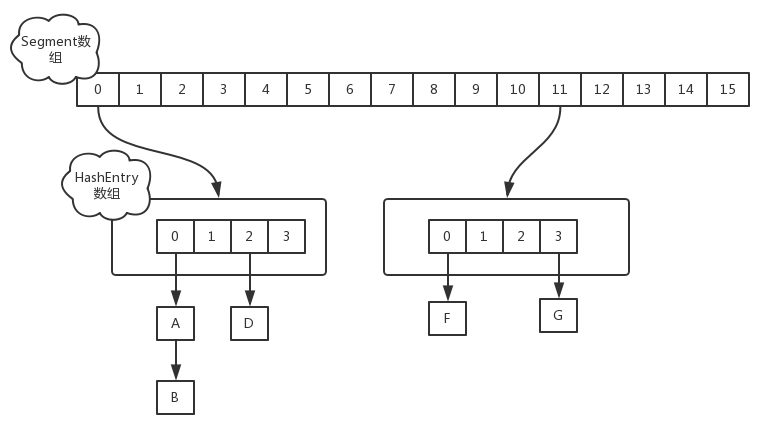
hashMap在1.7版本时使用的是哈希表(数组+链表),Java中采用链表的方式来解决hash冲突的。一个segment元素相当于一个hashMap,一个HashMap的数据结构看起来类似下图:

实现了同步的HashTable也是这样的结构,它的同步是使用锁来保证的,并且所有同步操作使用的是同一个锁对象。这样若有n个线程同时在get时,这n个线程要串行的等待来获取锁。
ConcurrentHashMap中对这个数据结构,针对并发稍微做了一点调整。它把区间按照并发级别(concurrentLevel),分成了若干个segment。默认情况下内部按并发级别16来创建。对于每个segment的容量,默认情况也是16。当然并发级别(concurrentLevel)和每个段(segment)的初始容量都是可以通过构造函数设定的。
创建好默认的ConcurrentHashMap之后,它的结构大致如下图:

1.2ConcurrentHashMap的初始化
if (concurrencyLevel > MAX_SEGMENTS) concurrencyLevel = MAX_SEGMENTS; int sshift = 0; int ssize = 1; while (ssize < concurrencyLevel) {//如果ssize小于concurrentcylevel并发级别,则一直进行++,concurrentcylevel可以自定义,也可使用默认值16 ++sshift; ssize <<= 1; } segmentShift = 32 - sshift; segmentMask = ssize - 1; this.segments = Segment.newArray(ssize);//初始化segments数组,ssize表示segment数组的长度
2.初始化segmentShift和segmentMask
segmentShift和segmentMask这两个全局变量的主要作用是用来定位Segment,int j =(hash >>> segmentShift) & segmentMask。
这两个全局变量需要在定位segment时的散列算法里使用,sshift等于ssize从1向左移位的次数,在默认情况下concurrencyLevel等于16,1需要向左移位移动4次,所以sshift等于4。segmentShift用于定位参与散列运算的位数,segmentShift等于32减sshift,所以等于28,这里之所以用32是因为ConcurrentHashMap里的hash()方法输出的最大数是32位的,后面的测试中我们可以看到这点。segmentMask是散列运算的掩码,等于ssize减1,即15,掩码的二进制各个位的值都是1。因为ssize的最大长度是65536,所以segmentShift最大值是16,segmentMask最大值是65535,对应的二进制是16位,每个位都是1。
关于segmentShift和segmentMask
segmentMask:段掩码,假如segments数组长度为16,则段掩码为16-1=15;segments长度为32,段掩码为32-1=31。这样得到的所有bit位都为1,可以更好地保证散列的均匀性
segmentShift:2的sshift次方等于ssize,segmentShift=32-sshift。若segments长度为16,segmentShift=32-4=28;若segments长度为32,segmentShift=32-5=27。而计算得出的hash值最大为32位,无符号右移segmentShift,则意味着只保留高几位(其余位是没用的),然后与段掩码segmentMask位运算来定位Segment。
