title : spider with python
date : 2019.1.2
tool : RE & Python
文章目录
很早就对爬虫比较感兴趣,当我看到格式化的数据一排排展示在我的眼前的时候,我的内心真的很激动。本科阶段在大学也没好好学习,现在闲暇时间相对较多,重新捡起曾经感兴趣的东西,再拿起来做一做。
首先第一步先亮出自己的软件环境
OS : Linux Ubuntu 18.04
Language : Python 3.6.7
Lib : re, Pool(from multiprocessing), requests
今天我的分享是使用正则表达式将猫眼电影的top100,全部爬取下来,先使用简单的单进程,然后在使用进程池创建进程,使用多进程的方式完成秒爬数据。
前言:先看看正则表达式的使用方法
正则表达式,是一种长相稀奇古怪的“语言”,曾经有一句调侃正则表达式的话,是这么说的——“只要一个问题需要使用正则表达式,那么这就是两个问题了”!但是为什么我们现在还要使用这么不尽人意的奇怪东西呢,,真相只有一个,那就是真香啊!!
但是我们需要注意一点,在我们的Python中,书写正则表达式还是有点不同的。究竟是什么原因导致几乎所有的语言都有内置正则表达式的实现,那么我们接下来探讨一下正则表达式这个妖魔是怎么变成这样子的,——
ABC 12345+d!@#
对于以上的例子,如果我们需要提取其中的数字出来,使用一般的方法还真是只能一个问题一种操作,这就很马克思主义——具体问题具体分析,但是我们不能这样想问题,如果我们每一个特例都使用不同的解决方法,那这个问题只能说还没解决。直到我们拥有了正则表达式这个有力的武器:正则表达式。实际上,对于以上的问题,只要一行代码:
import re
string = 'ABC 12345+d!@#'
result = re.search('(\d+)', string)
print(result)
在正则表达式中,我们常用的有以下几个
\d : 数字 「0 - 9」
\w : 字符串str类型的
+ : 重复一次或多次
. : 匹配除开换行符的所有字符
* : 重复零次或多次
? : 可选
Python正则表达式,是在内置库re中提供的,有几个很好用的方法——
re.match(string[, pos[, endpos]]) # 必须从开头匹配,即需要在模式前添加'^'
re.search(string[, pos[, endpos]]) # 不必从开头匹配,只要匹配就好
re.findall(string[, pos[, endpos]]) # 找出所有的
有几个原则:
- 能用search坚决不用match,因为自由度高一点
- 一般使用非贪婪模式,注:
*是贪婪模式,?不是贪婪模式
匹配完成之后,我们将感兴趣的东西使用括号包围住,形成一个分组,然后调用group就可以获取它们,group尾数从1开始
例如:
html = '<p class="name"><a href="/films/1203" title="霸王别姬" data-act="boarditem-click" data-val="{movieId:1203}">霸王别姬</a></p>' import re content = re.match('^<p.*title="(\w+)".*', html) # content = re.search('<a.*title="(\w+)".*', html) print(content.group(1))霸王别姬
剩下的关于正则表达式的书写和具体的应用请参见官方文档或搜b站
正文:开始干正事
第一步:分析源站的网页结果和网站结构
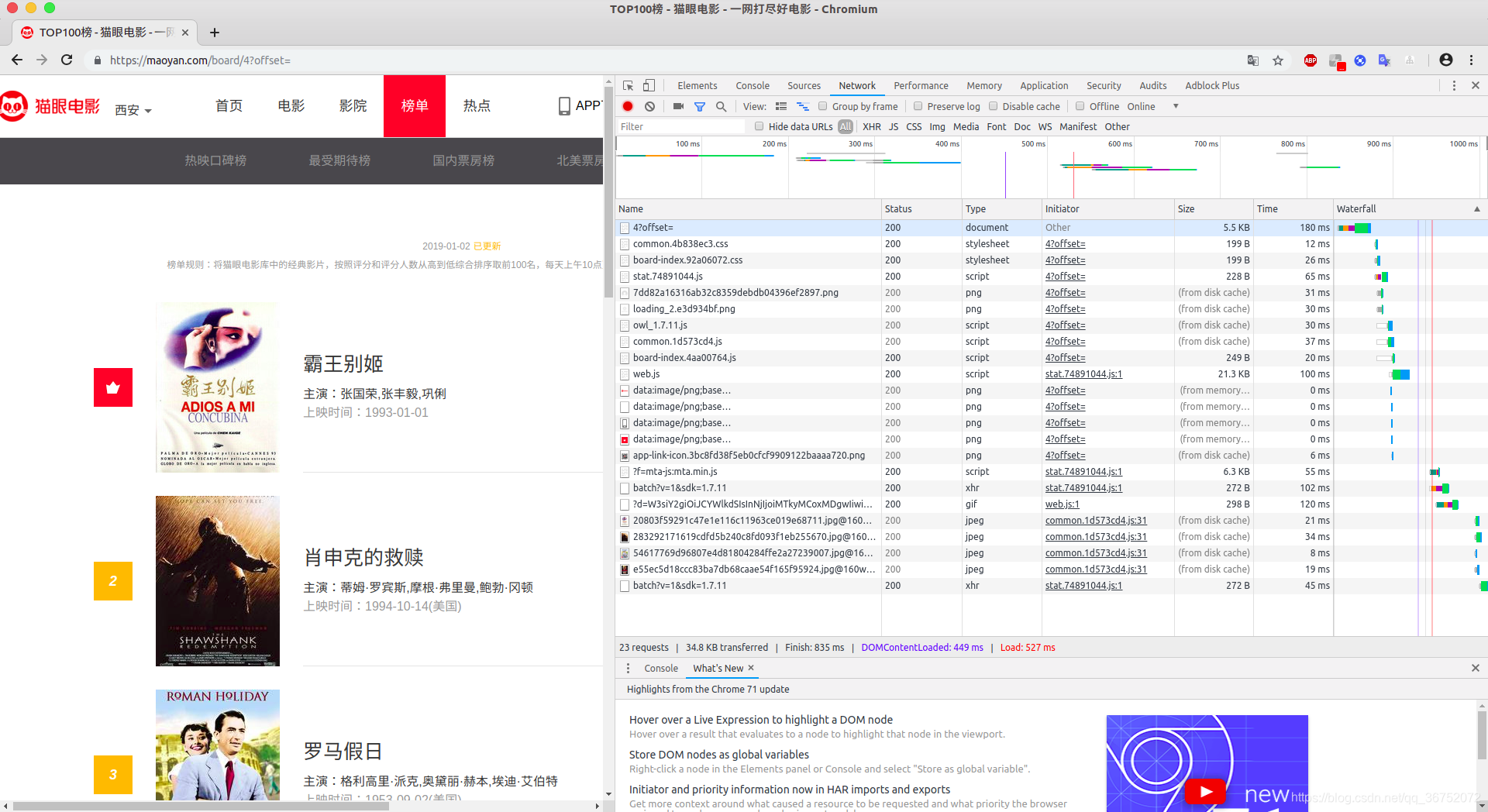
我们分析得知:他的这个猫眼站点top100是分成了10页,每一页是10部电影。不同的页面之间的差别仅仅是offset后面的数字,它们分别是(当前页数-1 * 10)。找到这个规律之后,我们访问每个站点就很容易了。我们先定义一个访问一个页面的函数——
def req_html(url):
try:
content = requests.get(url)
if content.status_code == 200:
return content.text
else:
return None
except RequestException: # 这是requests库里带的异常处理
