synchronized来修饰这个方法,但是synchronized 的开销是很大的。为了保证线程的安全以及资源的合理利用,可以采用如下方法初始化ArrayList。
List<Map<String,Object>> data=Collections.synchronizedList(new ArrayList<Map<String,Object>>());二、简述ArrayList与LinkedList的使用场景以及原因?
线程安全性方面,ArrayList与LinkedList都是线程不安全的。
1、数据查询检索方面
ArrayList它支持索引直接访问的方式(随机访问),而LinkedList则需要遍历整个链表来获取对应的元素。因此一般来说ArrayList的访问速度是要比LinkedList要快的。这是由两者底层的存储结构决定的,ArrayList的底层是数组,LinkedList的底层是双向链表。
2、数据修改方面
ArrayList由于是数组,对于删除和修改而言消耗是比较大(复制和移动数组实现),偶尔可能会导致对数组重新进行分配;LinkedList是双向链表删除和修改只需要修改对应的指针即可,消耗是很小的。因此一般来说LinkedList的增删速度是要比ArrayList要快的。
但是,ArrayList的增删未必就是比LinkedList要慢。
若增删都是在末尾来操作【每次调用的都是remove()和add()】,此时ArrayList就不需要移动和复制数组来进行操作了。如果数据量有百万级的时,速度是会比LinkedList要快的。
若删除操作的位置是在中间。由于LinkedList的消耗主要是在遍历上,ArrayList的消耗主要是在移动和复制上(底层调用的是arraycopy()方法,是native方法),所以ArrayList会相对快一些。
三、HashMap和Hashtable的区别?
共同点:
都是实现Map接口,并且都采用键值对的形式存取
区别:
1、同步性(重点)
HashMap线程不安全的,而Hashtable是线程安全的。在多线程并发场景下,往往不用Hashtable,而使用ConcurrentHashMap的锁分段技术,它的实现原理是首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。使用方式如下:
Map<String,String> myMap = new ConcurrentHashMap<String,String>();2、是否允许为null
HashMap对象的key、value值均可为null;而HahTable对象的key、value值均不可为null。且两者的key值均不能重复,若添加key相同的键值对,后面的value会自动覆盖前面的value,但不会报错。
3、contains方法
Hashtable有contains方法,HashMap把Hashtable的contains方法去掉了,改成了containsValue和containsKey
4、继承不同:
HashMap<K,V> extends AbstractMap<K,V>
public class Hashtable<K,V> extends Dictionary<K,V>
想要更加深入了解HashMap以及线程安全的同学,可以拜读一下这几篇文章:
1、来自美团点评技术团队Java 8系列之重新认识HashMap
四、Set里的元素是不能重复的,那么添加元素时,用什么方法来去重? 是用==还是equals()?
HashSet中元素的存储原理(哈希算法)
当向Set中添加对象时,首先调用此对象所在类的hashCode()方法,计算次对象的哈希值,此哈希值决定了此对象在Set中存放的位置;若此位置没有被存储对象则直接存储,若已有对象则通过对象所在类的equals()比较两个对象是否相同,相同则不能被添加。
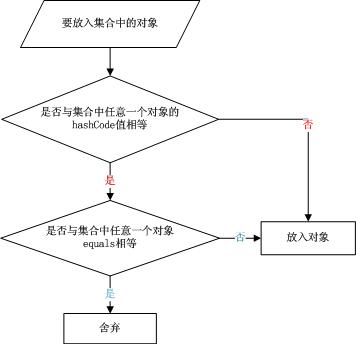
下面通过解读HashSet中add的源代码,更加直观的看到算法过程:
//添加元素
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
//map中put方法的源代码
public V put(K key, V value) {
if (key == )
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != ; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key |||| key.equals(k)) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return ;
}从源代码中可以看出,HashSet的add方法实际上实现的是map对象的put方法,在put方法中不仅用到了==方法,还有equals方法,用==比较的是hashcode的值,而用equals比较的则是对象的具体内容,所以两个方法都用到了。
五、Java中HashMap的key值要是为类对象则该类需要满足什么条件?