if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; int c = initialCapacity / ssize; //ssize=5 initialCapacity=10 if (c * ssize < initialCapacity) ++c; //7 int cap = 1; while (cap < c) cap <<= 1; //8 for (int i = 0; i < this.segments.length; ++i) this.segments[i] = new Segment<K,V>(cap, loadFactor); //(8,0.75)
public V put(K key, V value) { Segment<K,V> s; //concurrentHashMap不允许key/value为空 if (value == null) throw new NullPointerException(); //hash函数对key的hashCode重新散列,避免差劲的不合理的hashcode,保证散列均匀 int hash = hash(key); //返回的hash值无符号右移segmentShift位与段掩码进行位运算,定位segment int j = (hash >>> segmentShift) & segmentMask; if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck (segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment s = ensureSegment(j); return s.put(key, hash, value, false); }
从源码看出,put的主要逻辑也就两步:1.定位segment并确保定位的Segment已初始化 2.调用Segment的put方法。
V put(K key, int hash, V value, boolean onlyIfAbsent) { lock(); try { int c = count; if (c++ > threshold) // 如果Segment中元素的数量超过了阈值(由构造函数中的loadFactor算出)这需要进行对Segment扩容,并且要进行rehash, rehash(); HashEntry<K,V>[] tab = table; int index = hash & (tab.length - 1); HashEntry<K,V> first = tab[index];//getFirst的过程,确定链表头部的位置 HashEntry<K,V> e = first; //在链表中寻找和要put的元素相同key的元素,如果找到,就直接覆盖key的value,如果没有找到,则进入**行这里,生成一个新的HashEntry并且把它加到整个Segment的头部,然后再更新count的值。 while (e != null && (e.hash != hash || !key.equals(e.key))) e = e.next; V oldValue; if (e != null) { oldValue = e.value; if (!onlyIfAbsent) e.value = value; } ** else { oldValue = null; ++modCount; tab[index] = new HashEntry<K,V>(key, hash, first, value); count = c; // write-volatile } return oldValue; } finally { unlock(); } }