return None
第二步:分析网页中我们感兴趣的点是怎样分布的

以上的截图显示了我们的感兴趣点,因为我们主要对电影名、主演、上映时间和评分比较感兴趣,剩下的我们就不敢兴趣了,根据以上的表达式我们可以作出以下的表达式
‘<p.?}">(\w+).?class=“star”>(.?)
.?“releasetime”>(. ?).?“integer”>(\d.).*?“fraction”>(\d)’
这样我们就实现了对其中相关信息的抓取,然后我们将一页中的信息写函数——
def parse_one_page(html):
pattern = re.compile('<p.*?}">(\w+)</a>.*?class="star">(.*?)</p>.*?"releasetime">(.*?)</p>.*?"integer">(\d.)</i>.*?"fraction">(\d)</i>', re.S) # 这个方法是为了正则表达式的复用,将正则表达式编译成一个对象
info = re.findall(pattern, html)
# print(type(info))
for j in info:
yield {
'title' : j[0],
'actor' : j[1].strip()[3:],
'time' : j[2].strip()[5:],
'rate' : j[3] + j[4]
}
总体来说,我们完成了这个页面的爬取和解析——
第三步:将整个所有信息一起爬
这个就比较简单了——
def main(url):
content = req_html(url)
for result in parse_one_page(content):
print(result)
if __name__ == '__main__':
for i in range(10):
urli = url + str(i * 10)
main(urli)
第四步:为了使爬虫效果好,实现秒爬
def main(url):
content = req_html(url)
for result in parse_one_page(content):
print(result)
if __name__ == '__main__':
pool = Pool()
pool.map(main, [url + str(i * 10) for i in range(10)])
最终的代码如下:
import re
import requests
from multiprocessing import Pool
from requests.exceptions import RequestException
url = 'https://maoyan.com/board/4?offset='
def req_html(url):
try:
content = requests.get(url)
if content.status_code == 200:
return content.text
else:
return None
except RequestException:
return None
def parse_one_page(html):
pattern = re.compile('<p.*?}">(\w+)</a>.*?class="star">(.*?)</p>.*?"releasetime">(.*?)</p>.*?"integer">(\d.)</i>.*?"fraction">(\d)</i>', re.S)
info = re.findall(pattern, html)
for j in info:
yield {
'title' : j[0],
'actor' : j[1].strip()[3:],
'time' : j[2].strip()[5:],
'rate' : j[3] + j[4]
}
def main(url):
content = req_html(url)
for result in parse_one_page(content):
print(result)
if __name__ == '__main__':
pool = Pool()
pool.map(main, [url + str(i * 10) for i in range(10)])
最终的结果展示:

