Dubbo+Kryo 实现高速序列化
Kryo 是一种非常成熟的序列化实现,已经在 Twitter、Groupon、Yahoo 以及多个著名开源项目(如 Hive、Storm)中广泛的使用。
在面向生产环境的应用中,目前更优先选择 Kryo.
启用Kryo
Provider 和 Consumer 项目启用 Kryo 高速序列化功能,两个项目的配置方式相同:
1、增加依赖(版本号,换成新的)
<dependency>
<groupId>de.javakaffee</groupId>
<artifactId>kryo-serializers</artifactId>
<version>0.42</version>
</dependency>
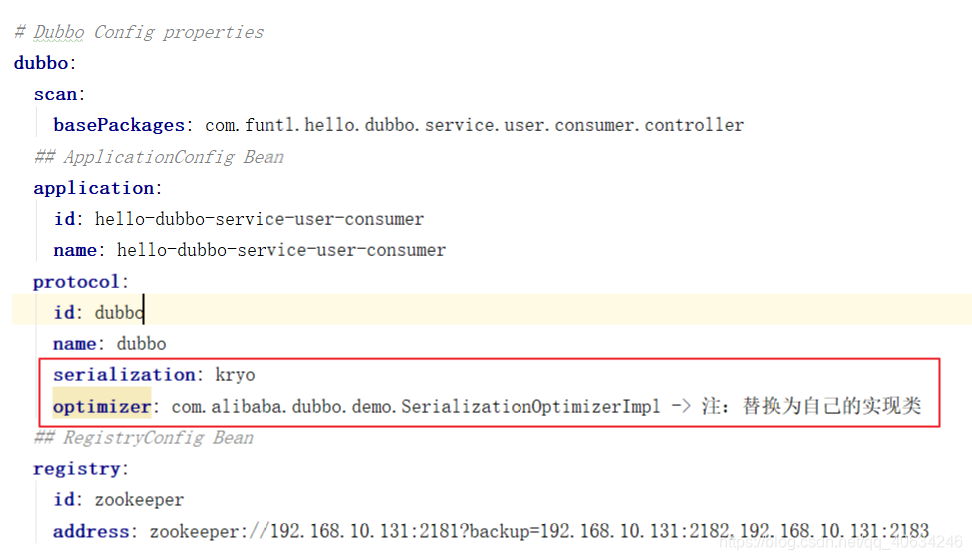
2、application.yml增加配置
protocol:
id: dubbo
name: dubbo
serialization: kryo
optimizer: 自己的实现类地址
3、注册被序列化类(实体类实现高速序列化)
要让 Kryo 和 FST 完全发挥出高性能,最好将那些需要被序列化的类注册到 dubbo 系统中,例如,我们可以实现如下回调接口:
public class SerializationOptimizerImpl implements SerializationOptimizer {
public Collection<Class> getSerializableClasses() {
List<Class> classes = new LinkedList<Class>();
classes.add(BidRequest.class);
classes.add(BidResponse.class);
classes.add(Device.class);
classes.add(Geo.class);
classes.add(Impression.class);
classes.add(SeatBid.class);
return classes;
}
}
由于注册被序列化的类仅仅是出于性能优化的目的,所以即使你忘记注册某些类也没有关系。
事实上,即使不注册任何类,Kryo 和 FST 的性能依然普遍优于 hessian 和 dubbo 序列化。
如果被序列化的类中 不包含无参的构造函数,则在 Kryo 的序列化中,性能将会大打折扣,因为此时我们在底层将用 Java 的序列化来透明的取代 Kryo 序列化。
所以,尽可能为每一个被序列化的类添加无参构造函数是一种最佳实践(当然一个 Java 类如果不自定义构造函数,默认就有无参构造函数)。另外,Kryo 和 FST 都不需要被序列化类实现 Serializable 接口,但我们还是建议每个被序列化类都去实现
Serializable 接口,因为这样可以保持和 Java 序列化以及 dubbo
序列化的兼容性,另外也使我们未来采用上述某些自动注册机制带来可能
建议:
(添加无参构造器)实体类 implement Serializable {} 和 kryo高速序列化,共同使用。
实体类 implement Serializable序列化的目的有两个:
第一个是便于存储,第二个是便于传输。