(3)对于ConcurrentHashMap的数据插入,这里要进行两次Hash去定位数据的存储位置。
|
1
|
static
class
Segment<K,V>
extends
ReentrantLock
implements
Serializable {
|
从上Segment的继承体系可以看出,Segment实现了ReentrantLock,也就带有锁的功能,当执行put操作时,会进行第一次key的hash来定位Segment的位置,如果该Segment还没有初始化,即通过CAS操作进行初始化,然后进行第二次hash操作,找到相应的HashEntry的位置,这里会利用继承过来的锁的特性,在将数据插入指定的HashEntry位置时(链表的尾端),会通过继承ReentrantLock的tryLock()方法尝试去获取锁,如果获取成功就直接插入相应的位置,如果已经有线程获取该Segment的锁,那当前线程会以自旋的方式去继续的调用tryLock()方法去获取锁,超过指定次数就挂起,等待唤醒。
get操作
ConcurrentHashMap的get操作跟HashMap类似,只是ConcurrentHashMap第一次需要经过一次hash定位到Segment的位置,然后再hash定位到指定的HashEntry,遍历该HashEntry下的链表进行对比,成功就返回,不成功就返回null。
1.8版本的ConcurrentHashMap
1、ConcurrentHashMap原理
在ConcurrentHashMap中通过一个Node<K,V>[]数组来保存添加到map中的键值对,而在同一个数组位置是通过链表和红黑树的形式来保存的。但是这个数组只有在第一次添加元素的时候才会初始化,在刚开始建立时只是初始化一个ConcurrentHashMap对象的话,只是设定了一个sizeCtl变量,这个变量用来判断对象的一些状态和是否需要扩容,后面会详细解释。
第一次添加元素的时候,默认初期长度为16,当往map中继续添加元素的时候,通过hash值跟table数组长度取与运算来决定要放在数组的哪个位置,如果出现放在同一个位置的时候,优先以链表的形式存放,在同一个位置的个数又达到了8个以上,如果table数组的长度还小于64的时候,则会扩容数组。如果table数组的长度大于等于64了的话,在会将该节点的链表转换成树。
通过扩容数组的方式来把这些节点给分散开。然后将这些元素复制到扩容后的新的数组中,同一个链表中的元素通过hash值的数组长度位来区分,是还是放在原来的位置还是放到扩容的长度的相同位置去 。在扩容完成之后,如果某个节点的是树,同时现在该节点的个数又小于等于6个了,则会将该树转为链表。
取元素的时候,相对来说比较简单,通过计算hash来确定该元素在数组的哪个位置,然后在通过遍历链表或树来判断key和key的hash,取出value值。
往ConcurrentHashMap中添加元素的时候,往哪个位置添加,则锁住哪个位置,ConcurrentHashMap里面的数据以数组的形式存放的样子大概是这样的:
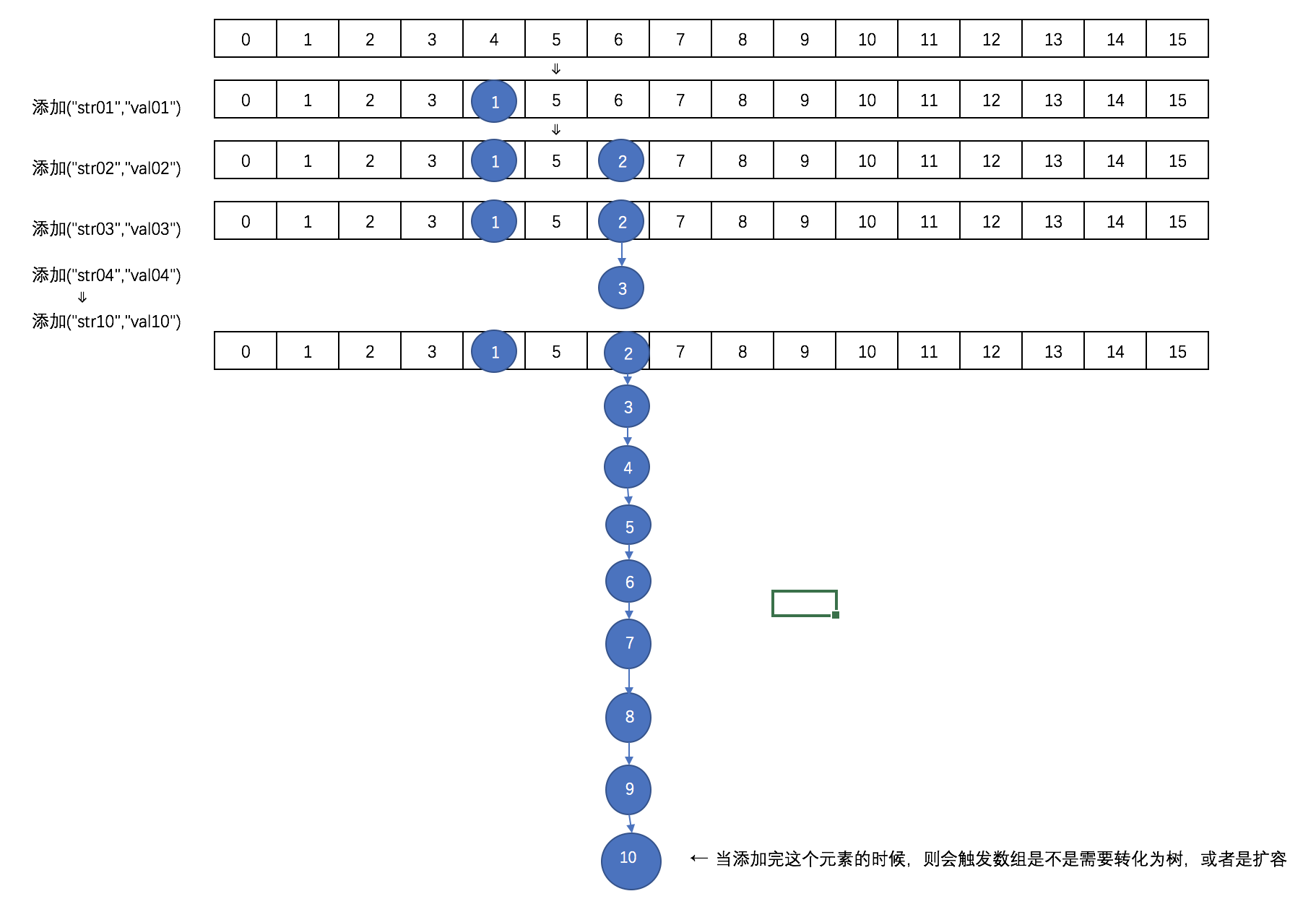
这个时候因为数组的长度才为16,则不会转化为树,而是会进行扩容。