需要同时重写该类的hashCode()方法和它的equals()方法。
- 从源码可以得知,在插入元素的时候是先算出该对象的hashCode。如果hashcode相等话的。那么表明该对象是存储在同一个位置上的。
- 如果调用equals()方法,两个key相同,则替换元素
- 如果调用equals()方法,两个key不相同,则说明该hashCode仅仅是碰巧相同,此时是散列冲突,将新增的元素放在桶子上
一般来说,我们会认为:只要两个对象的成员变量的值是相等的,那么我们就认为这两个对象是相等的!因为,Object底层比较的是两个对象的地址,而对我们开发来说这样的意义并不大~这也就为什么我们要重写equals()方法
重写了equals()方法,就要重写hashCode()的方法。因为equals()认定了这两个对象相同,而同一个对象调用hashCode()方法时,是应该返回相同的值的!
六、Collection、Collections以及CollectionUtils的区别?以及CollectionUtils的常用方法?
1、Collection是集合的上级接口,继承它的有Set和List接口
2、Collections是集合的工具类,提供了一系列的静态方法对集合的搜索、查找、同步等操作
3、而CollectionUtils是apache common包下的一个工具类,对于集合也有一系列的操作
CollectionUtils的常用方法列举:
//1、判断集合是否为空,如果为空返回false
CollectionUtils.isEmpty(null)
CollectionUtils.isEmpty(new ArrayList())
CollectionUtils.isEmpty({a,b})
//2、判断集合是否不为空,如果不为空返回true
CollectionUtils.isNotEmpty(null)
CollectionUtils.isNotEmpty(new ArrayList())
CollectionUtils.isNotEmpty({a,b})
//2个集合间的操作:
//集合a: {1,2,3,3,4,5}
//集合b: {3,4,4,5,6,7}
//(并集): {1,2,3,3,4,4,5,6,7}
CollectionUtils.union(a, b)
//(交集):{3,4,5}
CollectionUtils.intersection(a, b)
//(交集的补集):{1,2,3,4,6,7}
CollectionUtils.disjunction(a, b)
//(交集的补集): {1,2,3,4,6,7}
CollectionUtils.disjunction(b, a)
//(A与B的差):{1,2,3}
CollectionUtils.subtract(a, b)
// (B与A的差): {4,6,7}
CollectionUtils.subtract(b, a)七、Enumeration和Iterator接口的区别
大概的意思是:Iterator替代了Enumeration,Enumeration是一个旧的迭代器了。与Enumeration相比,Iterator更加安全,因为当一个集合正在被遍历的时候,它会阻止其它线程去修改集合。
- 我们在做练习的时候,迭代时会不会经常出错,抛出ConcurrentModificationException异常,说我们在遍历的时候还在修改元素。
- 这其实就是fail-fast机制~具体可参考博文:https://blog.csdn.net/panweiwei1994/article/details/77051261
区别有三点:
- Iterator的方法名比Enumeration更科学
- Iterator有fail-fast机制,比Enumeration更安全
- Iterator能够删除元素,Enumeration并不能删除元素
八、Iterator与ListIterator是什么关系,两者的优缺点有什么?
两者关系:
ListIterator继承了Iterator接口,它用于遍历List集合的元素。
区别
1、ListIterator有add()方法,可以向List中添加对象,而Iterator不能。
2、ListIterator和Iterator都有hasNext()和next()方法,可以实现顺序向后遍历。但是ListIterator有hasPrevious()和previous()方法,可以实现逆向(顺序向前)遍历。Iterator就不可以。也就是说Iterator是单向的,而ListIterator是双向的。
3、ListIterator可以定位当前的索引位置,nextIndex()和previousIndex()可以实现,Iterator 没有此功能。
4、都可实现删除对象,但是ListIterator可以实现对象的修改,set()方法可以实现。Iterator仅能遍历,不能修改。
九、ArrayList集合加入1万条数据,应该怎么提高效率
ArrayList的默认初始容量为10,要插入大量数据的时候需要不断扩容,而扩容是非常影响性能的。因此,现在明确了10万条数据了,我们可以直接在初始化的时候就设置ArrayList的容量!
这样就可以提高效率了~