扩容后数组大概是这样的:
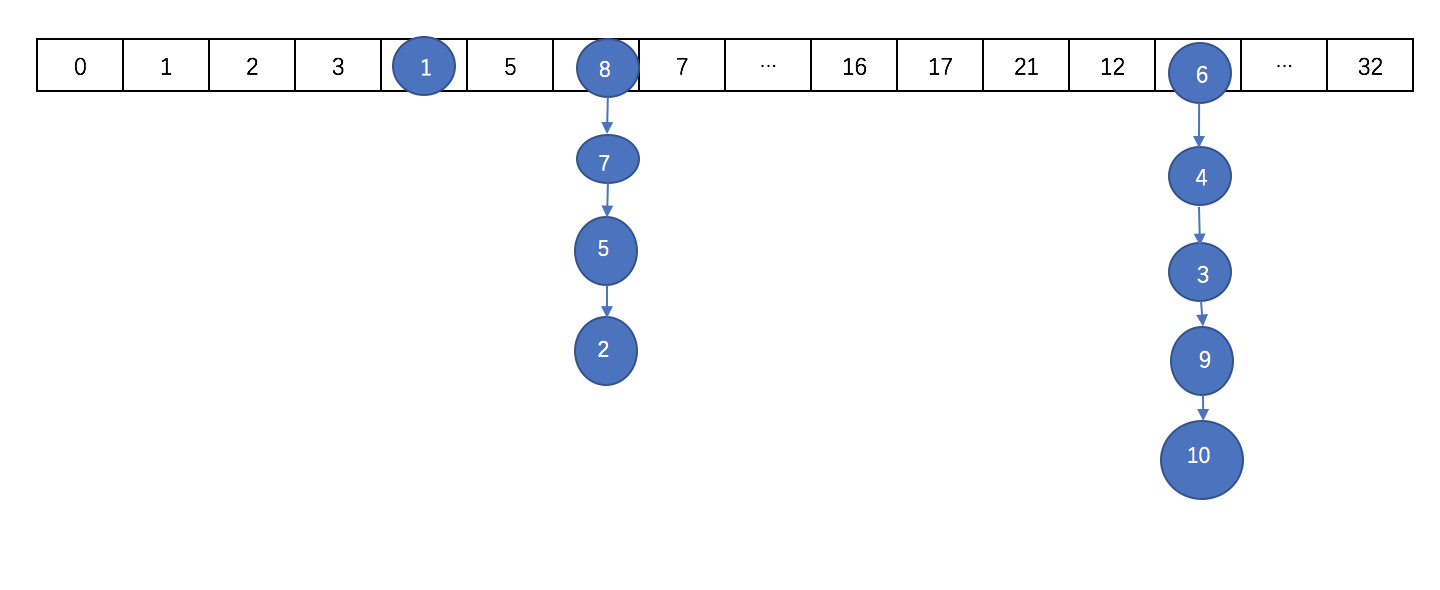
需要注意的是,扩容之后的长度不是32,扩容后的长度在后面细说。
如果数组扩张后长度达到64了,且继续在某个节点的后面添加元素达到8个以上的时候,则会出现转化为红黑树的情况。
转化之后大概是这样:
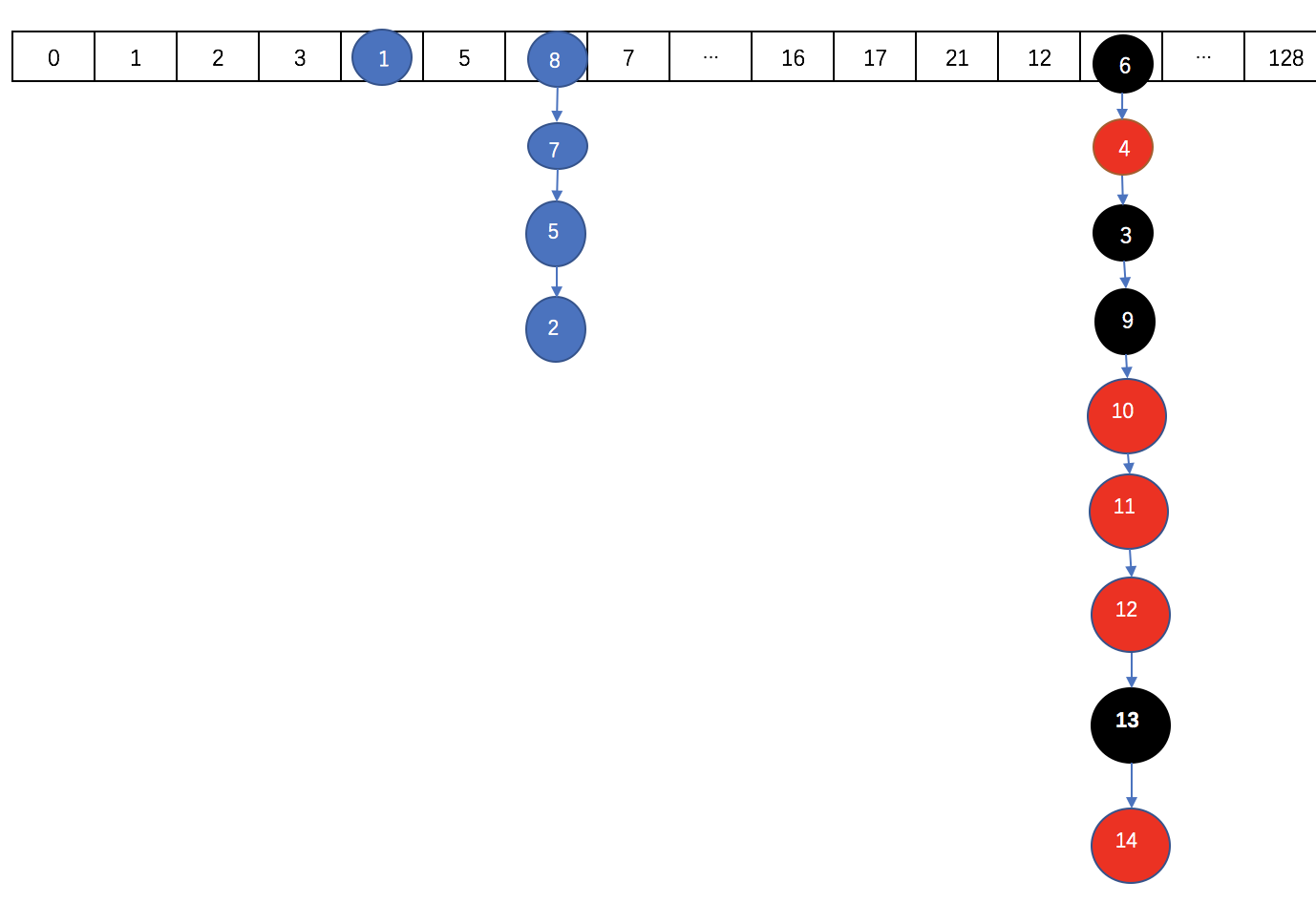
2.ConcurrentHashMap的初始化
public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {//initialCapacity是segment数组的大小,loadFactor是加载因子,concurrentLevel是segment元素的个数 if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)throw new IllegalArgumentException(); if (initialCapacity < concurrencyLevel) initialCapacity = concurrencyLevel; long size = (long)(1.0 + (long)initialCapacity / loadFactor); int cap = (size >= (long)MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : tableSizeFor((int)size); this.sizeCtl = cap; }
private static final int tableSizeFor(int c) {
int n = c - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
可以看到,在任何一个构造方法中,都没有对存储Map元素Node类型的table变量进行初始化。而是在第一次put操作的时候在进行初始化。
初始化数组:
/** * 初始化数组table, * 如果sizeCtl小于0,说明别的数组正在进行初始化,则让出执行权 * 如果sizeCtl大于0的话,则初始化一个大小为sizeCtl的数组 * 否则的话初始化一个默认大小(16)的数组 * 然后设置sizeCtl的值为数组长度的3/4 */ private final Node<K,V>[] initTable() { Node<K,V>[] tab;
int sc; while ((tab = table) == null || tab.length == 0) { //第一次put的时候,table还没被初始化,进入while if ((sc = sizeCtl) < 0) //sizeCtl初始值为0,当小于0的时候表示在别的线程在初始化表或扩展表 Thread.yield(); // lost initialization race; just spin else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) { //SIZECTL:表示当前对象的内存偏移量,sc表示期望值,-1表示要替换的值,设定为-1表示要初始化表了 try { if ((tab = table) == null || tab.length == 0) { int n = (sc > 0) ? sc : DEFAULT_CAPACITY; //指定了大小的时候就创建指定大小的Node数组,否则创建指定大小(16)的Node数组 @SuppressWarnings("unchecked") Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n]; table = tab = nt; sc = n - (n >>> 2); } } finally { sizeCtl = sc; //初始化后,sizeCtl长度为数组长度的3/4 } break; } } return tab; }
3、ConcurrentHashMap的put操作详解
下面看看put方法的源码
/* * 单纯的额调用putVal方法,并且putVal的第三个参数设置为false * 当设置为false的时候表示这个value一定会设置 * true的时候,只有当这个key的value为空的时候才会设置 */ public V put(K key, V value) { return putVal(key, value, false); }
再来看putVal
/* * 当添加一对键值对的时候,首先会去判断保存这些键值对的table数组是不是初始化了, * 如果没有就先进初始化数组 * 然后通过计算hash值来确定放在table数组的哪个位置 * 如果这个位置为空则直接添加,如果不为空的话,则取出这个节点来 * 如果取出来的节点的hash值是MOVED(-1)的话,则表示当前正在对这个数组进行扩容,复制到新的数组,则当前线程也去帮助复制 * 最后一种情况就是,如果这个节点,不为空,也不在扩容,则通过synchronized来加锁,进行添加操作 * 然后判断当前取出的节点位置存放的是链表还是树 * 如果是链表的话,则遍历整个链表,直到取出来的节点的key来个要放的key进行比较,如果key相等,并且key的hash值也相等的话, * 则说明是同一个key,则覆盖掉value,否则的话则添加到链表的末尾 * 如果是树的话,则调用putTreeVal方法把这个元素添加到树中去 * 最后在添加完成之后,会判断在该节点处共有多少个节点(注意是添加前的个数),如果达到8个以上了的话, * 则调用treeifyBin方法来尝试将处的链表转为树,或者扩容数组,注意只有在桶数达到64时才会扩容成功 */ final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException();//K,V都不能为空,否则的话跑出异常 int hash = spread(key.hashCode()); //取得key的hash值 int binCount = 0; //用来计算在这个节点总共有多少个元素,用来控制扩容或者转移为树 for (Node<K,V>[] tab = table;;) { //1 Node<K,V> f; int n, i, fh; if (tab == null || (n = tab.length) == 0) //判断该table数组是否被初始化过 tab = initTable(); //第一次put的时候table没有初始化,则调用initTable()方法初始化table else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { //通过哈希计算出一个表中的位置因为n是数组的长度,所以(n-1)&hash肯定不会出现数组越界 /* *f记录的是这个位置的元素,如果这个位置没有元素的话,则通过cas的方式尝试添加,注意这个时候是没有加锁的 */ if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))//创建一个Node添加到数组中,null表示的是下一个节点为空 break; // }else if ((fh = f.hash) == MOVED) /* 能走到这一步说明该位置不为空 * 如果检测到该位置节点的hash值是MOVED,则表示正在进行数组扩张的数据复制阶段, * 则当前线程也会参与去复制,通过允许多线程复制的功能,一次来减少数组的复制所带来的性能损失 */ tab = helpTransfer(tab, f); else {//2 /* 走到这一步就说明这个位置有元素,且数组没有在进行扩容 * 这时候就采用synchronized的方式加锁 * 如果是链表的话(hash大于0),就对这个链表的所有元素进行遍历, * 如果找到了key和key的hash值都一样的节点,则把它的值替换掉 * 如果没找到的话,则添加在链表的最后面 * 否则,是树的话,则调用putTreeVal方法添加到树中去 * * 在添加完之后,会对该节点上关联的的数目进行判断, * 如果在8个以上的话,则会调用treeifyBin方法,来尝试转化为树,或者是扩容 */ V oldVal = null; synchronized (f) {//往哪个位置存,则锁住哪个位置 if (tabAt(tab, i) == f) { //再次取出要存储的位置的元素,跟前面取出来的比较 if (fh >= 0) { //取出来的元素的hash值大于0,当转换为树之后,hash值为-2 binCount = 1; for (Node<K,V> e = f;; ++binCount) {//遍历这个链表 K ek; if (e.hash == hash&&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {//要存的元素的hash,key跟要存储的位置的节点的相同的时候,替换掉该节点的value即可 oldVal = e.val; if (!onlyIfAbsent) //当使用putIfAbsent的时候,只有在这个key没有设置值得时候才设置 e.val = value; break; } Node<K,V> pred = e; if ((e = e.next) == null) { //如果不是同样的hash,同样的key的时候,则判断该节点的下一个节点是否为空,不为空接着循环,遍历这个链表 pred.next = new Node<K,V>(hash,key,value, null); //为空的话把这个要加入的节点设置为当前节点的下一个节点 break; } }//for }else if (f instanceof TreeBin) { //表示已经转化成红黑树类型了 Node<K,V> p; binCount = 2; if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, //调用putTreeVal方法,将该元素添加到树中去 value)) != null) { oldVal = p.val; if (!onlyIfAbsent)p.val = value; } } }//if (tabAt(tab, i) == f) }// synchronized (f) if (binCount != 0) { if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i); //当在同一个节点的数目达到8个的时候,则扩张数组或将给节点的数据转为tree if (oldVal != null) return oldVal; break; } }//2 }//1 addCount(1L, binCount); //计数 return null; }
put操作
对于ConcurrentHashMap的数据插入,这里要进行两次Hash去定位数据的存储位置
|
1
|
static
class
Segment<K,V>
extends
ReentrantLock
implements
Serializable {
|
从上Segment的继承体系可以看出,Segment实现了ReentrantLock,也就带有锁的功能,当执行put操作时,会进行第一次key的hash来定位Segment的位置,如果该Segment还没有初始化,即通过CAS操作进行赋值,然后进行第二次hash操作,找到相应的HashEntry的位置,这里会利用继承过来的锁的特性,在将数据插入指定的HashEntry位置时(链表的尾端),会通过继承ReentrantLock的tryLock()方法尝试去获取锁,如果获取成功就直接插入相应的位置,如果已经有线程获取该Segment的锁,那当前线程会以自旋的方式去继续的调用tryLock()方法去获取锁,超过指定次数就挂起,等待唤醒
get操作
ConcurrentHashMap的get操作跟HashMap类似,只是ConcurrentHashMap第一次需要经过一次hash定位到Segment的位置,然后再hash定位到指定的HashEntry,遍历该HashEntry下的链表进行对比,成功就返回,不成功就返回null
size操作
计算ConcurrentHashMap的元素大小是一个有趣的问题,因为他是并发操作的,就是在你计算size的时候,他还在并发的插入数据,可能会导致你计算出来的size和你实际的size有相差(在你return size的时候,插入了多个数据),要解决这个问题,JDK1.7版本用两种方案
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
try
{
for
(;;) {
if
(retries++ == RETRIES_BEFORE_LOCK) {
for
(
int
j =
0
; j < segments.length; ++j) ensureSegment(j).lock();
// force creation
}
sum = 0L;
size =
0
;
overflow =
false
;
for
(
int
j =
0
; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if
(seg !=
null
) { sum += seg.modCount;
int
c = seg.count;
if
(c <
0
|| (size += c) <
0
)
overflow =
true
;
} }
if
(sum == last)
break
;
last = sum; } }
finally
{
if
(retries > RETRIES_BEFORE_LOCK) {
for
(
int
j =
0
; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
|
- 第一种方案他会使用不加锁的模式去尝试多次计算ConcurrentHashMap的size,最多三次,比较前后两次计算的结果,结果一致就认为当前没有元素加入,计算的结果是准确的
- 第二种方案是如果第一种方案不符合,他就会给每个Segment加上锁,然后计算ConcurrentHashMap的size返回